How to restore websites from the Web Archive - archive.org. Part 2
In the previous article we examined archive.org operation, and in this article we will talk about a very important stage of site restoring from the Wayback Machine that relates to domain preparation for restoring. This step gives confidence that you will restore the maximum content on your site.
All the works described at this stage are connected with robots.txt rules. When archive.org indexes website, it ignores the rules recorded in robots.txt, but it saves the file itself. When looking at archived version through archive.org, it will show you files, designs, pictures that were saved ignoring robots.txt. But when restoring website using the web archive API, these files will not be saved, because the web archive begins to comply with the robots.txt rules that it saved during indexing. But this is not a problem, because web archive only takes into account the latest version of robots.txt and you can create it by yourself.
How to prepare a website for downloading from web archive?
- Buy the domain where website was hosted.
- Configure DNS records on the purchased domain and bind it to the web hosting.
- Create a robots.txt file with the following text:
User-agent: *
Disalow:
And then place it to the website root you want to restore.
- Save robots.txt file with open indexing in the web archive database. It is done as follows:
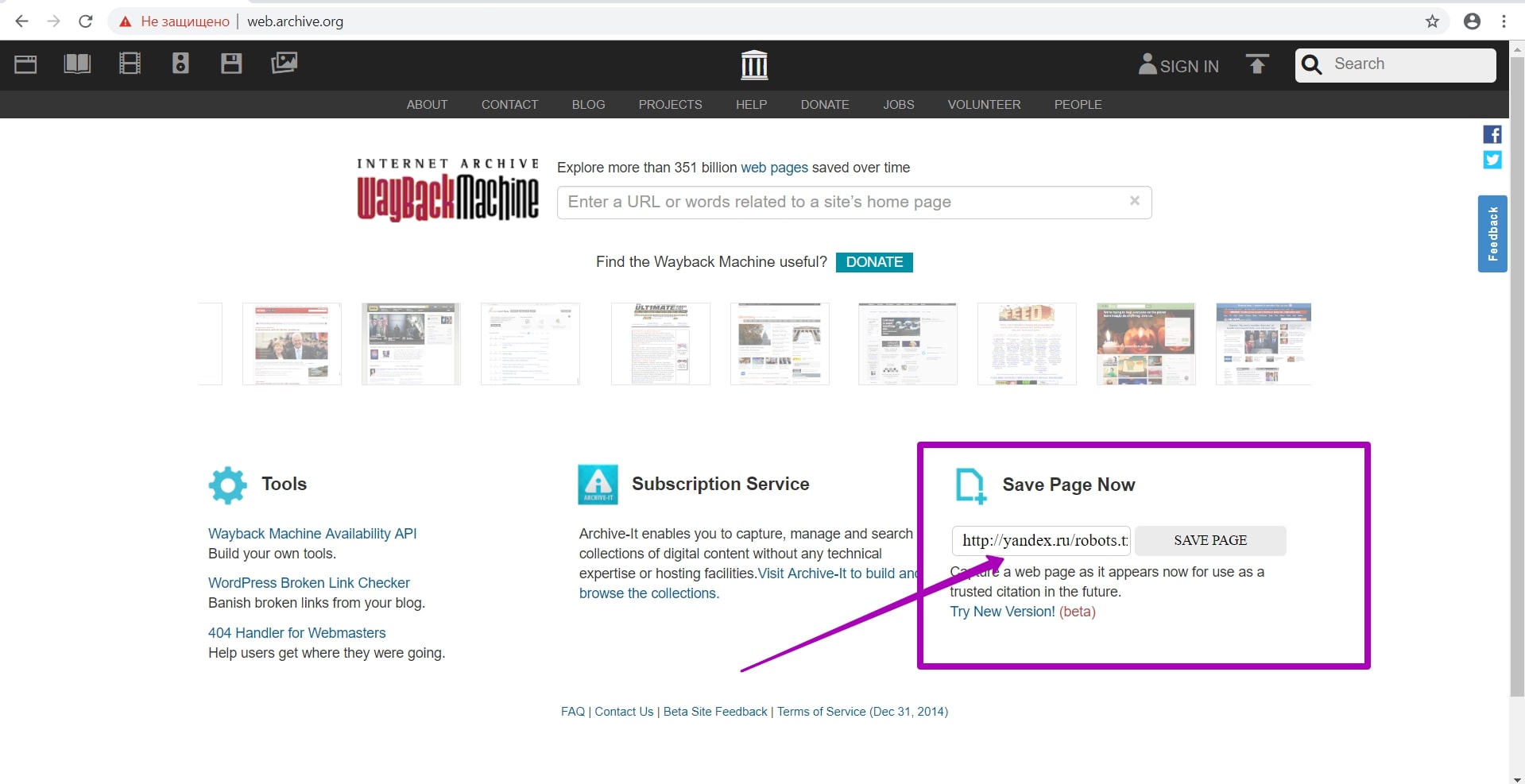
There is a Save Page Now form on the main page of web archive:
Enter full url of the robots.txt file on the new domain in this form. Moreover, protocol for connecting new domain (http or https) doesn’t matter, because robots.txt will be similar. Indexing of the new robots.txt will be applied to all previously saved data, regardless of the past protocol (http or https.). So, save robots.txt by pressing the SAVE PAGE button.
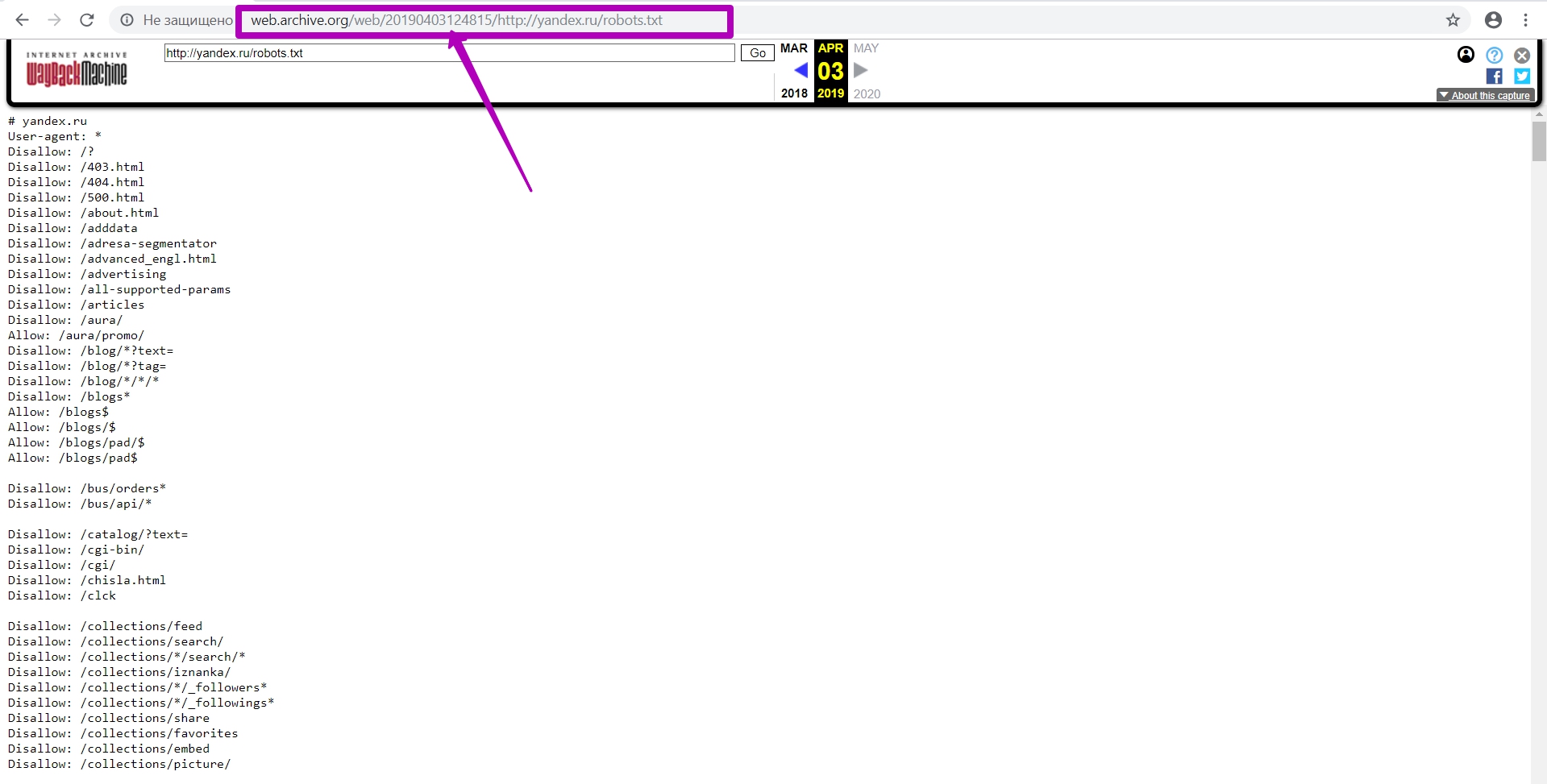
Here we see robots.txt new version on the new domain and hosting, as well as the current timestamp. Please note that this does not happen immediately after you press the SAVE PAGE button. It should take about 24 hours before the new version of robots.txt appears in the web archive. If the file does not open, spits out an error or just a white screen, then just enter incognito mode or use another browser. Is you see a white screen or some errors, then the file has not been saved.
Let’s check indexability. Go to the general calendar, select Summery tool and then go to Explore tool.
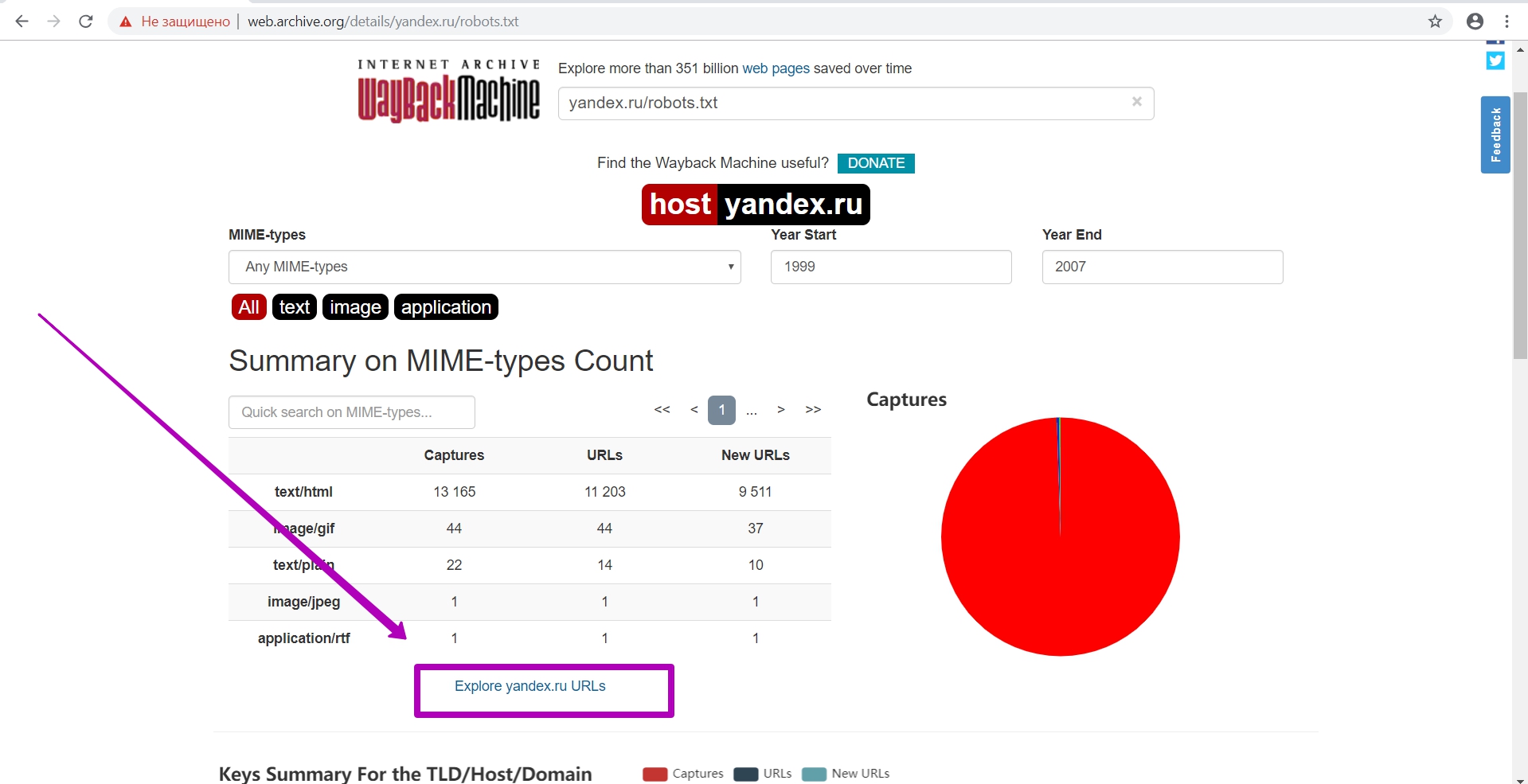
This tool already works with web archive api. Here we can check whether indexing is now open or not. If the data table by file is downloaded, then search robots will index it, otherwise website is closed from indexing (indicated in robots.txt file). If folders are closed partially, their url are closed as well.
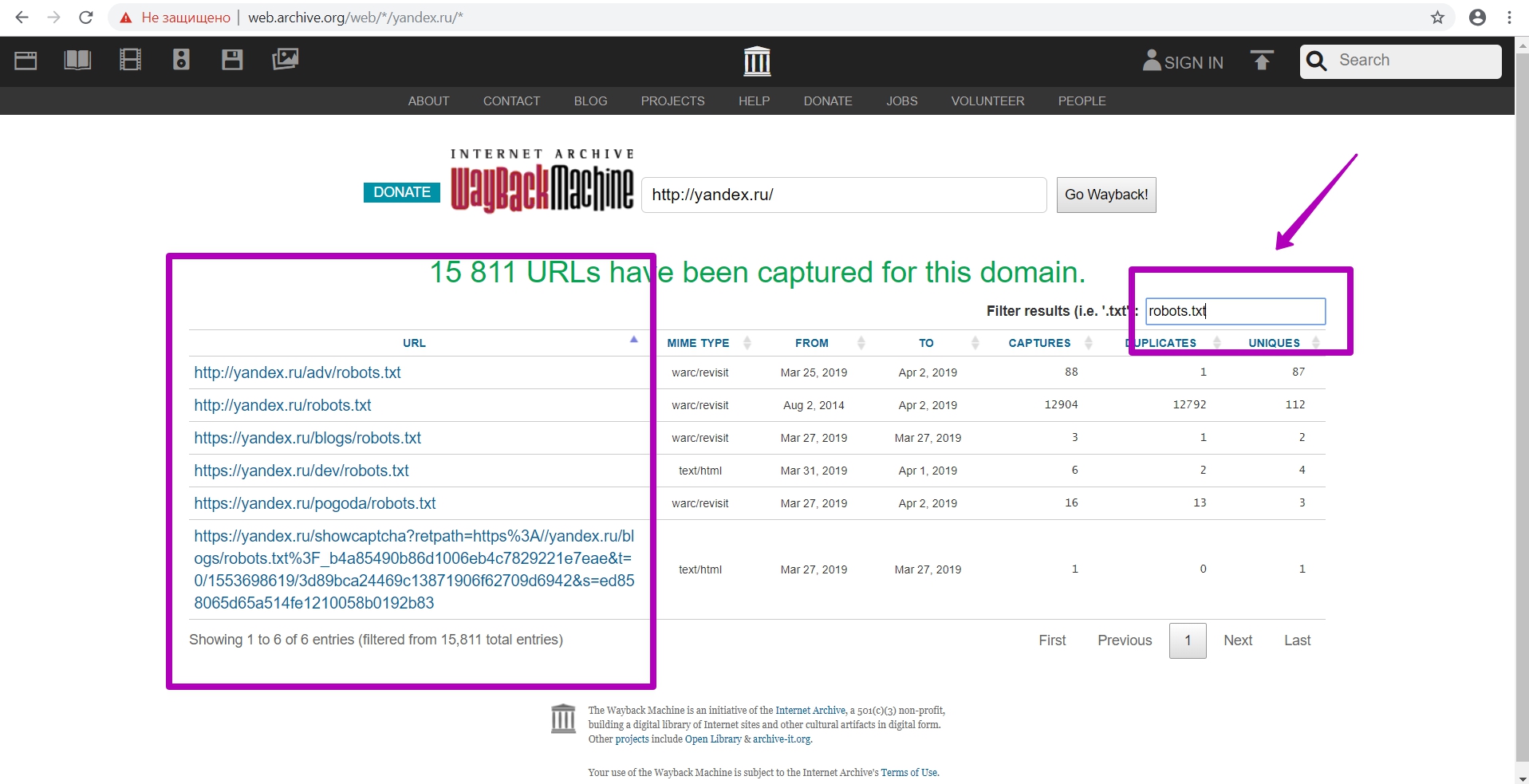
When downloading the table, we also need to see if there are any other robots.txt files on this domain. As we see in the example, there are other robots.txt files located in different directories, and their rules in these directories will take precedence over the root robots.txt file.
So, if you see several files, it is better to download all available files to be sure that all materials for saving are open.
In order not to search for another robots.txt files on the website, we made 3 files (download link), so that you need to upload them to the new domain hosting for everything to be done correctly.
These are robots.txt, .htaccess and index.php. Here are the contents of these files:
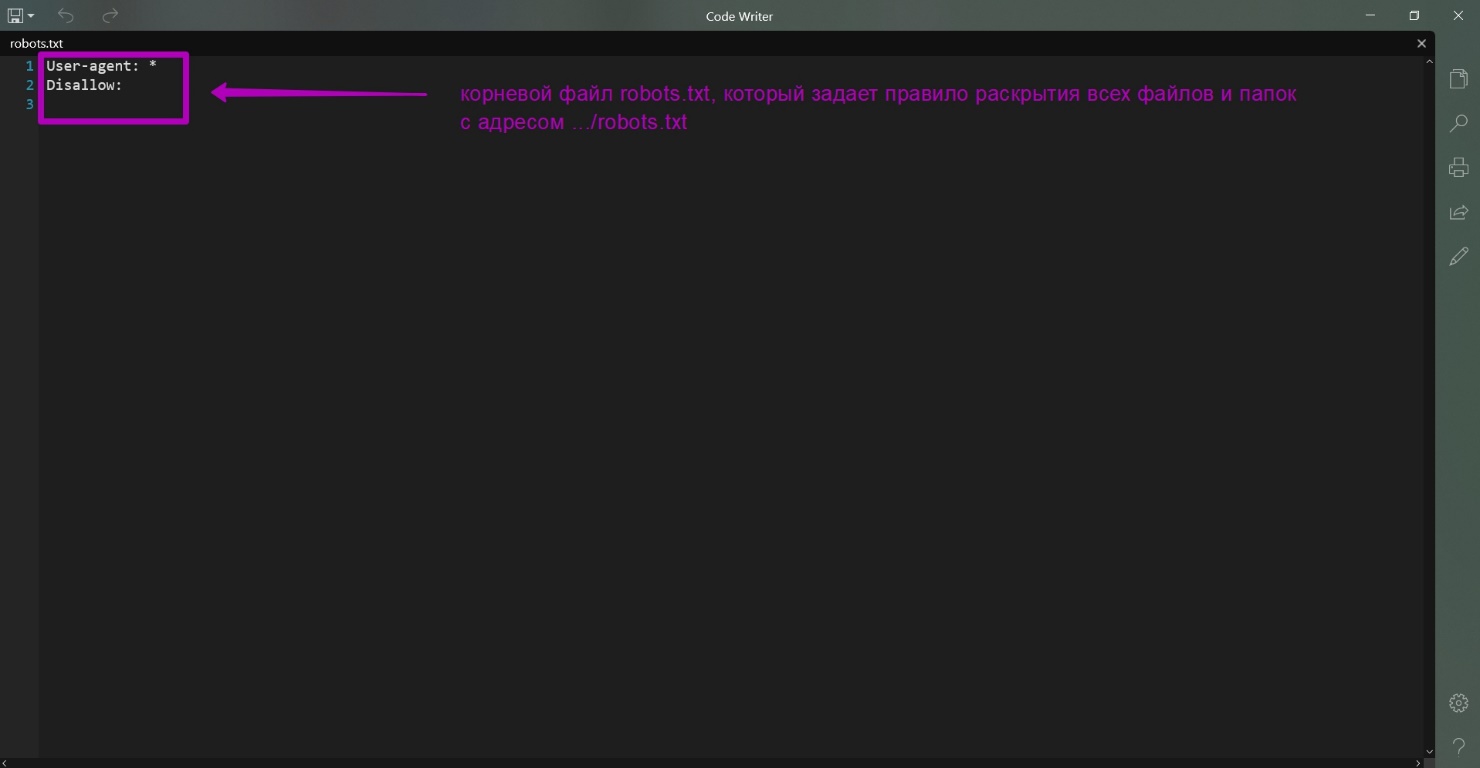
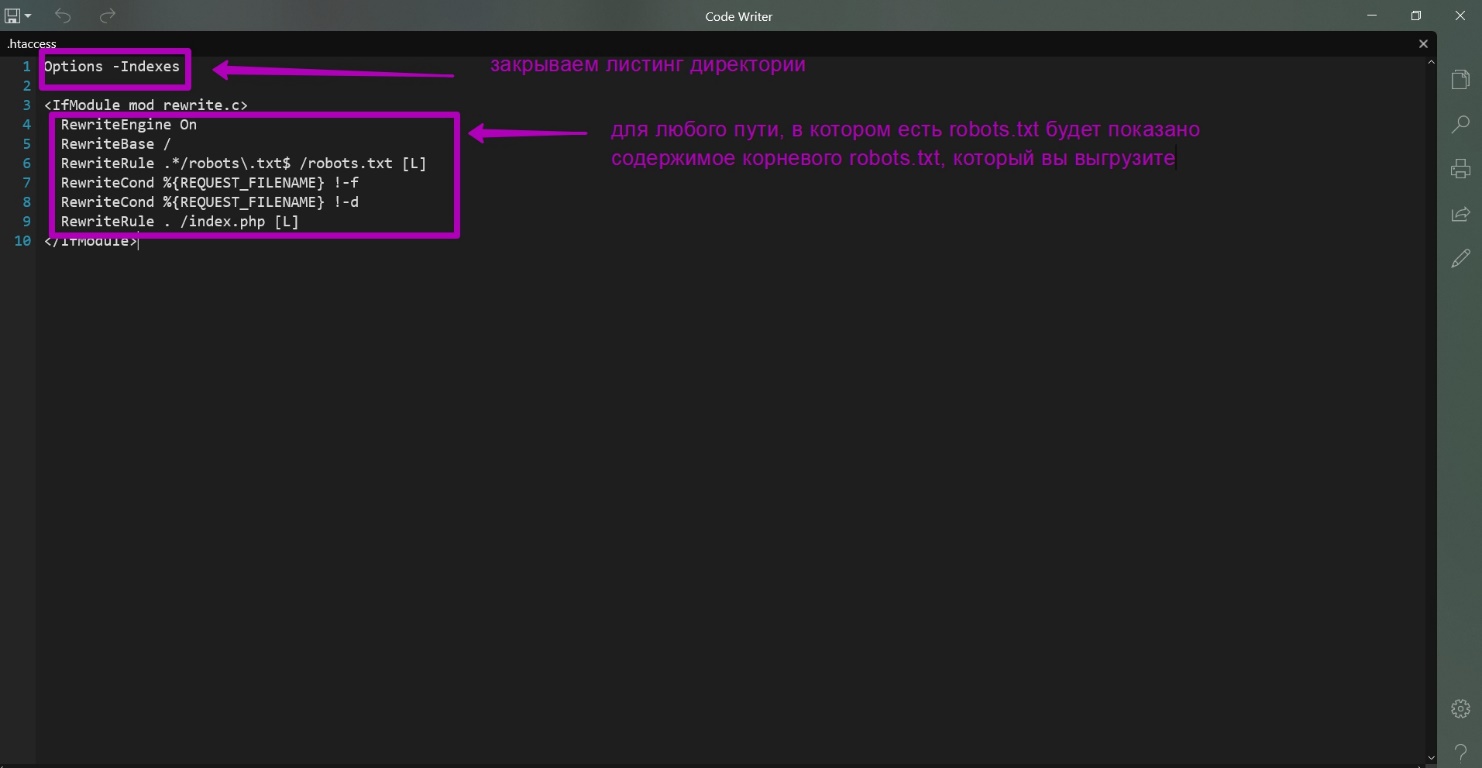
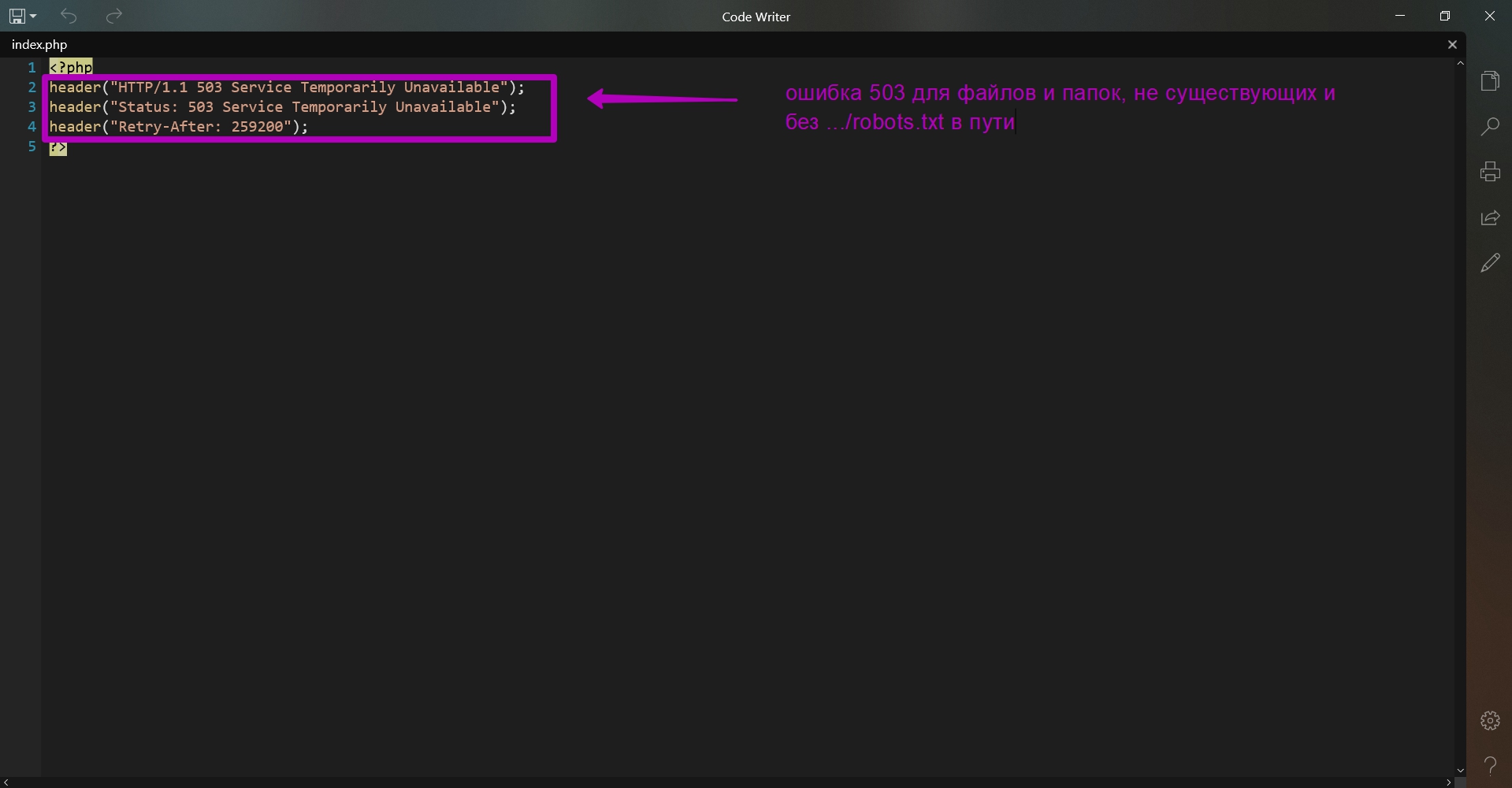
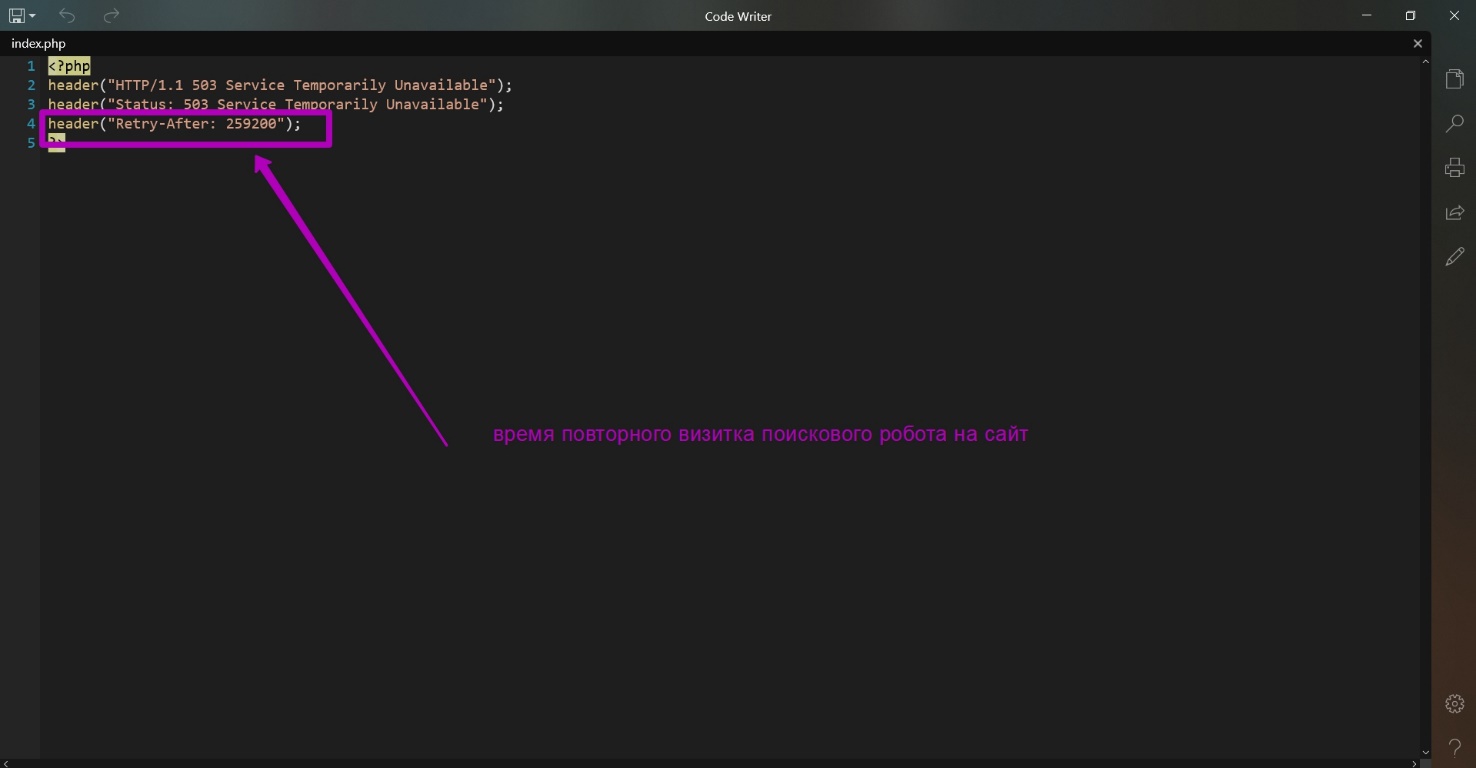
What is the purpose of these files?
- All urls having robots.txt at the end will now show the contents of this file not from the directory, whatever it may be, but from the root directory. Thus, we solve the problem of creating additional folders and downloading additional robots.txt.
- For all other requests besides .../robots.txt and all non-existing files and folders index.php will be loaded. It simply shows 503 code when opened. It is done so that when you bind domain to hosting, the search engine spider does not receive the 404 error response when it comes to your website. If this happens, then important content will not be indexed. Search engines that have received 503 response code consider website as if there is a technical work carried out, so search engine will come back later to index the updated content. In the index.php file you can see an additional Retry After line that stands for time measured in seconds for the search robot to return for indexing your website. So, if search engine robot visited you website, but you have not yet uploaded any content, then the search engine robot will come back later to check the site’s functionality. A repeat visit time of 3 days is already indicated in this file.
- Since web archive is very slow, after adding a new robots.txt you need to wait at least 24 hours until the changes take effect. Only after such a period website can be checked for being available to Summary tool, after that you can start restoring your website. That is, after downloading these files, you can safely restore website on the purchased domain, and be sure that search engine spiders do not cache something wrong, for example, an open root directory structure or 404 errors.
Possible problems when restoring robots.txt
Example 1.
On the main page, we enter a link to the file: forexbloger.ru/robots.txt. Then we see a calendar for this particular url with saving versions of this file.
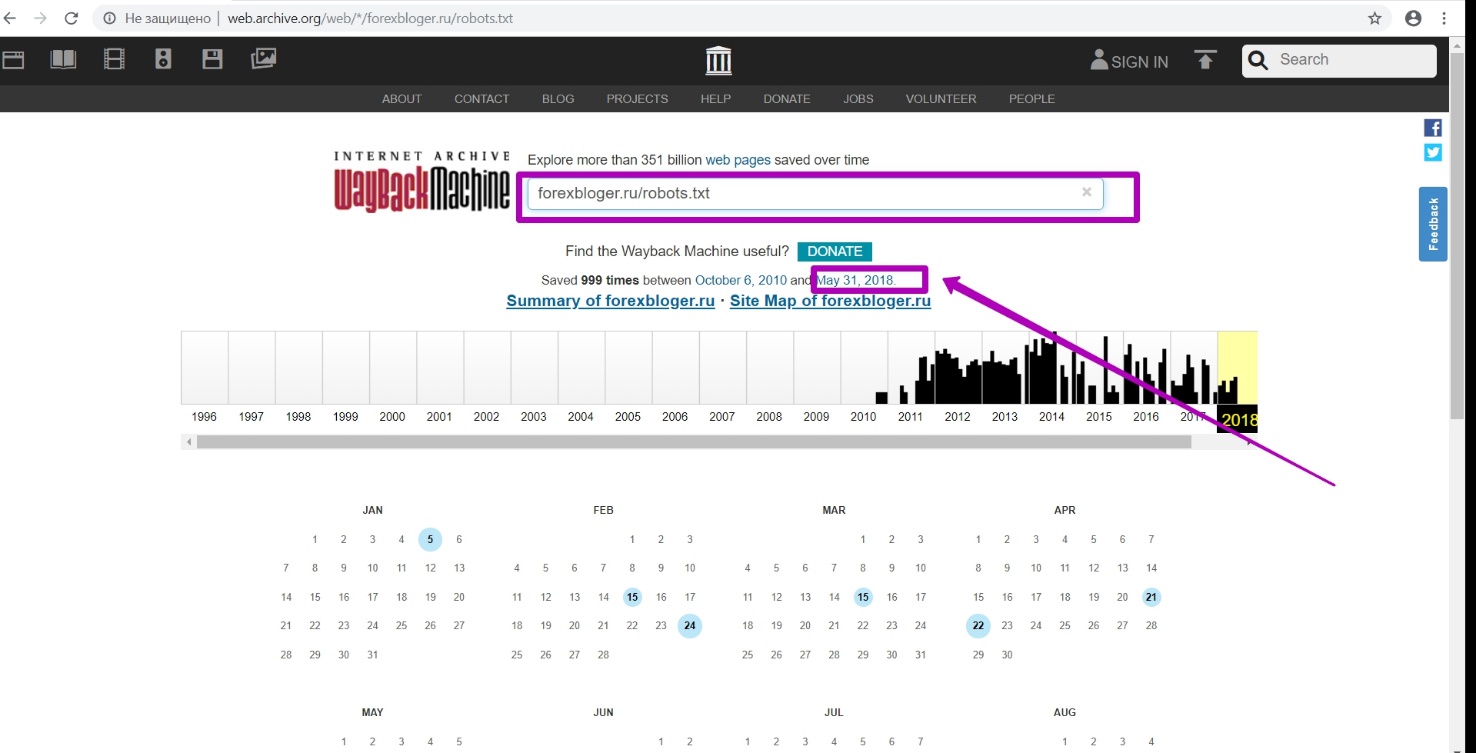
Then we open the latest version on the calendar dated May 31. We see that it was robots.txt file from WordPress CMS.
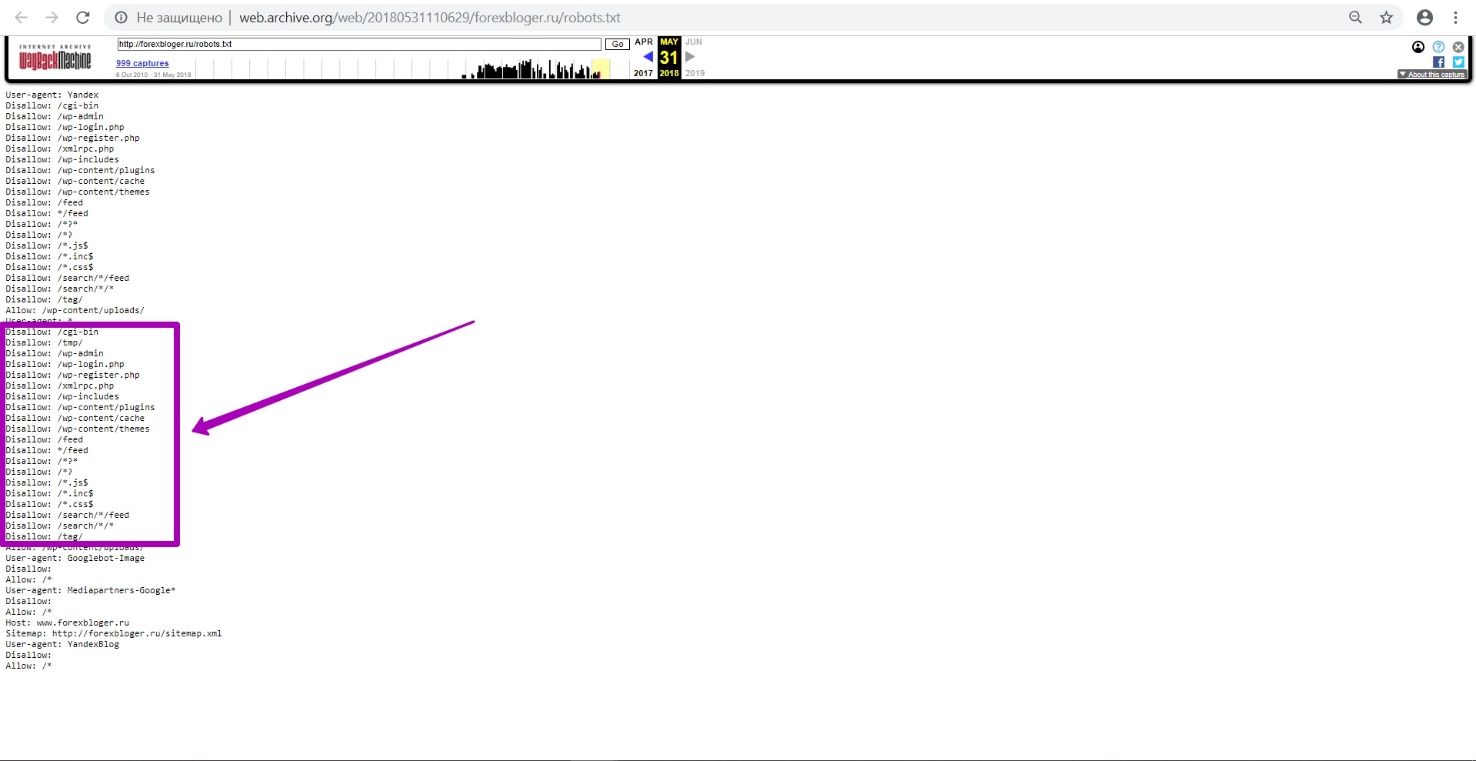
WordPress is a separate situation, because this CMS often closes very important and necessary folders and files in robots.txt file.
In this example we see that the folder with themes is closed, that is, even the folder with media files can be closed. As a result, when you restore and browse website through the web archive, everything will be OK, but restored website will have the designs, styles, and texts that have come down. But if you perform the preparation stage correctly and open website for indexing using new downloads, this problem can be avoided.
Example 2.
On the main page, we enter a link: tv-blog.ru/robots.txt
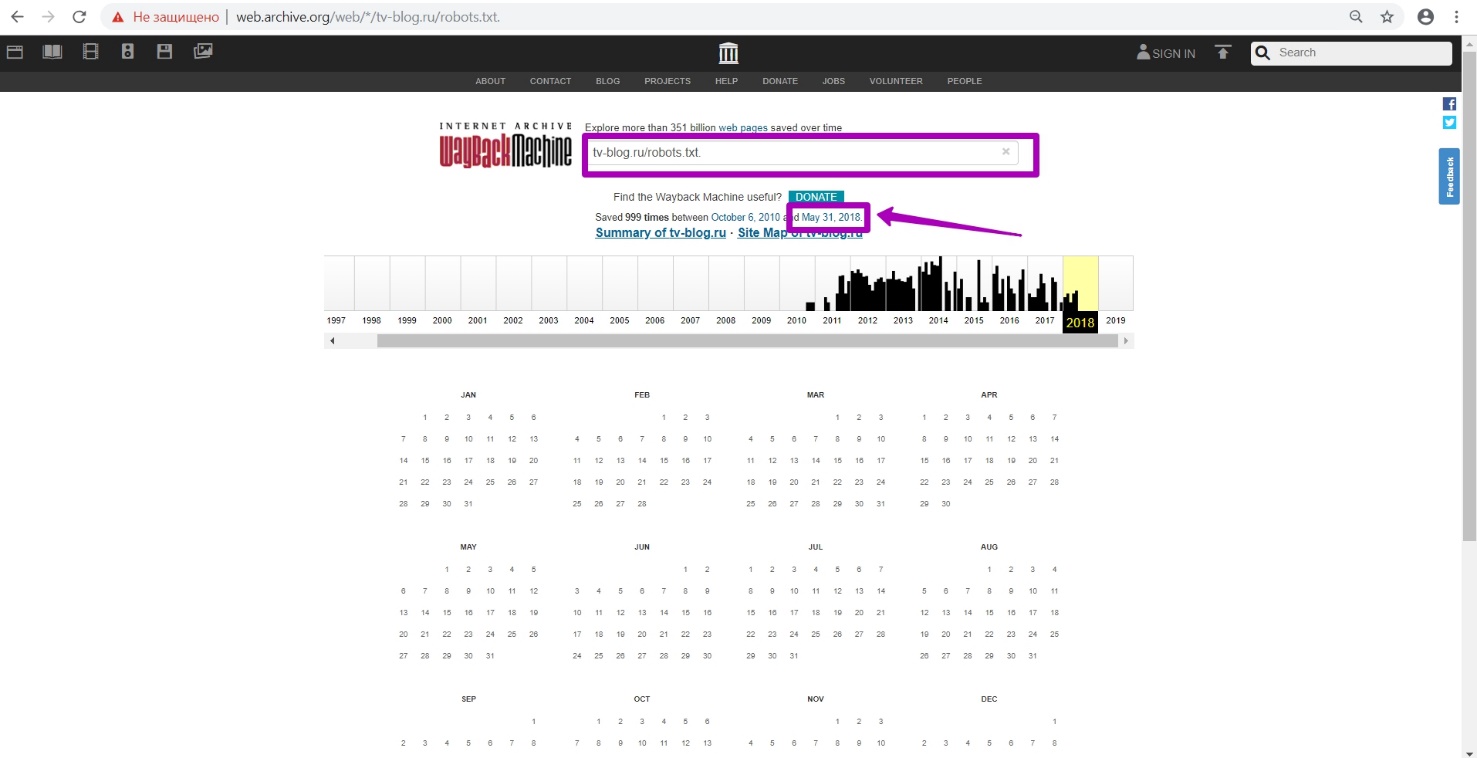
Let’s open the last version on the calendar dated May 31.

Here we can see that the website is completely closed from indexing!
And this is not the site owner’s fault, but the problem is that when domain provider’s parking page was there, he uploaded he robots.txt file with such content. It’s not OK both for website restoring and search engines. Since when they visit and see such a website, they will begin to remove from the index everything that has been saved. New robots.txt file that you upload to a new hosting domain that opens the site contents for indexing may be a solution for such a problem.
The instructions that we provide are suitable for all websites, including those that had ain provider’s parking pages. This instruction will allow you not only restoring the maximum possible amount of old website content from the web archive, but restoring its position in the search as well.
In the next part we will discuss how to choose “before” date for your domain.
How to restore websites from the Web Archive - archive.org. Part 1
How to restore websites from the Web Archive - archive.org. Part 3
The use of article materials is allowed only if the link to the source is posted: https://archivarix.com/en/blog/2-how-does-it-works-archiveorg/

Web Archive Interface: Instructions for the Summary, Explore, and Site map tools. For reference: Archive.org (Wayback Machine - Internet Archive) was created by Brewster Cale in 1996 about at the same…
In the previous article we examined archive.org operation, and in this article we will talk about a very important stage of site restoring from the Wayback Machine that relates to domain preparation f…
Choosing “BEFORE” limit when restoring websites from archive.org. When domain expires, domain provider or hoster’s parking page may appear. When entering such a page, the Internet Archive will save it…