Как восстанавливать сайты из Веб Архива - archive.org. Часть 2
В прошлой статье мы рассмотрели работу сервиса archive.org, а в этой статье речь пойдет об очень важном этапе восстановления сайта из веб-архива ― этапе подготовки домена к восстановлению. Именно этот шаг дает уверенность, что вы восстановите максимум контента на вашем сайте.
Все работы, описанные на этом этапе, связаны с правилами robots.txt. Archive.org индексируя сайт не учитывает правила, записанные в robots.txt, но сам файл он сохраняет. Когда вы смотрите архивную версию через сайт archive.org, он вам покажет файлы, дизайны, картинки, которые были сохранены игнорируя robots.txt. Но когда вы восстанавливаете сайт, используя API веб-архива - эти файлы отдаваться не будут, потому что веб-архив тут начинает соблюдать правила robots.txt, который был сохранен им при индексации. Но это не является проблемой, ведь веб-архив учитывает только самую последнюю версию robots.txt и её можно создать самим.
Как подготовить сайт к выгрузке из веб-архива?
- Купить домен, на котором был данный сайт.
- Настроить DNS записи на купленном домене и привязать его к хостингу.
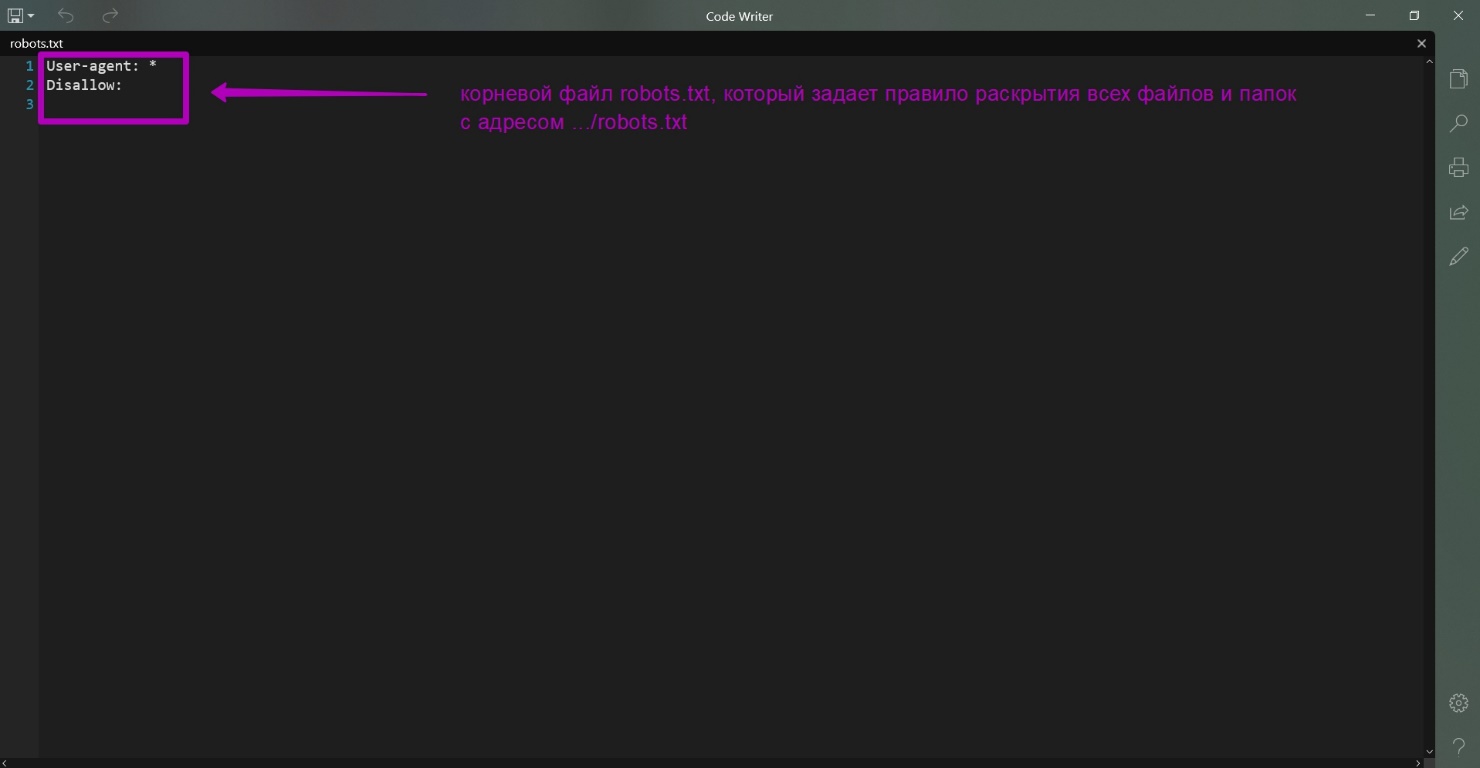
- Создайть файл robots.txt с таким текстом:
User-agent: *
Disalow:
И разместить его в корне сайта, который вы хотите восстановить.
- Сохранить файл robots.txt с открытой индексацией в базе веб-архива. Делается это так:
На главной странице веб-архива есть форма Save Page Now:
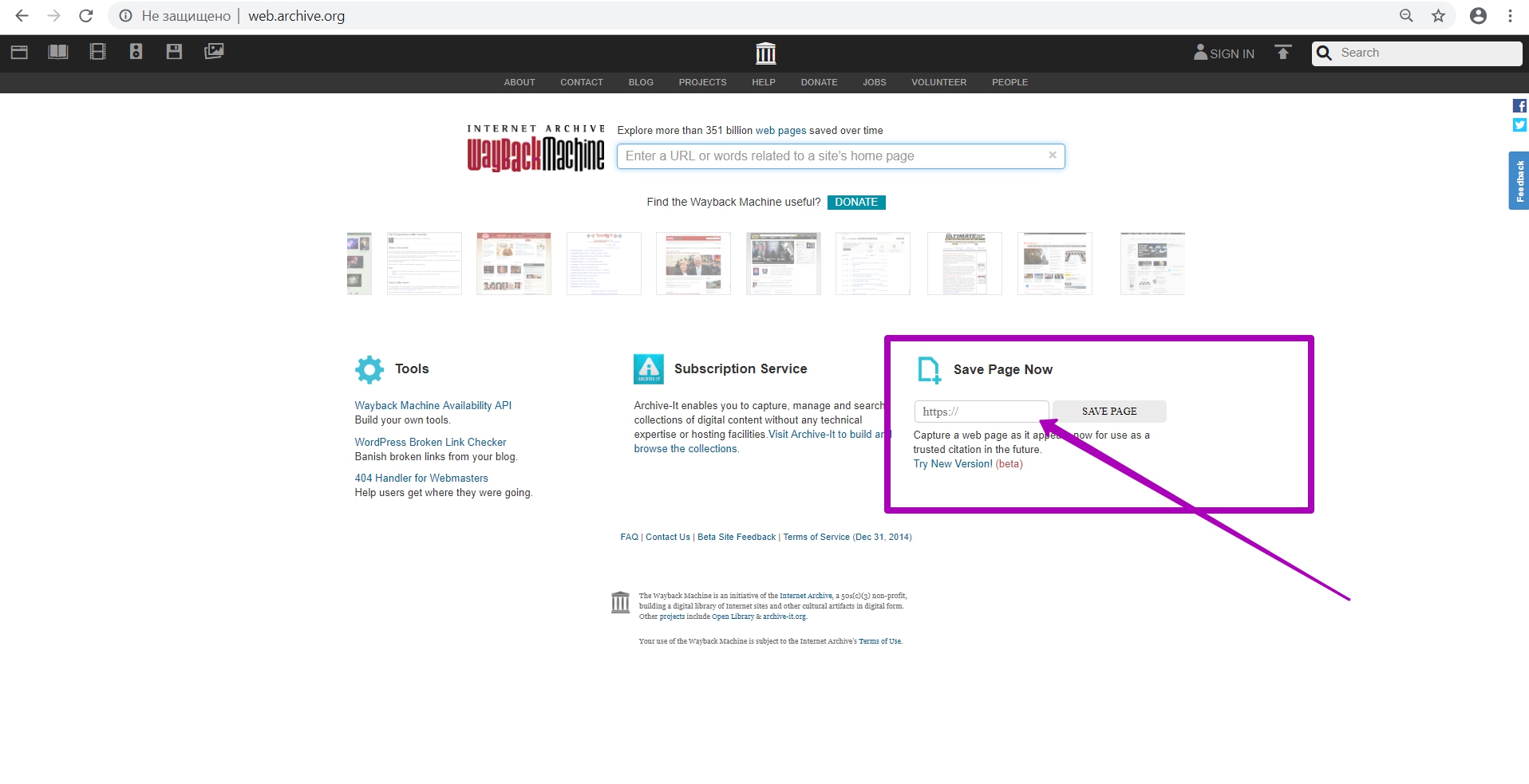
В форме мы вводим полный url файла robots.txt на новом домене. Причем, не важно, какой протокол подключения нового домена (http или https) ― robots.txt будет аналогичный. Индексация нового robots.txt будет применяться ко всем сохраненным ранее данным, независимо от прошлого протокола (http или https.). Итак, сохраняем robots.txt, нажимая кнопку SAVE PAGE.
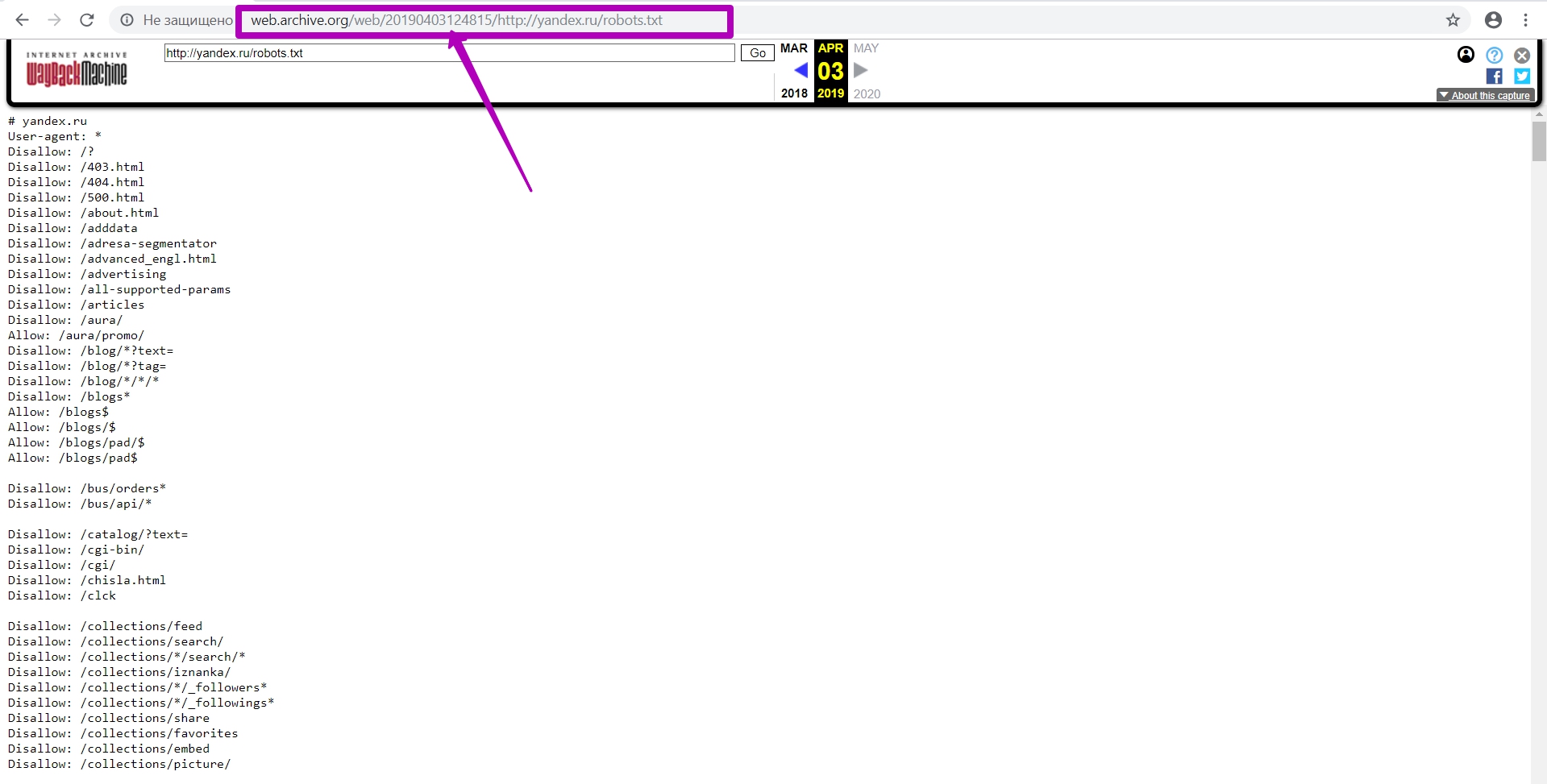
Тут мы видим новую версию robots.txt на новом домене и хостинге, и текущий timestamp. Учтите, это происходит не сразу после того как вы нажали кнопку SAVE PAGE. Должно пройти около 24 часов, прежде чем новая версия robots.txt появится в веб-архиве. Если файл не открывается, выбивает ошибку или просто белый экран ―войдите в режиме инкогнито или с другого браузера. Если у вас белый экран или ошибки, значит файл не сохранился.
Проверяем индексируемость. Переходим на общий календарь и на инструмент Summary, а в нем – explore.
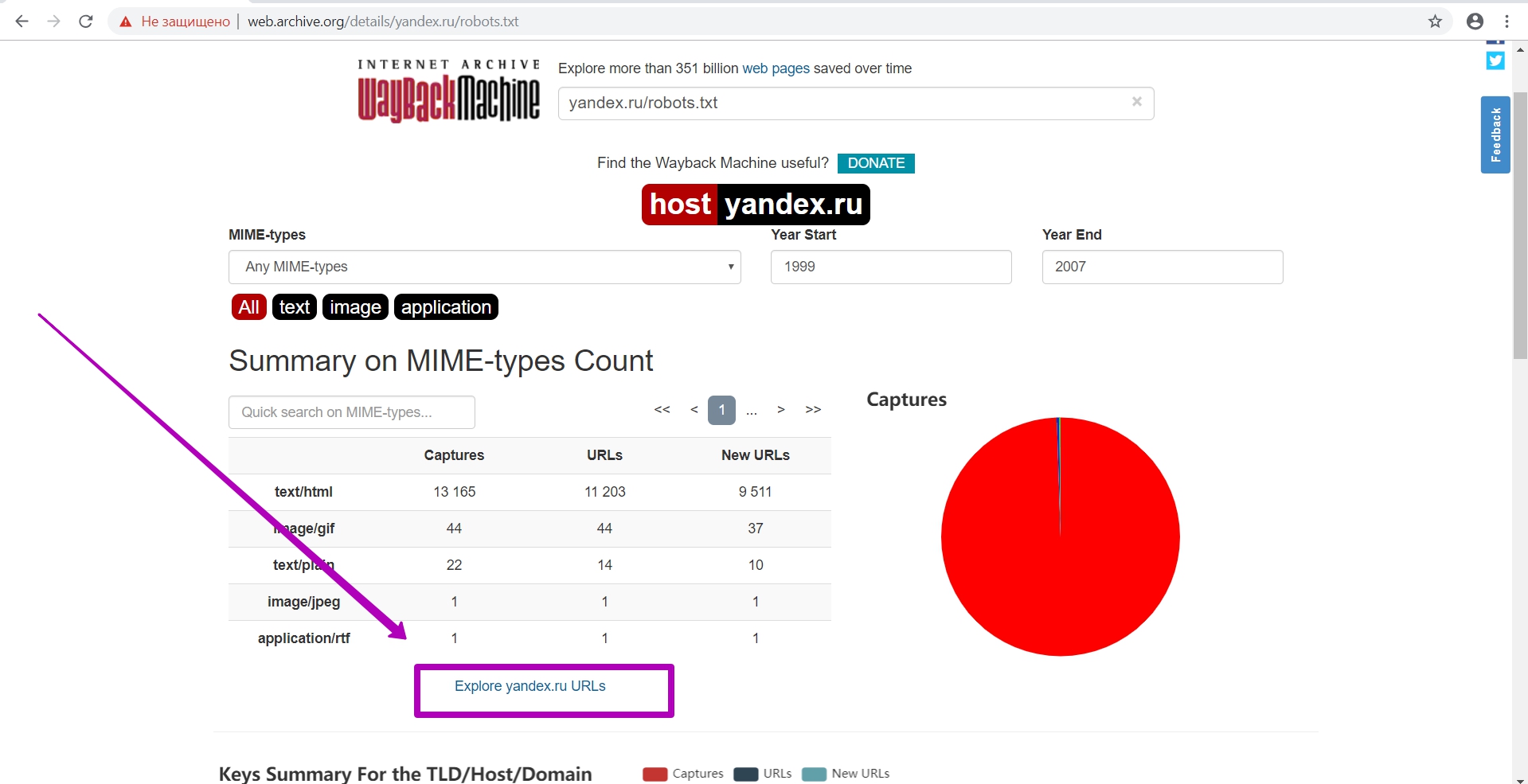
Этот инструмент уже работает с api веб-архива. Тут мы можем проверить, открыта теперь индексация или нет. Если таблица данных по файлу выгрузится ― индексация поисковыми роботами будет работать, в ином случае ― сайт закрыт от индексации (в файле robots.txt). Если закрыты частично папки, их url также закрыты.
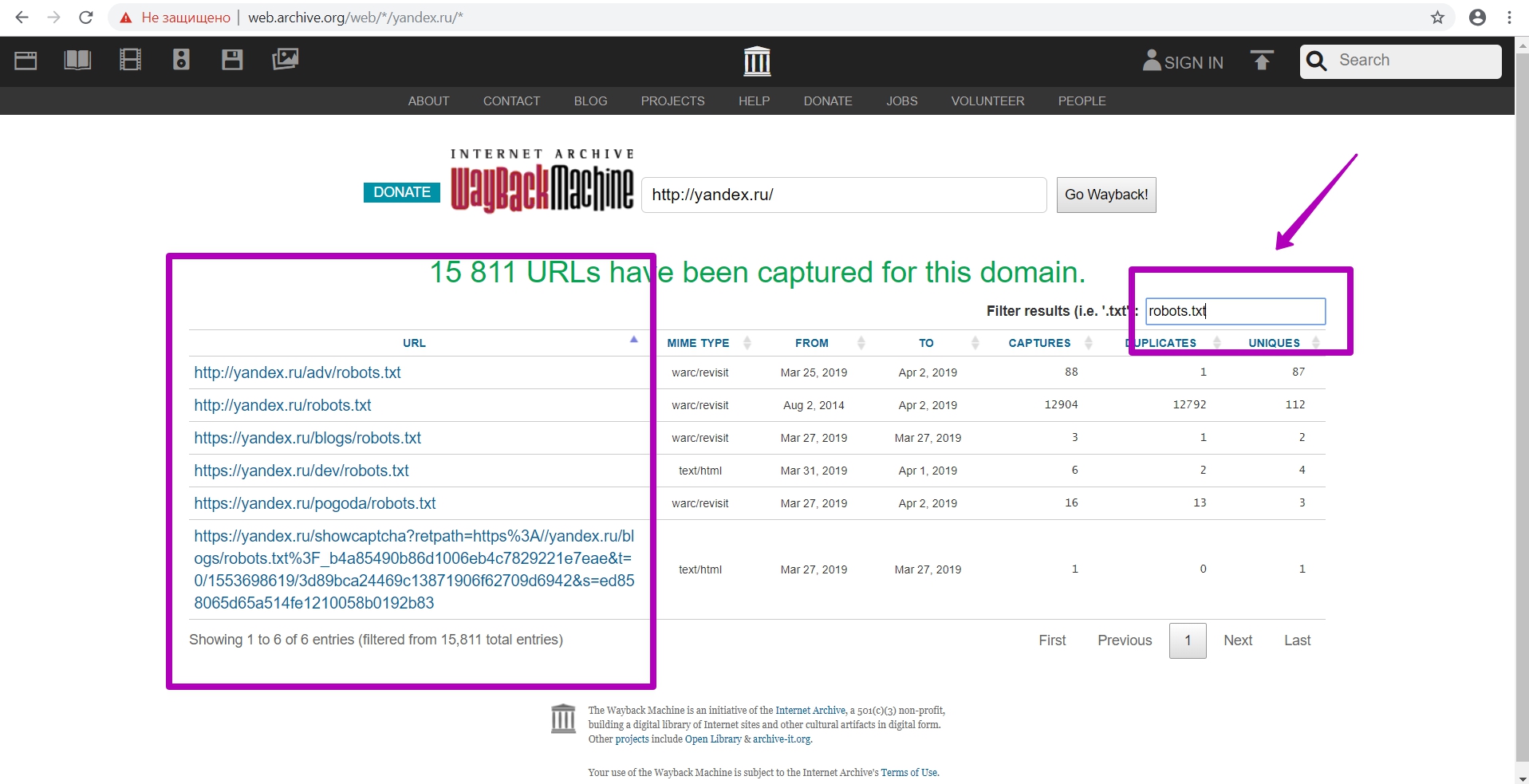
При выгрузке таблицы нам нужно также посмотреть, не находились ли еще robots.txt на этом домене. Как видим на примере, есть и другие файлы robots.txt находящиеся в разных директориях, причем их правила в этих директориях будут иметь приоритет перед корневым robots.txt
И так, если вы видите несколько файлов, то лучше подать все доступные файлы, чтобы быть уверенным, что открыты все материалы для сохранения.
Для того чтобы не разбираться были ли еще robots.txt на восстанавливаемом сайте и где именно были мы сделали 3 файла (ссылка для скачивания), которые достаточно загрузить на хостинг нового домена, чтобы все выполнить верно.
Это robots.txt, .htaccess и index.php. Вот содержимое этих файлов:
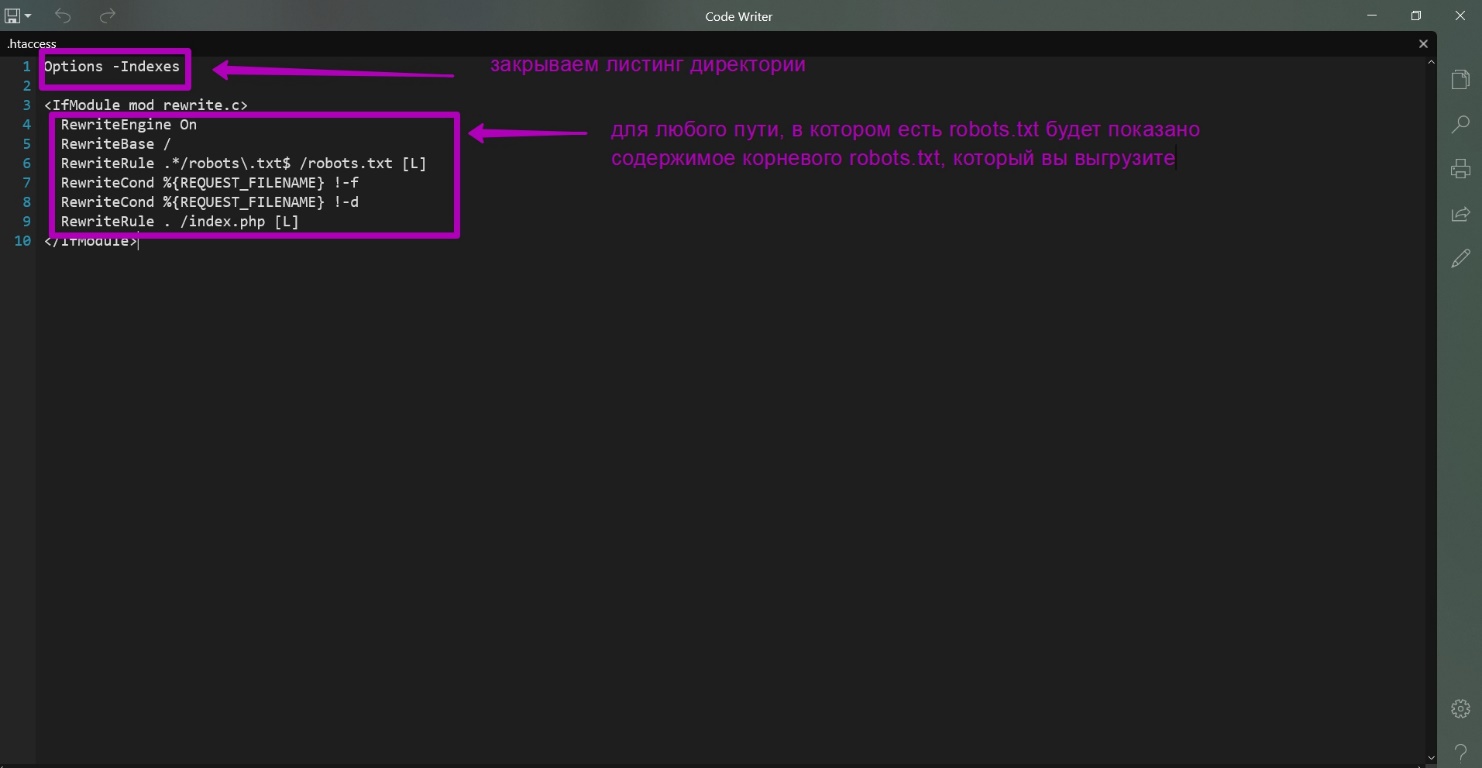
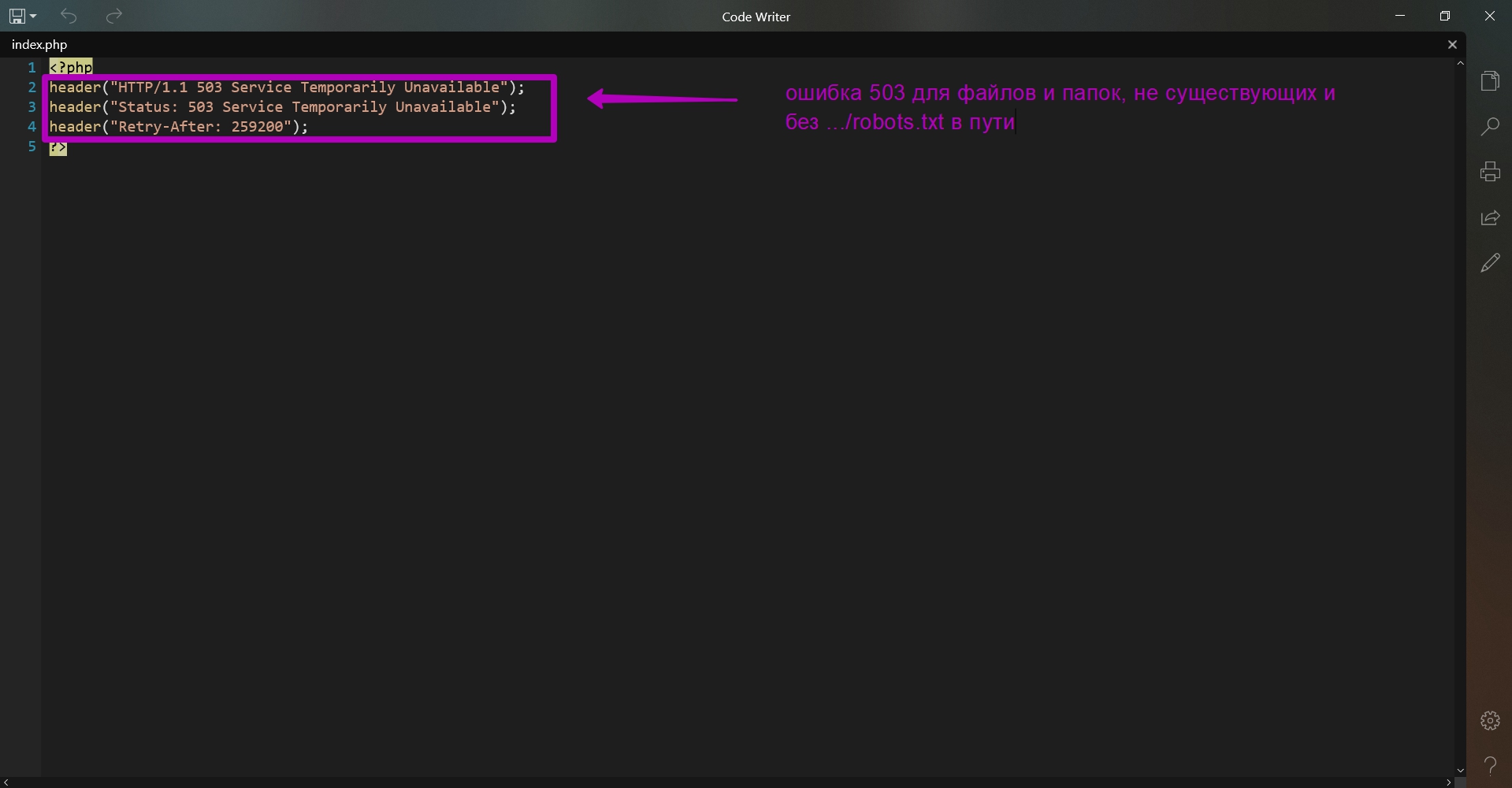
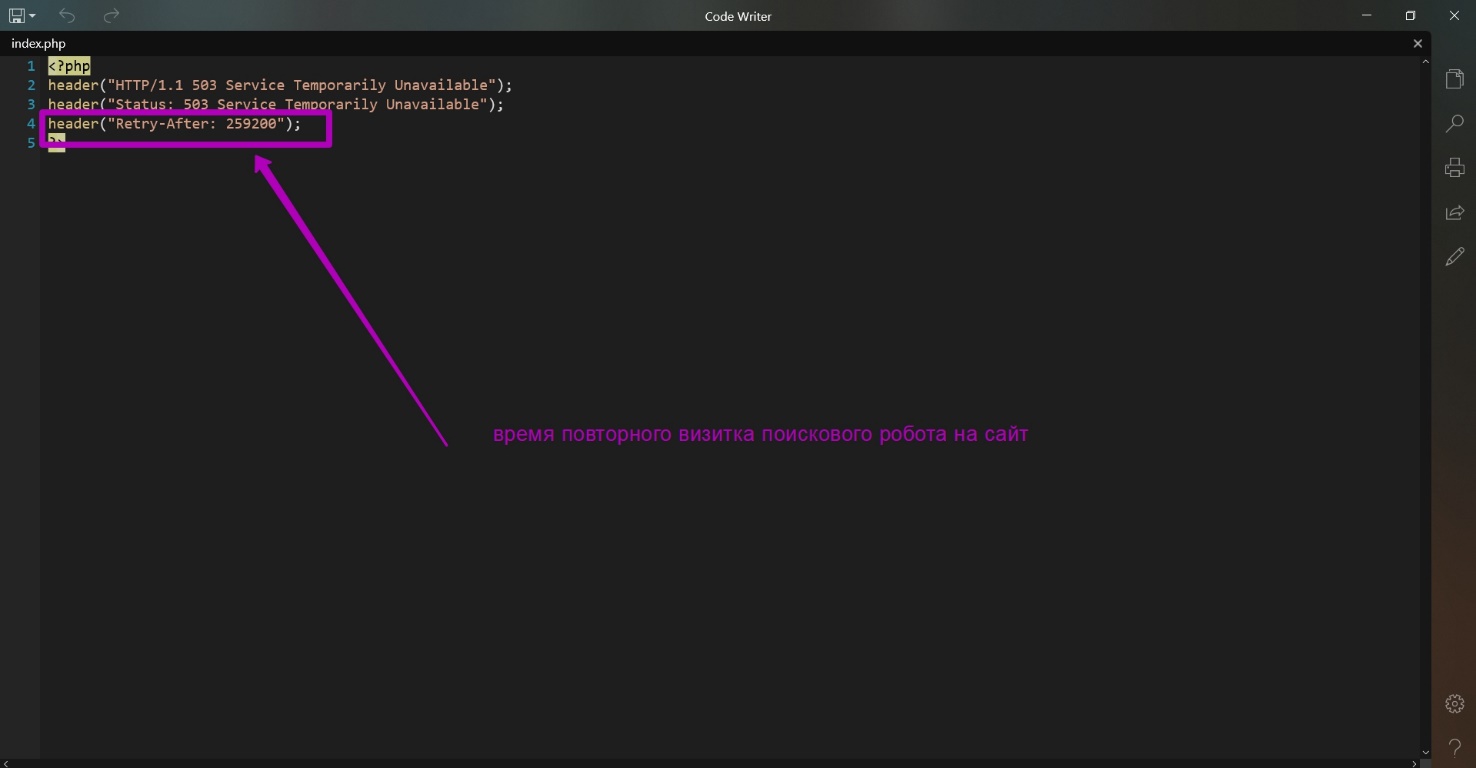
Что эти файлы делают?
- Все url, которые имеют в конце robots.txt, теперь будут показывать содержимое этого файла не из директории, какая бы она ни была, а из корневого каталога. Таким образом мы решаем проблему создания дополнительных папок и выгрузки дополнительных robots.txt.
- На все остальные запросы помимо …/robots.txt и все не существующие файлы и папки будет подгружаться index.php. Он просто выдает при своем открытии код 503. Это делается для того, чтобы когда вы привяжете домен к хостингу, паук поисковика не получал ошибку 404, заходя к вам на сайт. Если так получится, то важный контент не будет индексироваться. Поисковые системы, получившие код 503, рассматривают сайт как такой, на котором проводятся технические работы, и поисковик зайдет позже для индексации обновленного содержимого. В файле index.php дополнительно вы видите строку Retry After ― это время в секундах, через какое время поисковый робот посетит сайт для индексации. Т.е. если к вам перешел поисковик, а вы пока еще не залили контент на сайт то поисковик зайдет позднее, чтобы проверить работоспособность сайта. В секундах в файле уже установлено время повторного визита ― через 3 дня.
- Так как веб-архив очень медленный, после добавления нового robots.txt требуется подождать минимум 24 часа пока изменения вступят в силу. Именно спустя данное время сайт можно проверять на открытость инструментом Summary и начинать восстанавливать сайт. То есть загрузив эти файлы, вы можете спокойно восстанавливать сайт на купленном домене, и быть уверенными, что пауки поисковиков не закешируют что-то не то, например открытую структуру корневой директории или 404 ошибки.
Возможные проблемы при восстановлении robots.txt
Пример 1.
На главной странице мы вводим ссылку на файл ― forexbloger.ru/robots.txt. И видим календарь именно для этого url с версиями сохранения этого файла.
Открываем последнюю версию в календаре за 31 мая. Мы видим, что это был robots.txt от WordPress CMS.
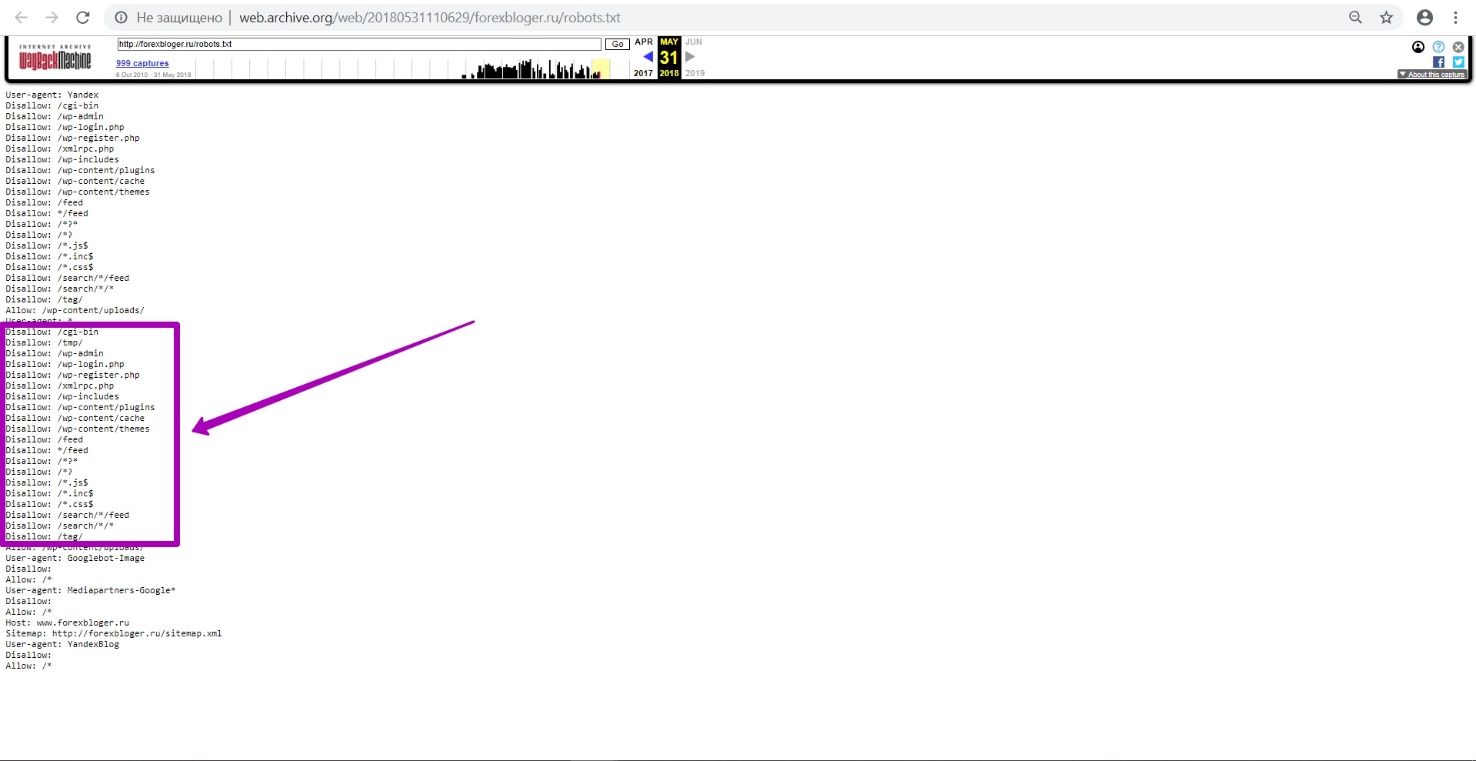
WordPress ― это отдельная ситуация, так как эта CMS часто закрывает очень важные и нужные папки и файлы в robots.txt.
На примере мы видим, что закрыта папка с темами, то есть может быть закрыта даже папка с медиа файлами. В итоге, когда вы будете восстанавливать, и просматривать сайт через веб-архив, у вас все будет хорошо, а в восстановленном сайте будут съехавшие дизайны, стили, тексты. Но если правильно выполнить этап подготовки и с помощью новых загружаемых файлов открыть сайт для индексации, такой проблемы возможно избежать.
Пример 2.
На главной странице мы вводим ссылку ― tv-blog.ru/robots.txt
Открываем последнюю версию в календаре за 31 мая.

Тут в файле мы видим, что сайт закрыт от индексации полностью!
И это вина не владельца сайта, а проблема в том, что, когда на сайте висела заглушка домен-провайдера, он поставил файл robots.txt с таким содержимым. Это плохо и для восстановления, и для поисковиков. Так как когда они зайдут и увидят такой сайт, они начнут удалять из индекса, все что было сохранено. Решение проблемы ― новый файл robots.txt, который вы выгружаете на новый домен с хостингом, открывающий содержание сайта для индексации.
Инструкция, которую мы приводим, подходит для всех сайтов, включая те, на которых были установлены заглушки провейдеров. Инструкция вам позволит не только восстановить максимально возможное количество контента старого сайта из веб-архива, но и восстановить его позиции в поиске.
А в следующем гайде мы рассмотрим, как правильно выбрать дату «до» для вашего домена.
Этот видео гайд есть на Youtube:
Как восстанавливать сайты из Веб Архива - archive.org. Часть 1
Как восстанавливать сайты из Веб Архива - archive.org. Часть 3
Использование материалов статьи разрешается только при условии размещения ссылки на источник: https://archivarix.com/ru/blog/2-how-does-it-works-archiveorg/

В этой статье мы расскажем о самом web.archive и о том, как он работает. Интерфейс веб-архива: инструкция к инструментам Summary, Explore и Site map. В этой статье мы расскажем о самом web.archive и…
Подготовка домена к восстановлению. Создание robots.txt
В прошлой статье мы рассмотрели работу сервиса archive.org, а в этой статье речь пойдет об очень важном этапе восстановления сайта из веб-архи…
Выбор ограничения ДО при восстановлении сайтов из веб-архива. Когда домен заканчивается, на сайте может появится заглушка домен-провайдера или хостера. Перейдя на такую страницу, веб-архив будет ее со…