How to restore websites from the Web Archive - archive.org. Part 1
Web Archive Interface: Instructions for the Summary, Explore, and Site map tools.
In this article we will talk about the Wayback Machine itself and how it works.
For reference: Archive.org (Wayback Machine - Internet Archive) was created by Brewster Cale in 1996 about at the same time when he founded Alexa Internet, a company that collects statistics on website traffic. In October of that year, company started archiving and storing copies of web pages. But the current form called WAYBACKMACHINE, that we can use now, started only in 2001, although the data has been saved since 1996. Web archive advantage for any website is that it saves not only the html-code of the pages, but also other file types: doc, zip, avi, jpg, pdf, css. A complex of html-codes of all page elements allows you to restore the site in its original form (on a specific indexing date when web archive spider visited the site’s pages).
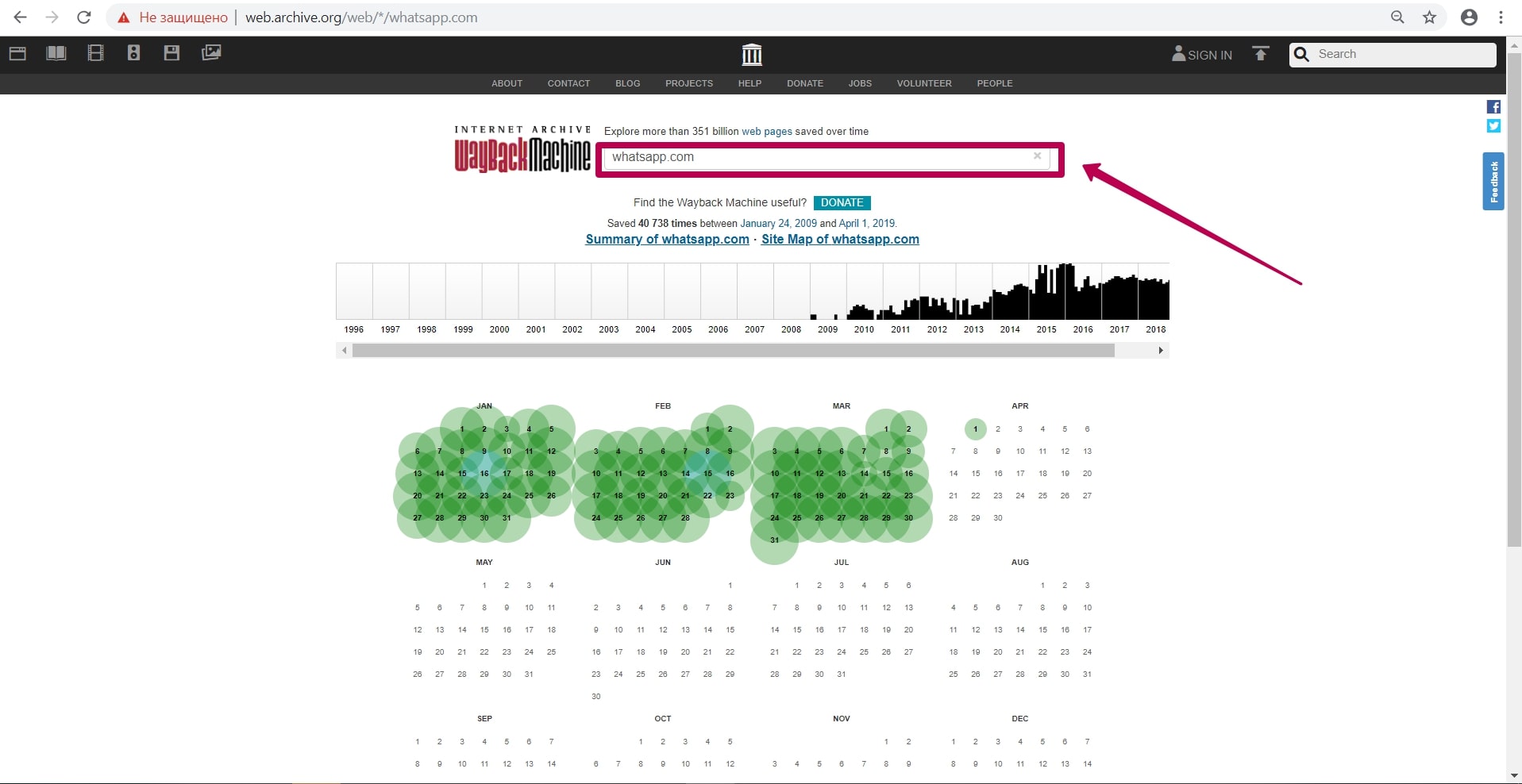
So, archive is located at http://web.archive.org/. Let’s touch on web archive possibilities on the example of a well-known website as WhatsApp.
Enter website domain on the main page in the search field. In our case it will be whatsapp.com.
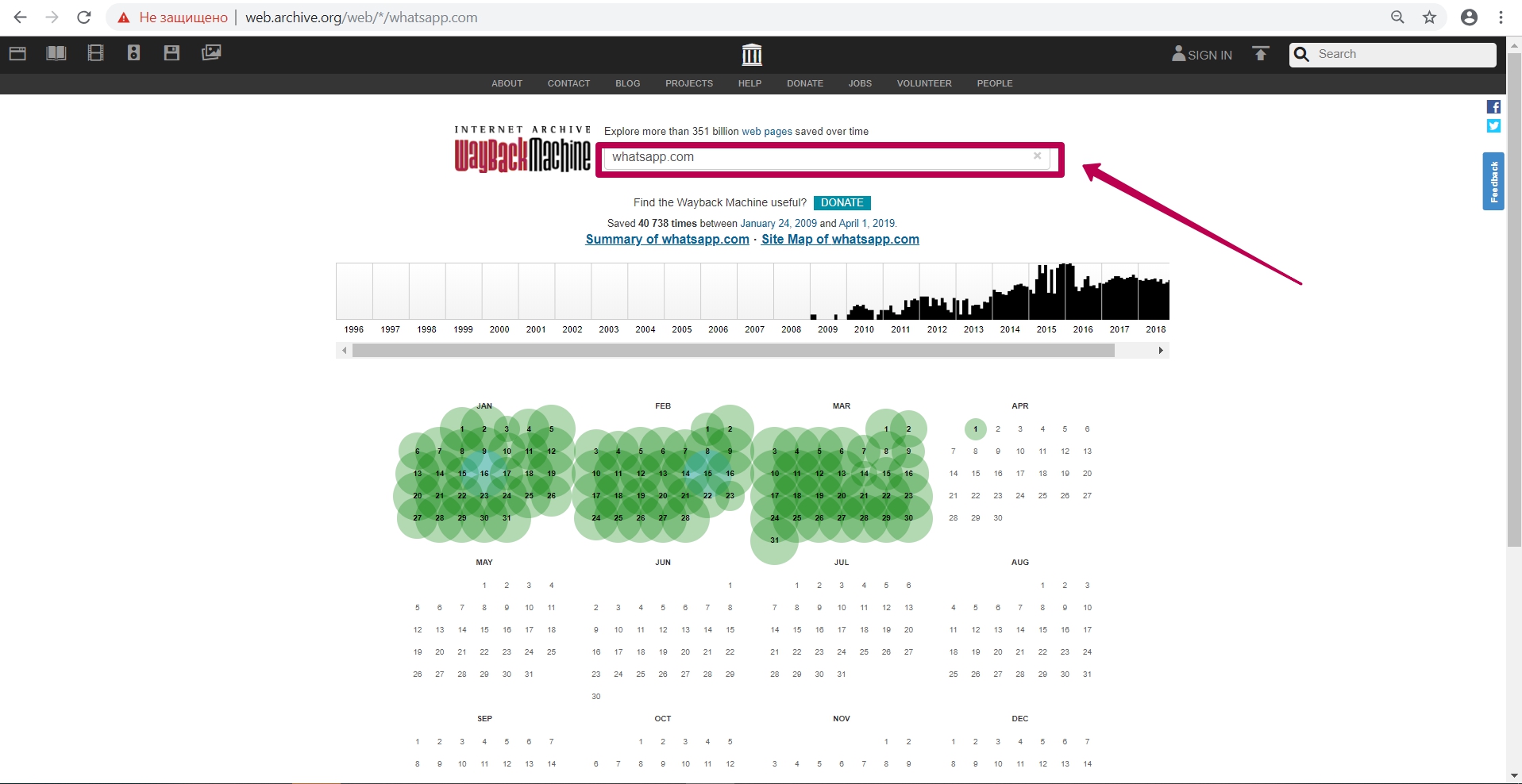
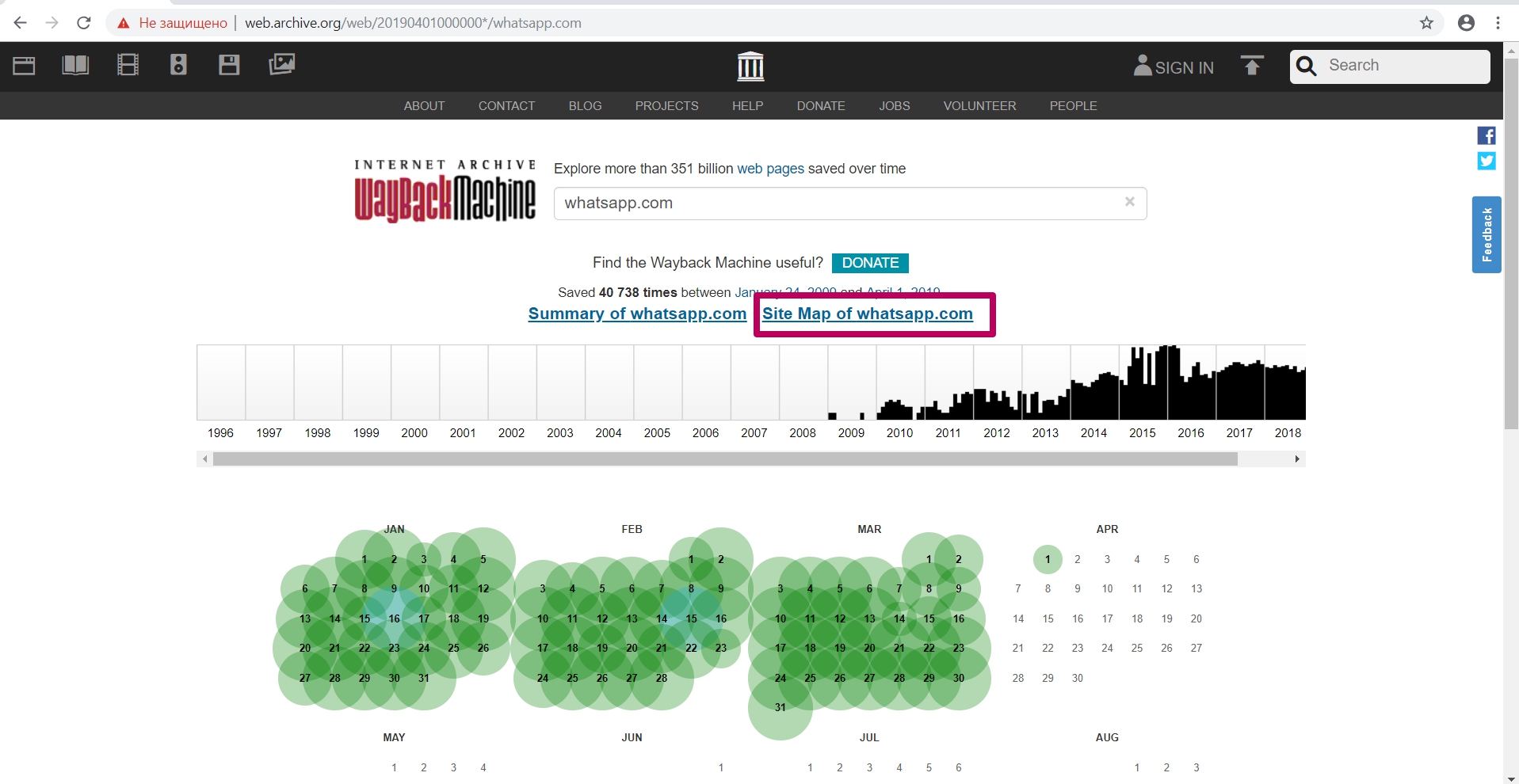
After entering website link, we see the calendar of saving html code of the page. On this calendar, we see notes in different colors on the save dates:
Blues means server valid code 200 response (no errors from the server);
Red (may be yellow or orange, depending on the browser and PC operating system) means 404 or 403 error, something that is not interesting when restoring;
Green stands for pages redirect (301 and 302).
Calendar colors do not give a 100% guarantee of compliance: on the blue date there can a redirect as well (not at the header level, but, for example, in the html code of the page itself: in the refresh meta tags (screen refresh tags) or in JavaScript).
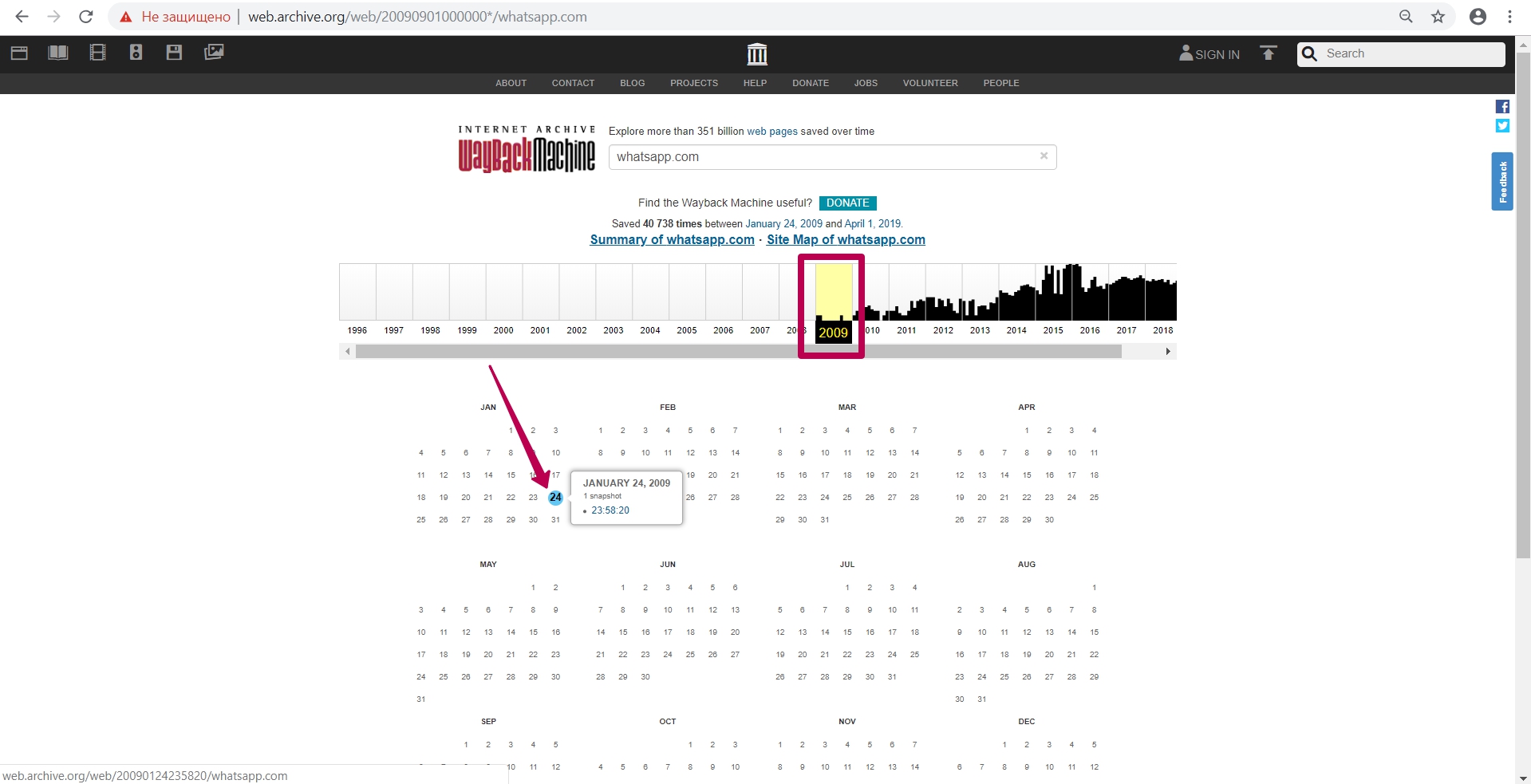
Let’s go to 2009, when this website indexing (saving) started.
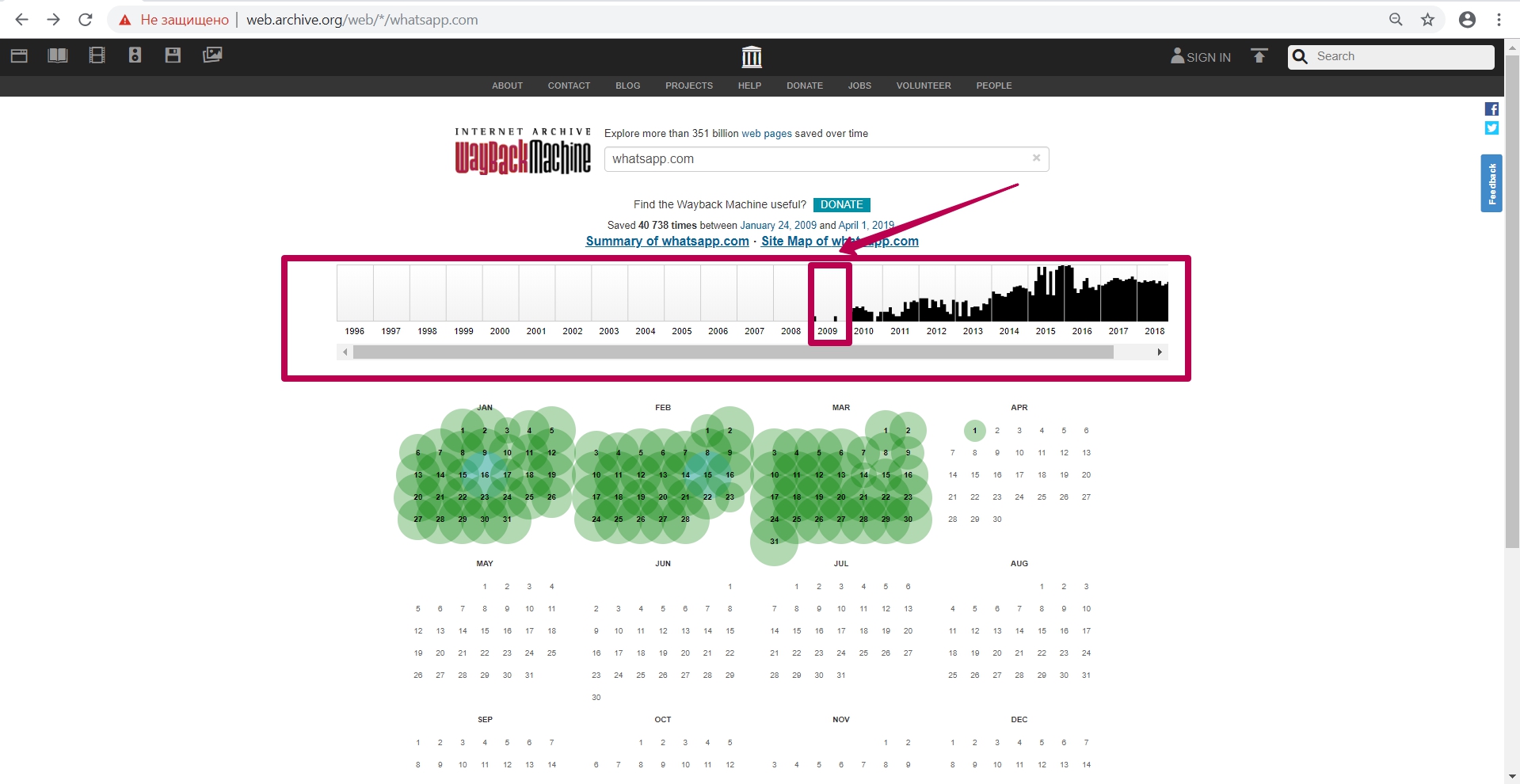
We see the version dated January 24, and then we open it in a new tab (in case of errors during operation, it is better to open the web archive tool in incognito mode or in another browser).
So, we see the 2009 version of the WhatsApp page. In the page url we see the numbers called timestamp, i.e. year, month, day, hour, minute, second, when this url was saved. Timestamp format (YYYYMMDDhhmmss).
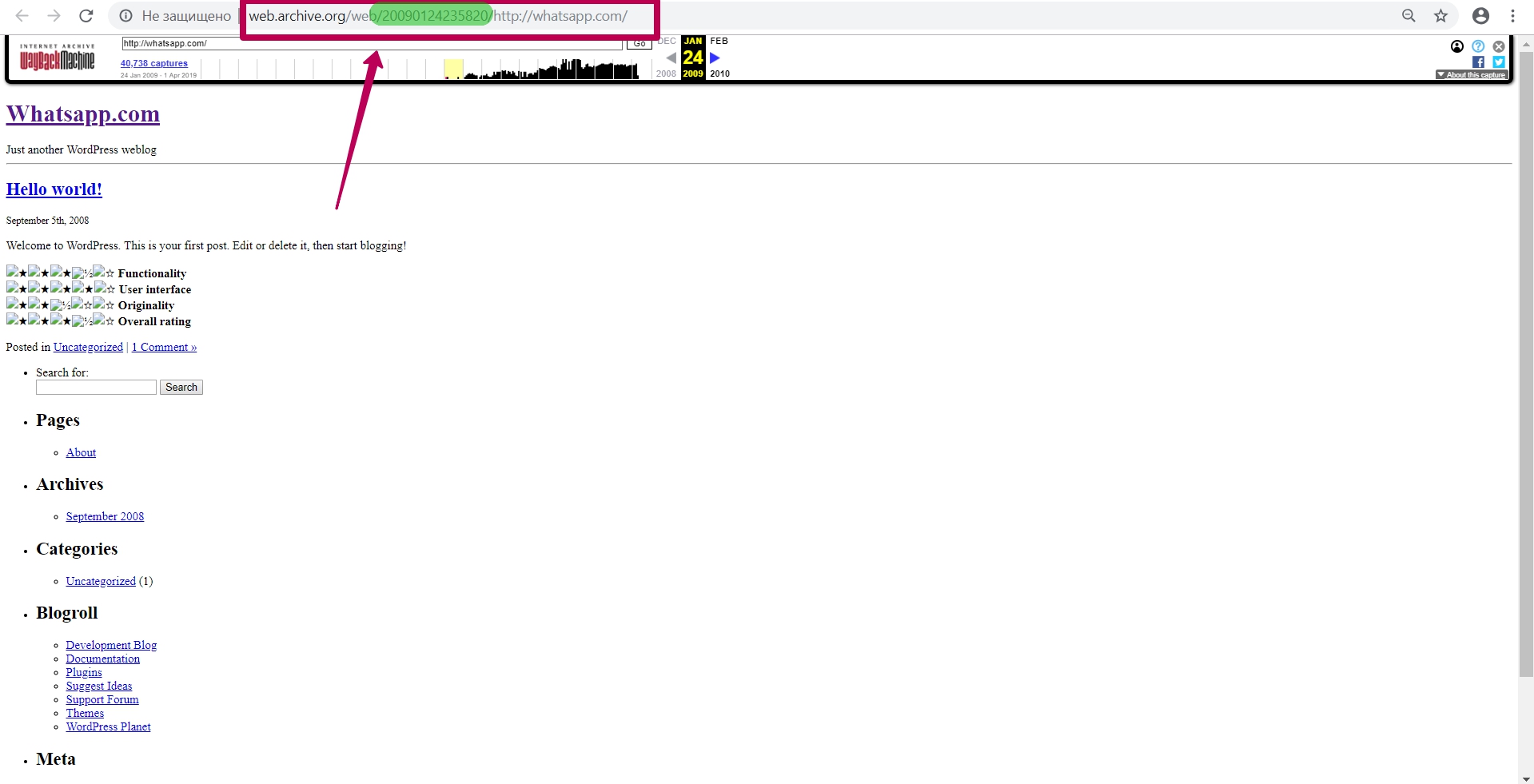
Timestamp is not the time website copy saving, not the time of page saving, but this is the time of specific file saving. This is important to know when restoring content from a web archive. All website elements as pictures, styles, scripts, html code and so on have their own timestamp, that is, archiving date.
In order to return from website page to the calendar, click on the link with captures number (page captures).
Summary tool
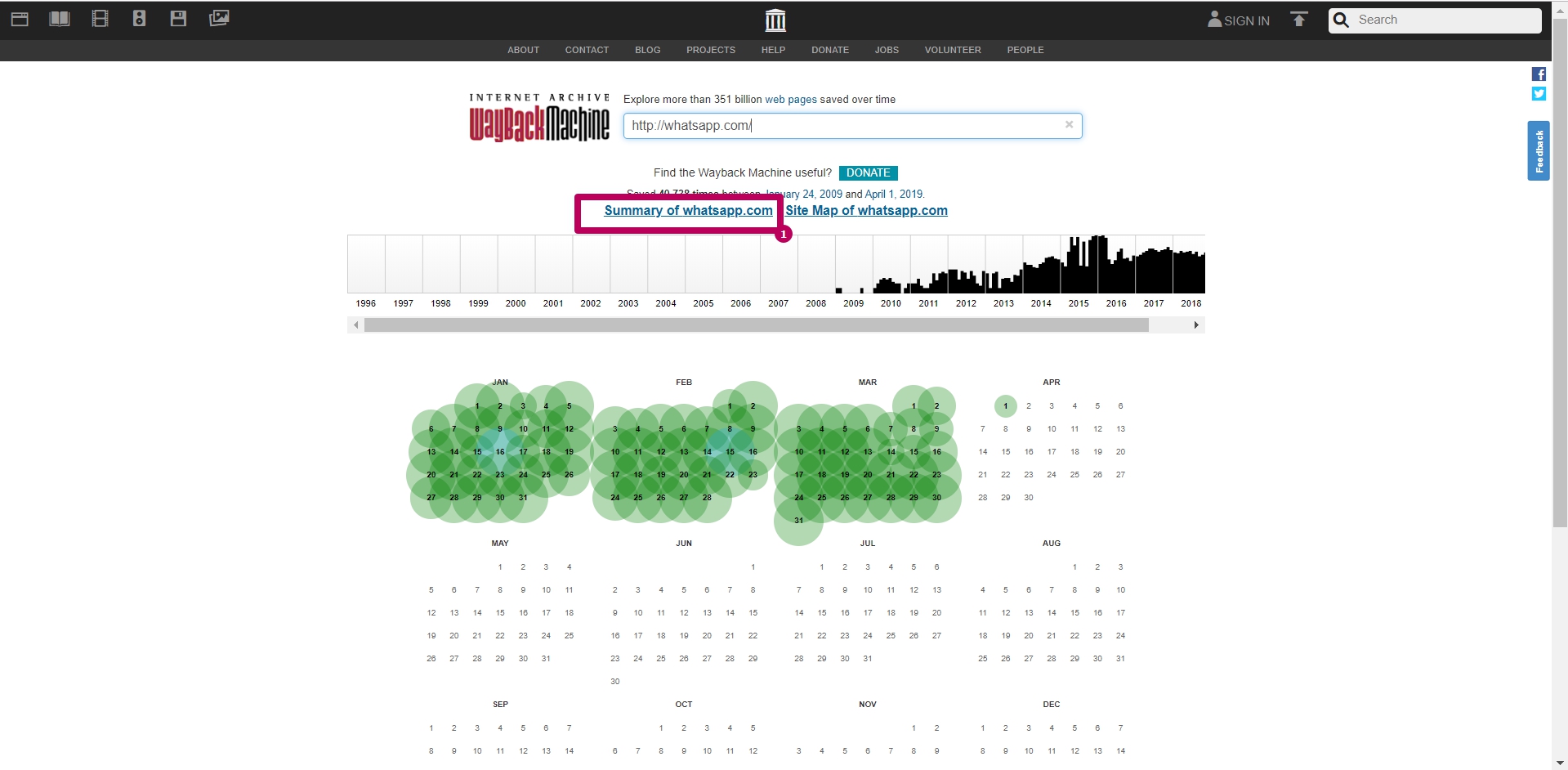
Select Summary tool on web archive main page. These are graphs and charts for website saving. All graphs and tables can be viewed by year.
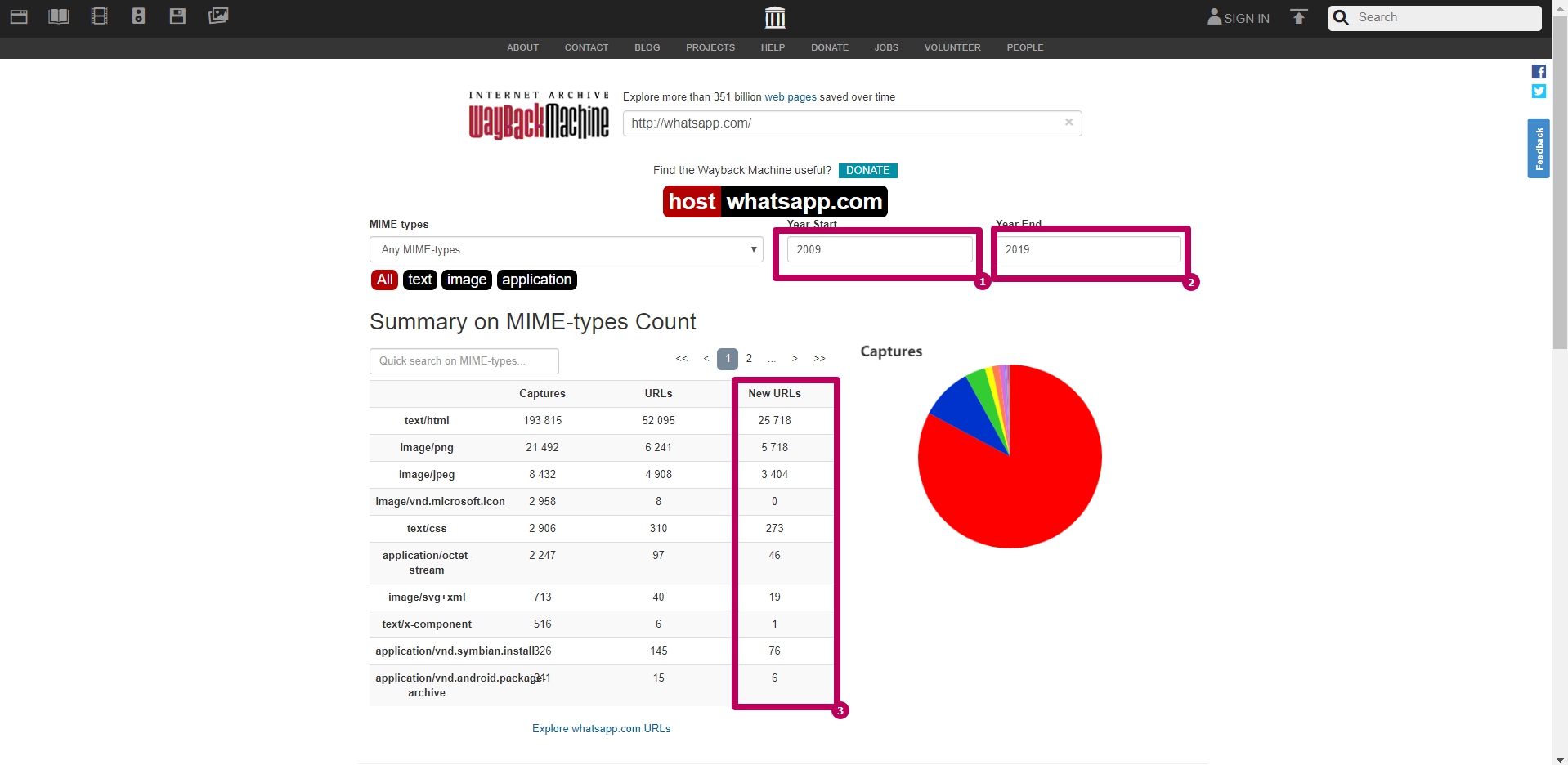
The most useful information on this page is New URLs column sum. This amount shows us the number of unique files contained in web archive.
Due to the reason that web archive itself could index the page with or without www, this number may be approximate. It means that the same page and its elements can be located at different addresses.
Explore tool
![]()
It uploads into the table all the url that were previously indexed by the web archive spider.
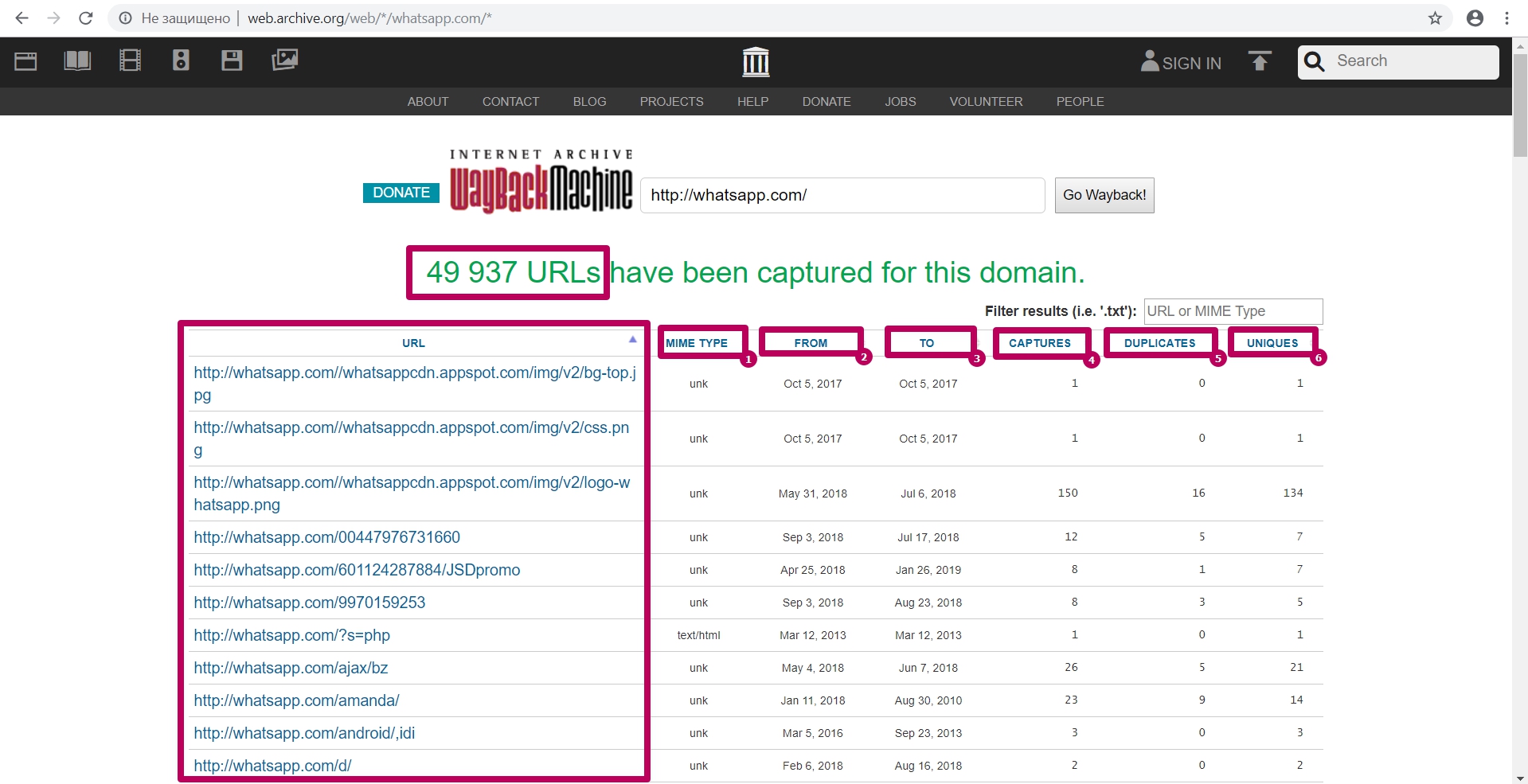
Here you can find:
- MIME element type;
- Initial date of element indexing;
- The last date when element was saved;
- Total number of element captures (savings);
- Number of duplicates;
- Number of unique content savings by url.
You can specify any part of the element you are looking for in a filter field: in order to search for website content that is difficult to detect among large number of links.
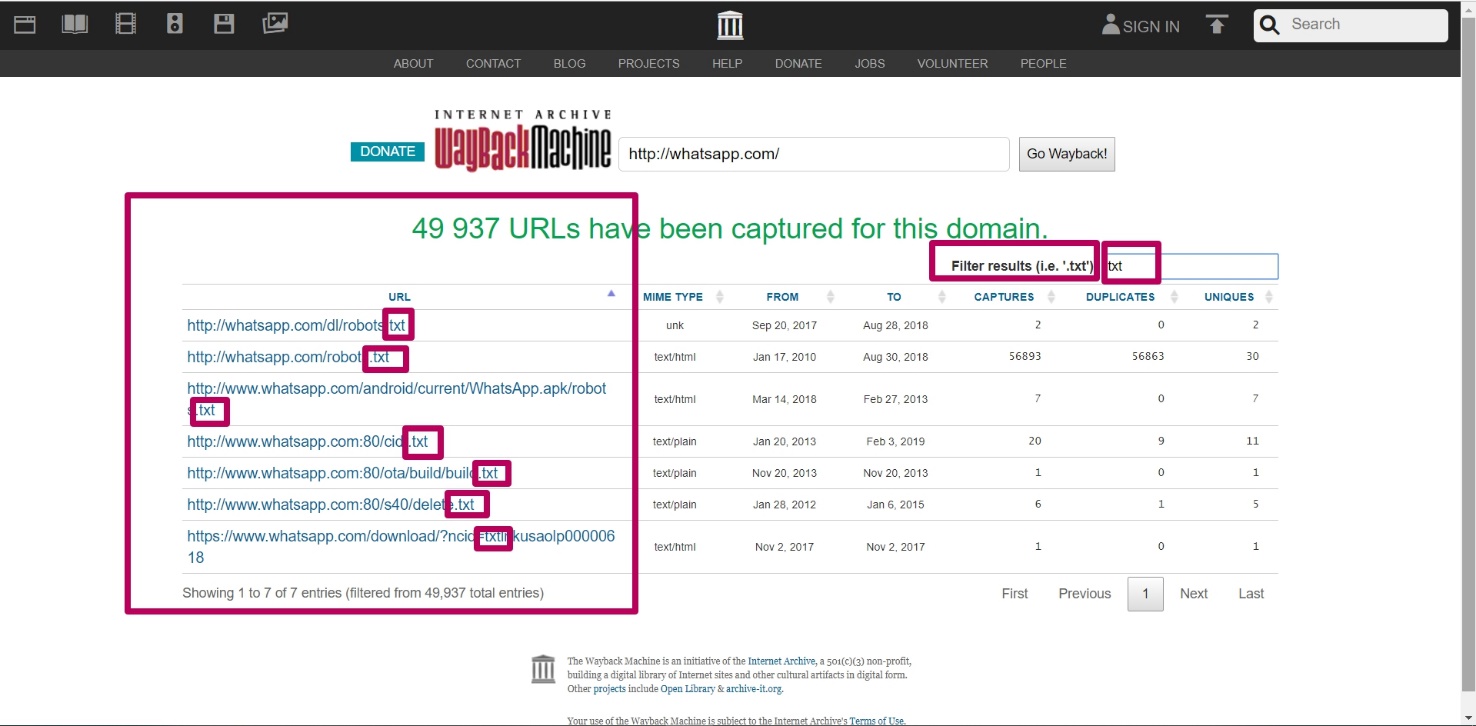
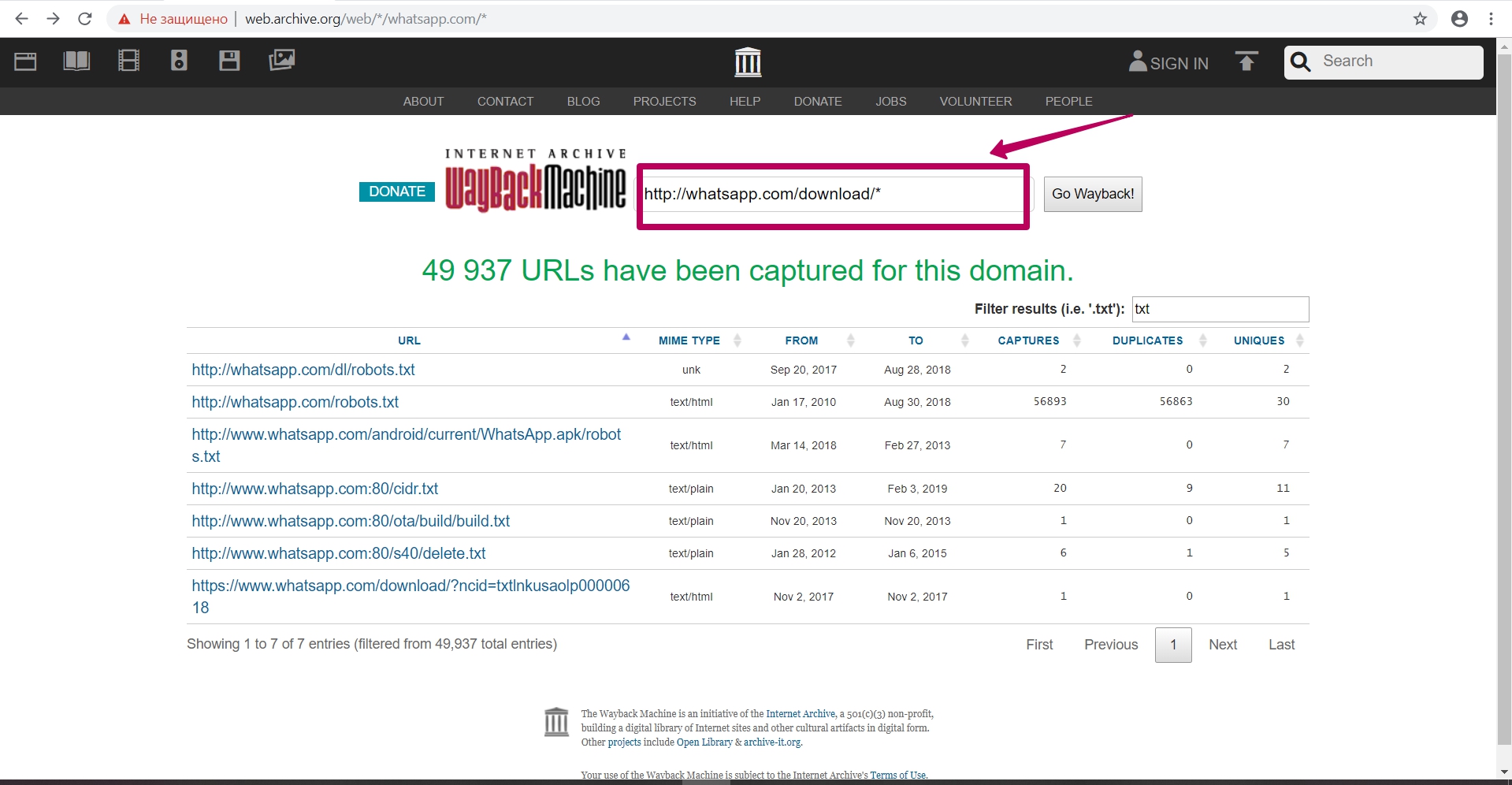
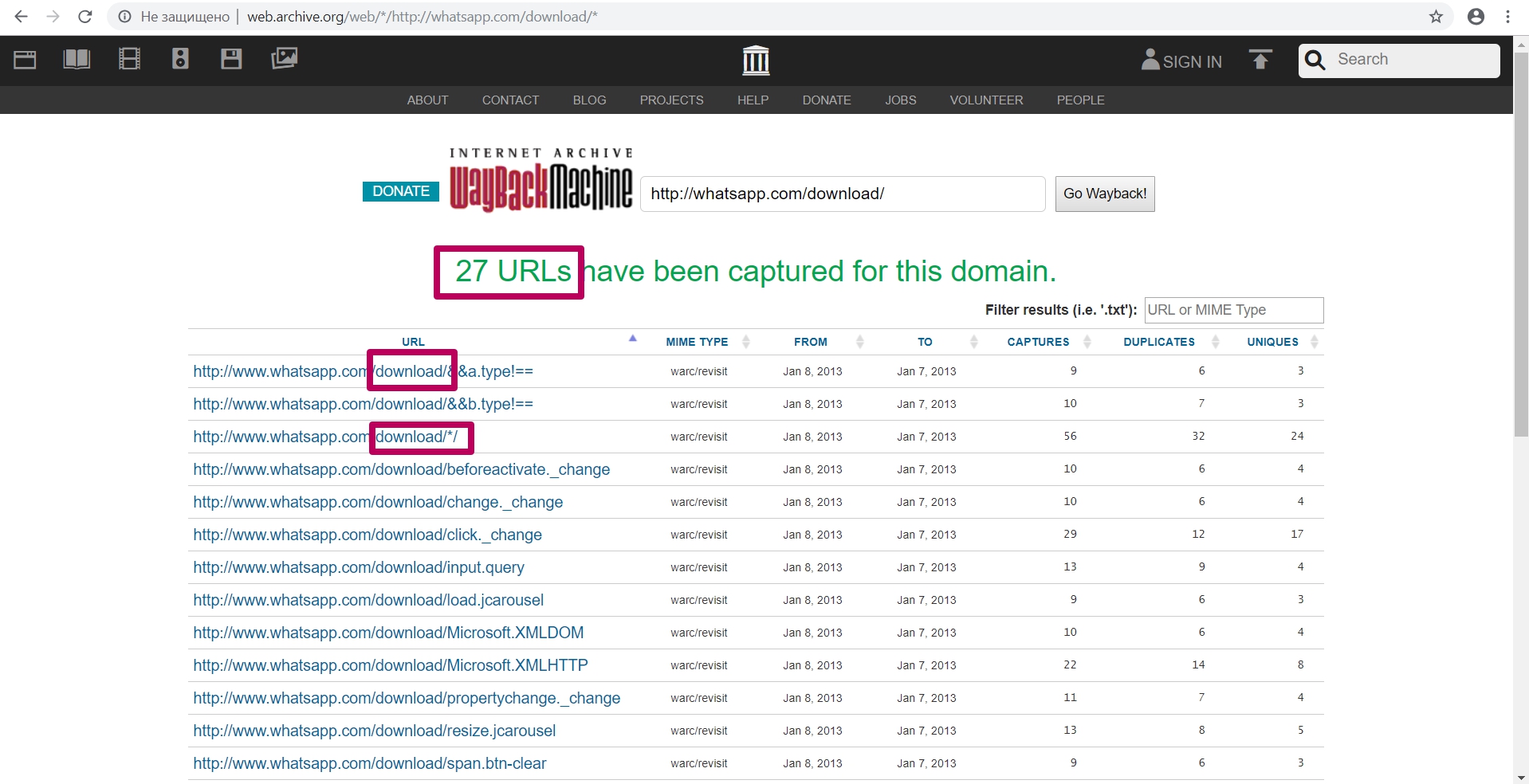
You can enter part of the path, for example, the path to the folder (required with an asterisk), you can see all the url for the given path (all files from the page or folder) to analyze the indexing of this content.
Site Map tool
Click on the appropriate Site Map link on the website main page.
This is a doughnut chart with a separation by year to analyze the elements saved by web archive (which pages) in the context from the main url to the url of the second and n-th level. This tool allows you to determine the year when web archive stopped saving website new content or certain url copies (any response code, except for 200 code).
In the middle of the main page and then along the path structure in the second or third stage, we see website internal pages. There are no other kinds of files, only url saved. It means that we can understand where the archive was able or not to index pages.
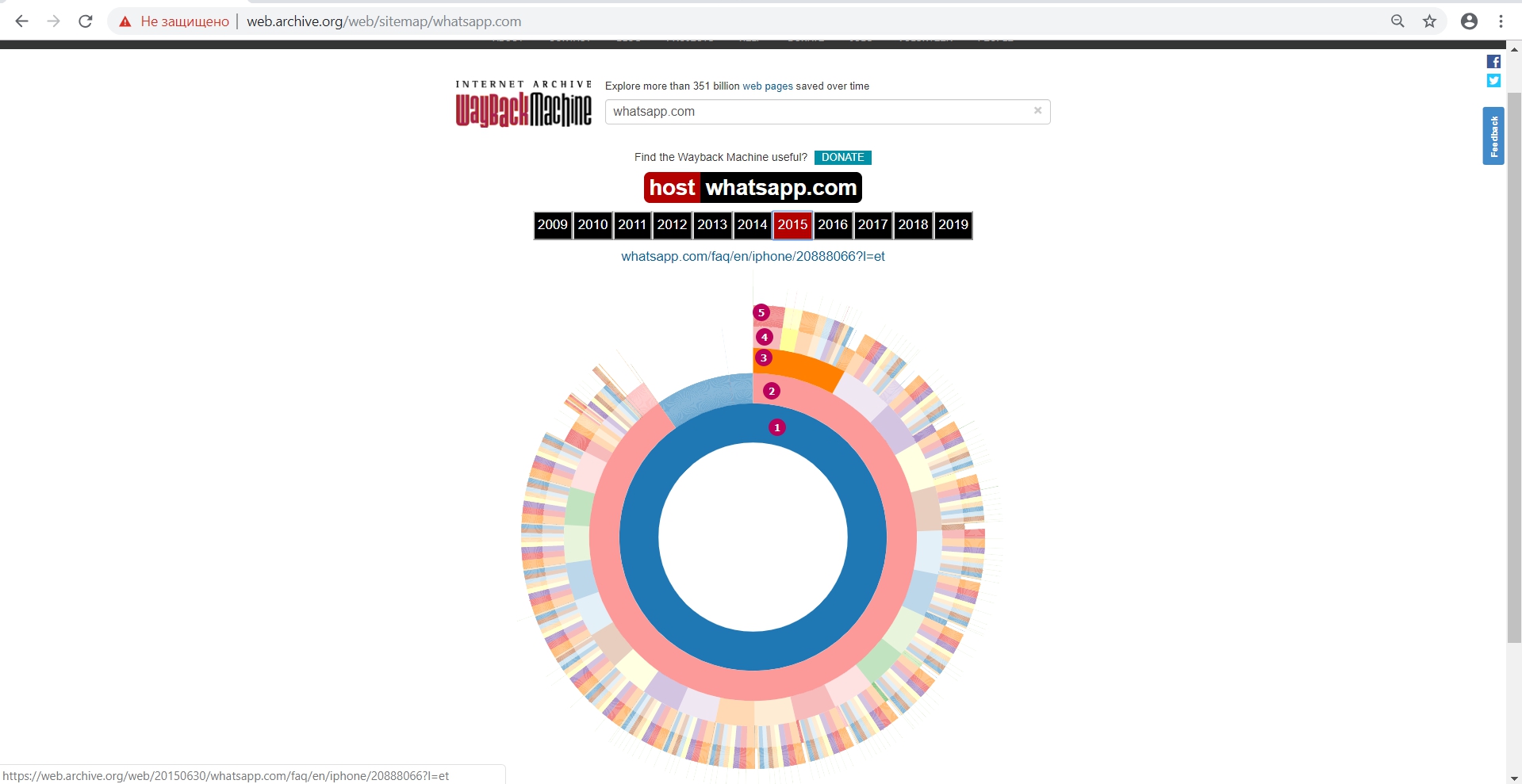
Diagram shows:
- Main page
2 - 5. Website pages nesting levels
In addition, by using this tool we can see the internal pages by structure and open them separately in a new tab.
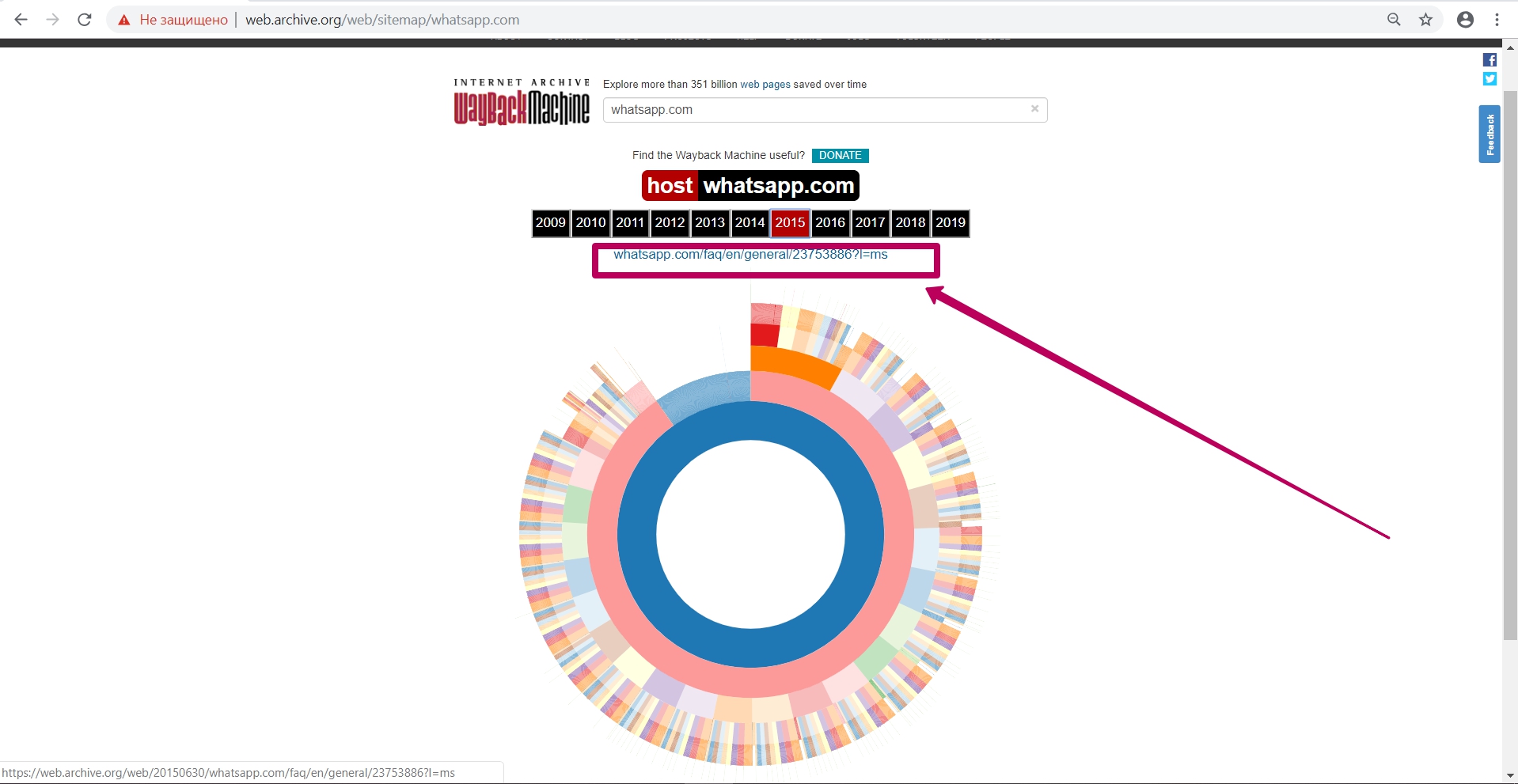
Thus, having selected links to pages and elements with the required date of saving in web archive and having built the structure we need, we can proceed to the next step ― preparing the domain for restoring. But we will talk about this in the next part.
How to restore websites from the Web Archive - archive.org. Part 2
How to restore websites from the Web Archive - archive.org. Part 3
The use of article materials is allowed only if the link to the source is posted: https://archivarix.com/en/blog/1-how-does-it-works-archiveorg/

Web Archive Interface: Instructions for the Summary, Explore, and Site map tools. For reference: Archive.org (Wayback Machine - Internet Archive) was created by Brewster Cale in 1996 about at the same…
In the previous article we examined archive.org operation, and in this article we will talk about a very important stage of site restoring from the Wayback Machine that relates to domain preparation f…
Choosing “BEFORE” limit when restoring websites from archive.org. When domain expires, domain provider or hoster’s parking page may appear. When entering such a page, the Internet Archive will save it…