Сколько живёт веб-страница: что говорят исследования о link rot
Откройте любую статью десятилетней давности и пройдитесь по ссылкам в ней. С большой вероятностью часть из них уже никуда не ведёт. Вместо нужной страницы вас встретит ошибка 404, припаркованный домен с рекламой дешёвой страховки или редирект на чужой сайт. Это явление называется link rot, «гниение ссылок», и оно куда масштабнее, чем принято думать.
Читать дальше…
Archivarix Echo: проверьте 200+ веб-архивов одним запросом
Интернет постоянно осыпается. Страницы уходят в офлайн, аккаунты удаляют, статьи прячут за пейволл, проекты закрывают. Но копии чаще всего где-то остаются: Wayback Machine, archive.today, Common Crawl, научные индексы вроде Crossref, библиотеки вроде Open Library и ещё сотни узких, тематических архивов. Беда в том, что все они порознь. Чтобы понять, где что сохранилось, раньше приходилось открывать их по очереди: сначала Wayback, потом archive.today, потом десяток научных и книжных баз.
Читать дальше…
AI-саммари видео в Archivarix Tube Search
Когда вы находите удалённое видео YouTube через Tube Search, вы обычно получаете метаданные: название, описание, дату загрузки и иногда субтитры. Это уже полезно. Но чтение необработанных субтитров, чтобы понять, о чём было видео, требует времени, особенно для длинных записей.
Мы добавили в Tube Search AI-саммари видео. Если у видео есть архивные субтитры, система может за считанные секунды сгенерировать структурированное изложение его содержания.
Читать дальше…
Мы добавили в Tube Search AI-саммари видео. Если у видео есть архивные субтитры, система может за считанные секунды сгенерировать структурированное изложение его содержания.

Archivarix Tube Search - Поисковая система по удаленным видео YouTube
Tube Search - это поисковый движок по архивным данным YouTube. Сервис агрегирует информацию из нескольких публичных источников: Wayback Machine (Internet Archive), Common Crawl и различных собранных датасетов метаданных YouTube. Когда видео удаляется с YouTube, его страница перестает существовать. Но если до удаления эту страницу успел проиндексировать один из веб-архивов, метаданные видео сохраняются: название, описание, дата загрузки, количество просмотров, превью-изображения, субтитры.
Читать дальше…

Archivarix Broken Links Recovery: бесплатный плагин WordPress для поиска и восстановления битых ссылок
Со временем внешние ссылки в записях Wordpress неизбежно ломаются, страницы удаляются, домены истекают, видео становятся недоступными. Проверять сотни или тысячи ссылок вручную непрактично. Archivarix Broken Links Recovery автоматизирует этот процесс: плагин сканирует контент, находит битые ссылки и заменяет их рабочими копиями из Wayback Machine.
Читать дальше…
Как Internet Archive решает, что архивировать: приоритеты, частота, источники данных
Триллион сохранённых страниц. Более 99 петабайт данных. Сотни краулов, работающих каждый день одновременно. За этими цифрами стоит вопрос, который задаёт себе каждый, кто профессионально работает с веб-архивами: как именно Wayback Machine решает, какие сайты сканировать, как часто возвращаться к ним, и почему одни домены представлены в архиве тысячами снэпшотов, а другие имеют всего несколько записей за десять лет?
Понимание этих механизмов критически важно для всех, кто занимается восстановлением сайтов. Если вы знаете, как работает система изнутри, вы можете предсказать, что найдёте в архиве, а чего там не будет. И можете повлиять на архивирование собственных сайтов, пока они ещё живы.
Читать дальше…
Понимание этих механизмов критически важно для всех, кто занимается восстановлением сайтов. Если вы знаете, как работает система изнутри, вы можете предсказать, что найдёте в архиве, а чего там не будет. И можете повлиять на архивирование собственных сайтов, пока они ещё живы.
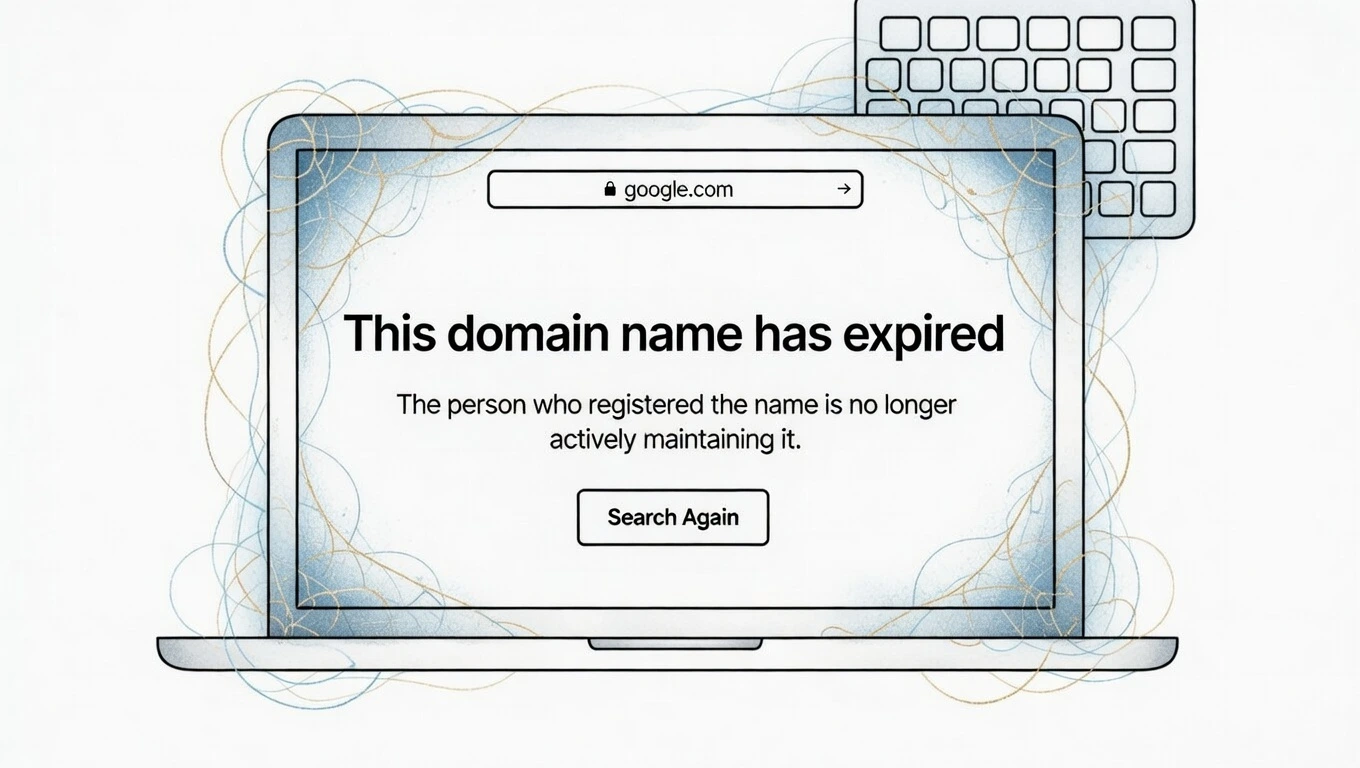
Как найти и купить истёкший домен с хорошей историей
Покупка истёкшего домена с историей это один из самых эффективных способов запустить новый проект с уже существующим ссылочным профилем, трастом и даже трафиком. Вместо того чтобы продвигать голый домен с нуля, вы получаете площадку, которую поисковые системы уже знают и которой в какой-то степени доверяют.
Читать дальше…
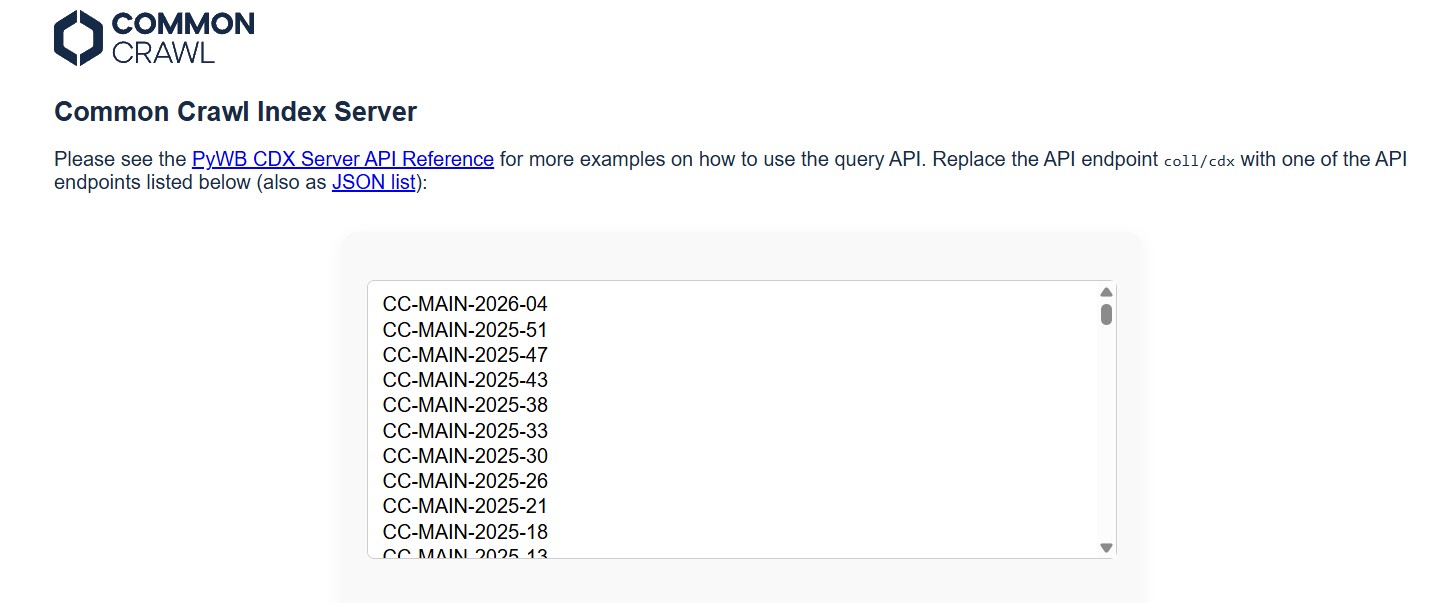
Common Crawl как альтернативный источник данных для восстановления сайтов
Когда речь заходит о восстановлении сайтов из архивов, почти все думают только о Wayback Machine. Это понятно: archive.org на слуху, у него удобный интерфейс, триллион сохранённых страниц. Но Wayback Machine не единственный крупный веб-архив в мире. Существует проект, который по объёму собранных данных сопоставим с Internet Archive, а в некоторых аспектах даже превосходит его. Этот проект называется Common Crawl, и о нём удивительно мало знают даже люди, профессионально работающие с веб-архивами.
Читать дальше…
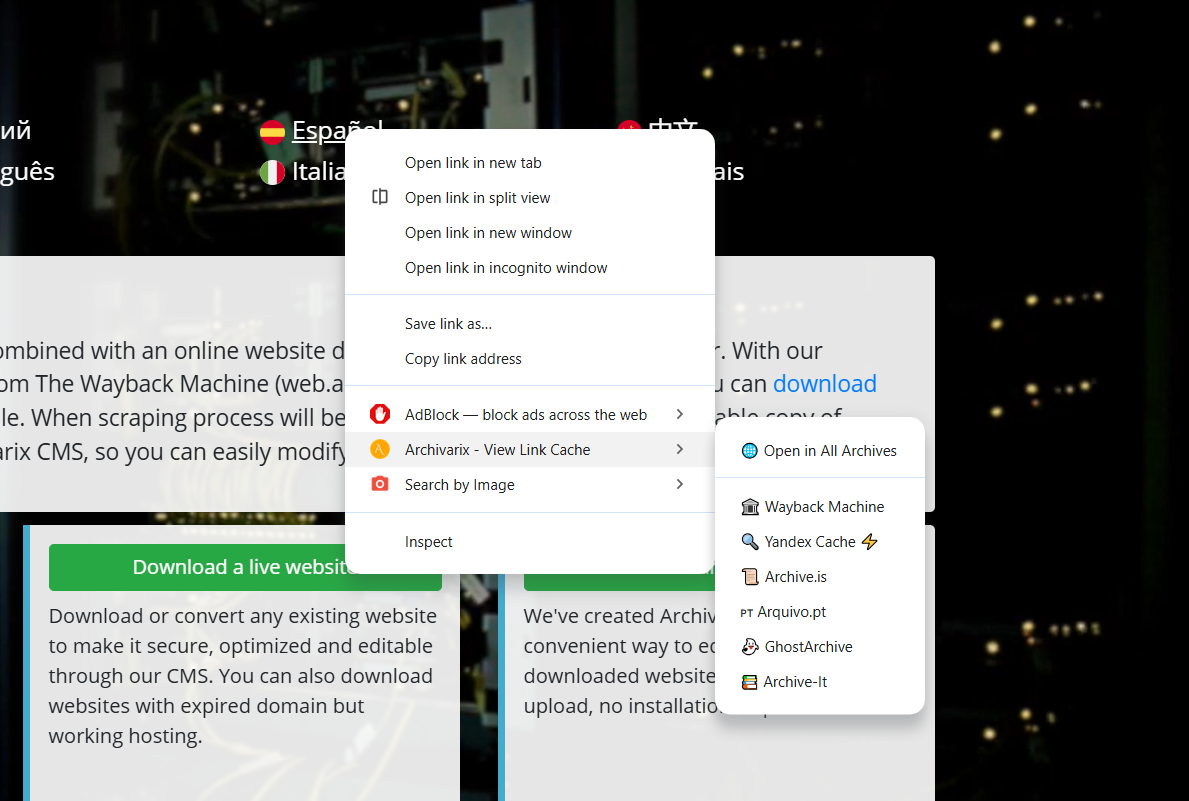
Расширение Archivarix Cache Viewer для Chrome, Edge и Firefox
Мы выпустили браузерное расширение Archivarix Cache Viewer. Оно доступно сразу для трёх браузеров: Chrome, Edge и Firefox. Расширение бесплатное и без какой-либо рекламы.
Суть простая: быстрый доступ к кешированным и архивным версиям любой веб-страницы из контекстного меню браузера. Не надо больше вручную копировать URL, открывать Wayback Machine и вставлять туда адрес. Кликнул правой кнопкой, выбрал нужный архив, готово.
Читать дальше…
Суть простая: быстрый доступ к кешированным и архивным версиям любой веб-страницы из контекстного меню браузера. Не надо больше вручную копировать URL, открывать Wayback Machine и вставлять туда адрес. Кликнул правой кнопкой, выбрал нужный архив, готово.

AI-контент на восстановленных сайтах: как обнаружить и что с ним делать
Когда вы восстанавливаете сайт из Web Archive, вы ожидаете получить оригинальный контент, который когда-то был написан живыми людьми. Но если архивы сайта были сделаны после 2023 года, есть реальный шанс столкнуться с текстами, сгенерированными языковыми моделями. Владельцы сайтов массово заменяли авторский контент на тексты от ChatGPT и аналогов, часто даже не пытаясь их отредактировать.
Читать дальше…

Веб Архив в 2026 году: что изменилось и как это влияет на восстановление сайтов
В октябре 2025 года Wayback Machine достиг отметки в один триллион сохранённых веб-страниц. Более 100 000 терабайт данных. Это огромное достижение для некоммерческой организации, которая работает с 1996 года. Но за этой красивой цифрой скрывается непростой период, через который прошёл Internet Archive за последние полтора года. Кибератаки, судебные иски, изменения в политике доступа и новые вызовы от AI-компаний - всё это напрямую влияет на тех, кто использует веб-архив для восстановления сайтов.
Читать дальше…
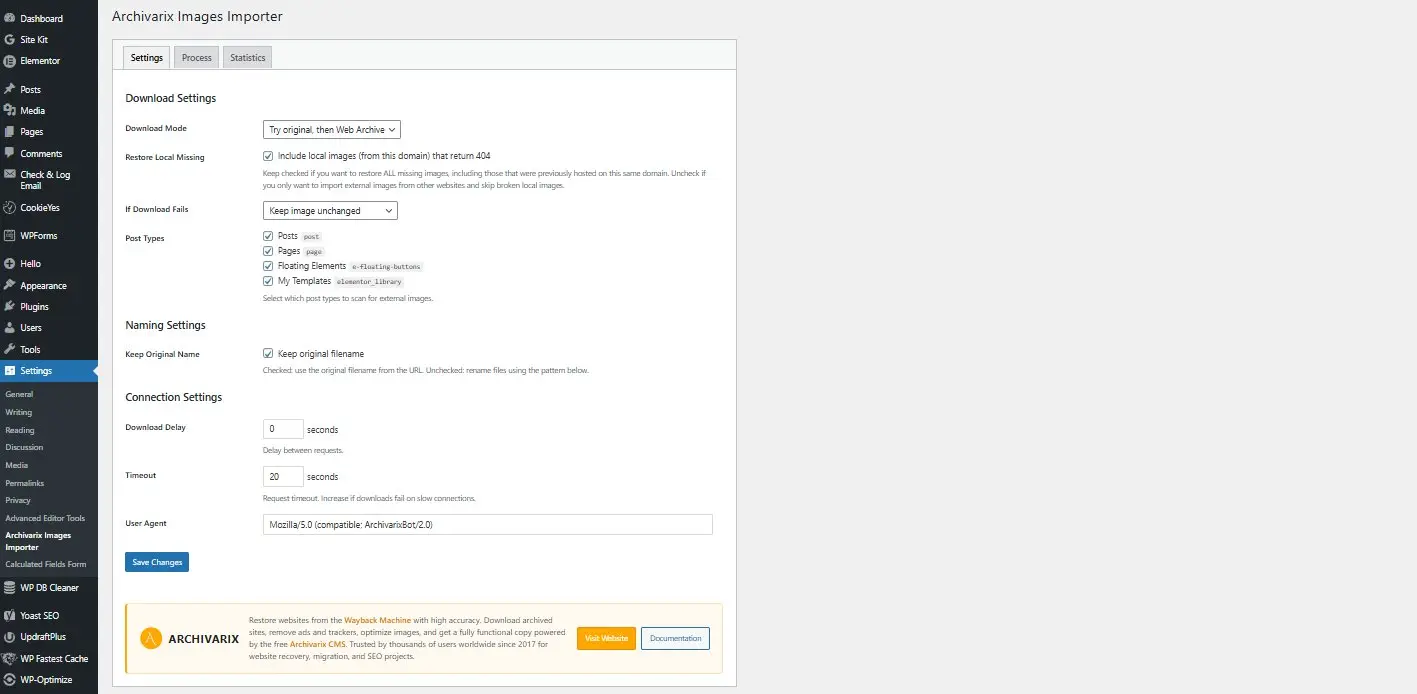
Archivarix External Images Importer 2.0 - новая версия плагина для WordPress
Мы рады представить версию 2.0 нашего WordPress плагина для импорта внешних изображений. Это не просто обновление, плагин полностью переписан с нуля с учётом современных требований и отзывов пользователей.
Читать дальше…

Купоны Black Friday & Cyber Monday
Дорогие друзья!
Black Friday и Cyber Monday - лучшее время для экономии на будущих восстановлении сайтов.
Если вы планируете восстанавливать сайты, пополнить баланс заранее или просто хотите получить больше - сейчас самый выгодный момент.
С 28 ноября по 15 декабря 2025 года вы можете использовать специальные купоны, которые дают бонусы на любое пополнение баланса. Бонус начисляется мгновенно после применения купона.
Читать дальше…
Black Friday и Cyber Monday - лучшее время для экономии на будущих восстановлении сайтов.
Если вы планируете восстанавливать сайты, пополнить баланс заранее или просто хотите получить больше - сейчас самый выгодный момент.
С 28 ноября по 15 декабря 2025 года вы можете использовать специальные купоны, которые дают бонусы на любое пополнение баланса. Бонус начисляется мгновенно после применения купона.

Archivarix 8 лет!
Дорогие друзья!
Сегодня мы празднуем 8-летие сервиса Archivarix, и это повод сказать вам огромное спасибо!
Мы искренне рады, что вы выбрали наш сервис для восстановления сайтов из веб-архива. Многие из вас пользуются Archivarix на регулярной основе, и это вдохновляет нас становиться лучше.
Читать дальше…
Сегодня мы празднуем 8-летие сервиса Archivarix, и это повод сказать вам огромное спасибо!
Мы искренне рады, что вы выбрали наш сервис для восстановления сайтов из веб-архива. Многие из вас пользуются Archivarix на регулярной основе, и это вдохновляет нас становиться лучше.

7 лет Archivarix
Сегодня у нас особенный день — Archivarix празднует своё 7-летие! И мы хотим поблагодарить именно тебя за твоё доверие, идеи и обратную связь, которые помогли нам стать лучшими в деле восстановления сайтов из Веб-Архива.
Читать дальше…

Всем кто ждал скидок на пополнение баланса!
Дорогие пользователи Archivarix, Поздравляем вас с наступающими праздниками и благодарим за то, что вы выбрали наш сервис для архивации и восстановления веб-сайтов!
Читать дальше…

6 лет Archivarix
Наступил момент, когда мы гордимся не только своими достижениями, но и вашим участием в этом пути. В этом году Archivarix празднует своё 6-летие, и в первую очередь мы хотели бы выразить огромную благодарность вам, нашим преданным пользователям.
Читать дальше…

Изменение цен
С 1 февраля 2023 года изменятся цены на восстановления и скачивания. Активируйте промо-код и получите бонус.
Читать дальше…


День рождения Archivarix
Наступило 4 года с тех пор, как 29 сентября 2017 мы сделали сервис Archivarix публичным. Ежедневно пользователи делают тысячи восстановлений. Количество серверов, которые распределяют между собой скачивания и обработку всегда превышает 40, а при нагрузке система самостоятельно подключает новые машины.
Читать дальше…
Что можно восстановить из веб архива?
Иногда наши пользователи спрашивают, почему сайт восстановился не полностью? Почему он не работает так, как хотелось бы? Известные проблемы при восстановлении сайтов из archive.org.
Читать дальше…

BLACKFRIDAY
С пятницы 27.11.2020 до понедельника 30.11.2020 действуют два жирных купона. Каждый из них даёт бонус на баланс в виде 20% или 50% от суммы вашего последнего или нового платежа.
Читать дальше…
День рождения Archivarix
З года назад, 29 сентября 2017 года заработал наш сервис по восстановлению сайтов из archive.org. Все эти 3 года мы непрерывно развивались, мы создали свою CMS, систему скачивания живых сайтов, значительно улучшили и ускорили алгоритм восстановления из Веб-архива и многое другое.
Читать дальше…

Archivarix.net - Архив веб-сайтов и система поиска.
Аналог Wayback Machine (web.archive.org). Сервис по поиску архивных копий сайтов. Данные за 1996 год. Полнотекстовый поиск.
В ближайшее время наша команда планирует запустить уникальный сервис, сочетающий в себе возможности интернет-архива и поисковой системы.
Читать дальше…
В ближайшее время наша команда планирует запустить уникальный сервис, сочетающий в себе возможности интернет-архива и поисковой системы.
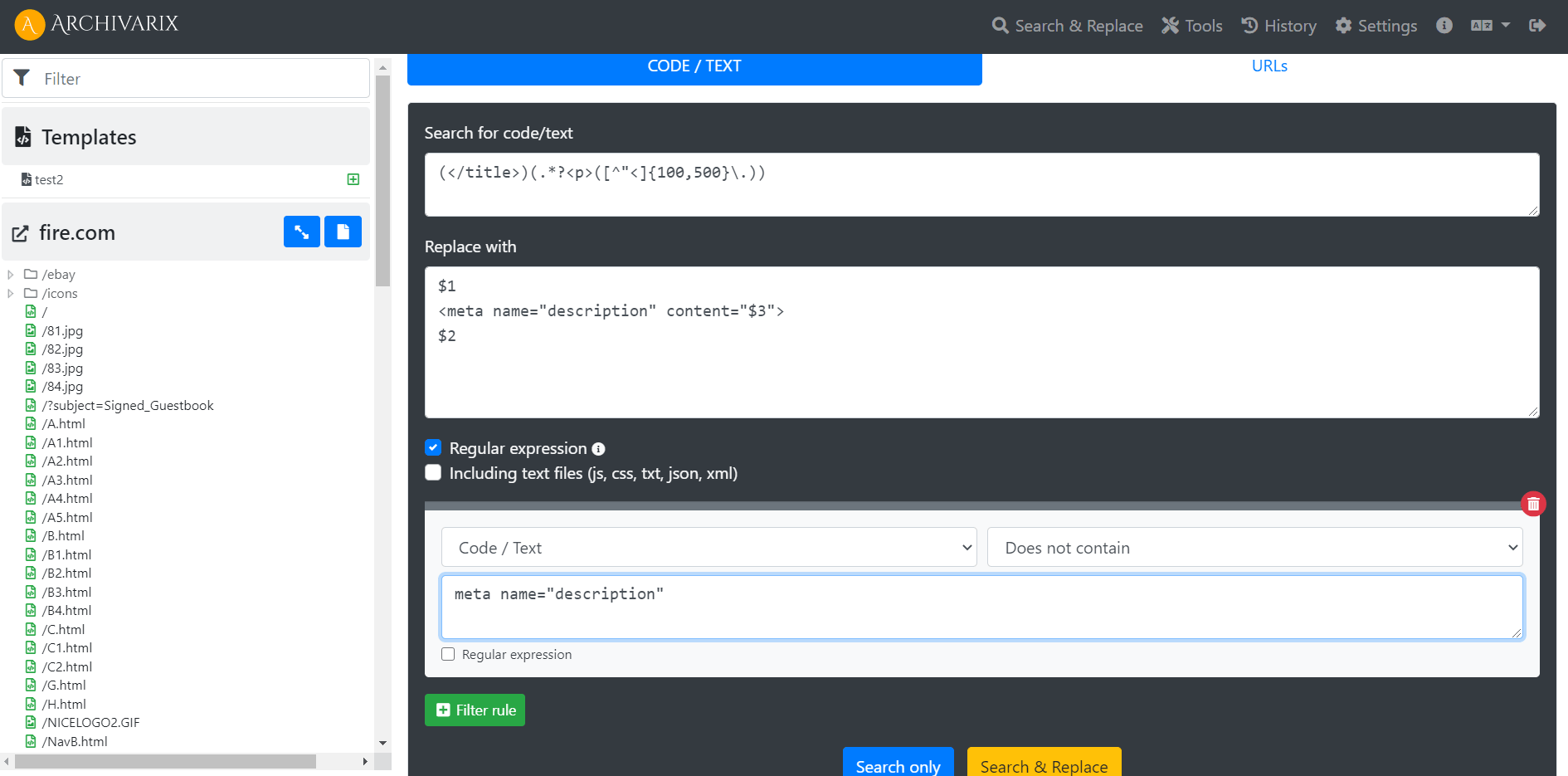
Примеры использование регулярных выражений в Archivarix CMS
Как генерировать метатег description на всех страницах сайта? Как сделать, так чтобы сайт работал не из корня, а из директории?
Читать дальше…

Как отобразить скрытые файлы в macOS
Как отобразить скрытые файлы в macOS. Отображение файлов начинающихся с точки, к примеру .htaсcess в macOS.
Читать дальше…
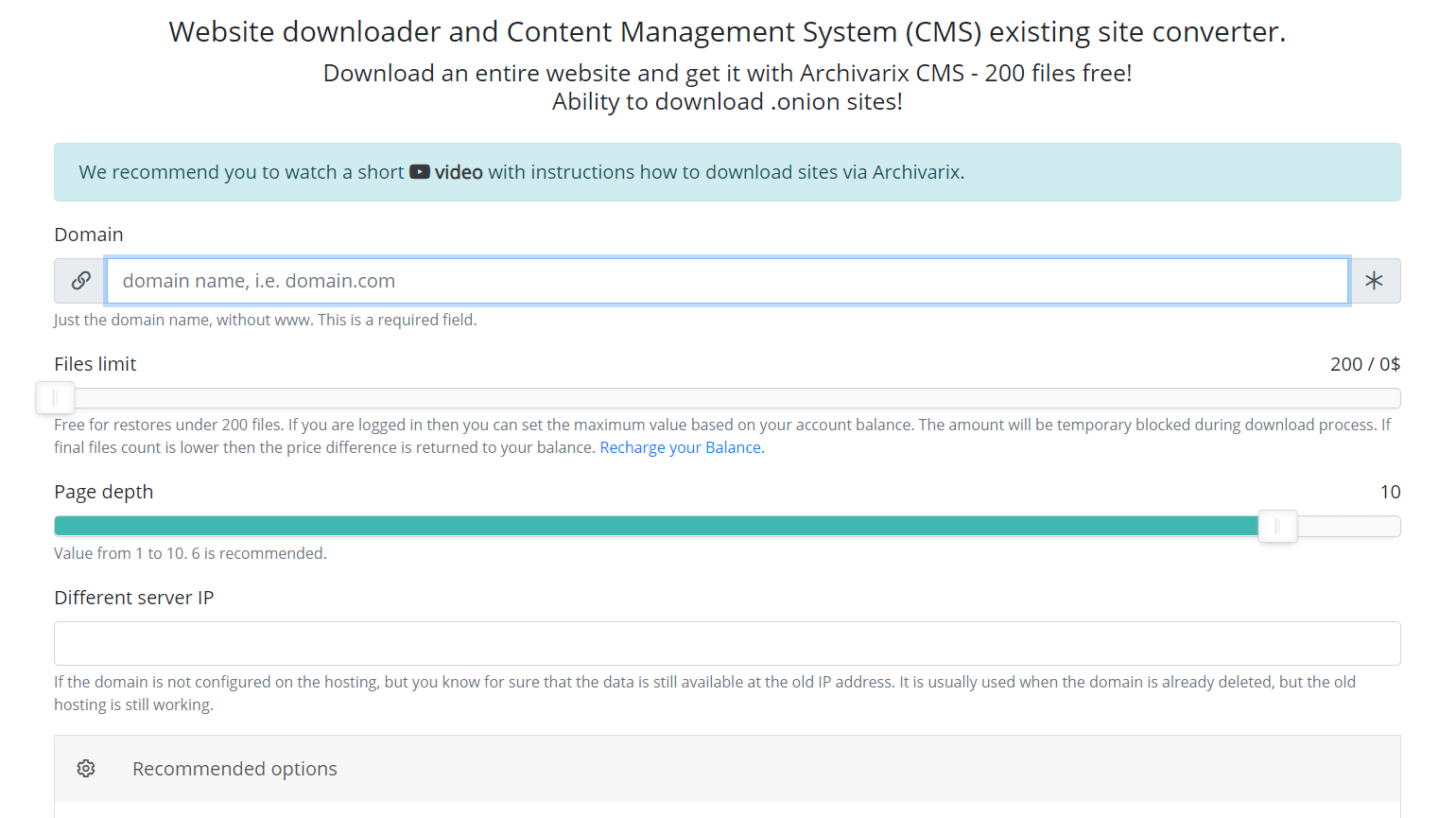
Система скачивания сайта. Как правильно выбрать количество файлов?
Наша система скачивания сайтов и конвертации их на нашу Archivarix CMS позволяет бесплатно скачивать до 200 файлов с сайта. Если на сайте файлов больше и все они нужны, то за эту услугу вы можете заплатить. Стоимость скачивания зависит от количества файлов. Как узнать сколько файлов действительно находится на сайте и сколько в итоге будет стоить скачать их всех?
Читать дальше…

Регулярные выражения, используемые в Archivarix CMS
В данной статье содержаться регулярные выражения, применяемые для поиска и замены в контенте сайтов, восстановленных с помощью системы Archivarix. Они не являются чем-то свойственным только этой системе. Если вы знаете регулярные выражения PHP, Perl, Java или других языков программирования, значит вы уже умеете пользоваться нашей системой поиска и замены. Если нет, то надеемся что эта статья вам поможет.
Читать дальше…
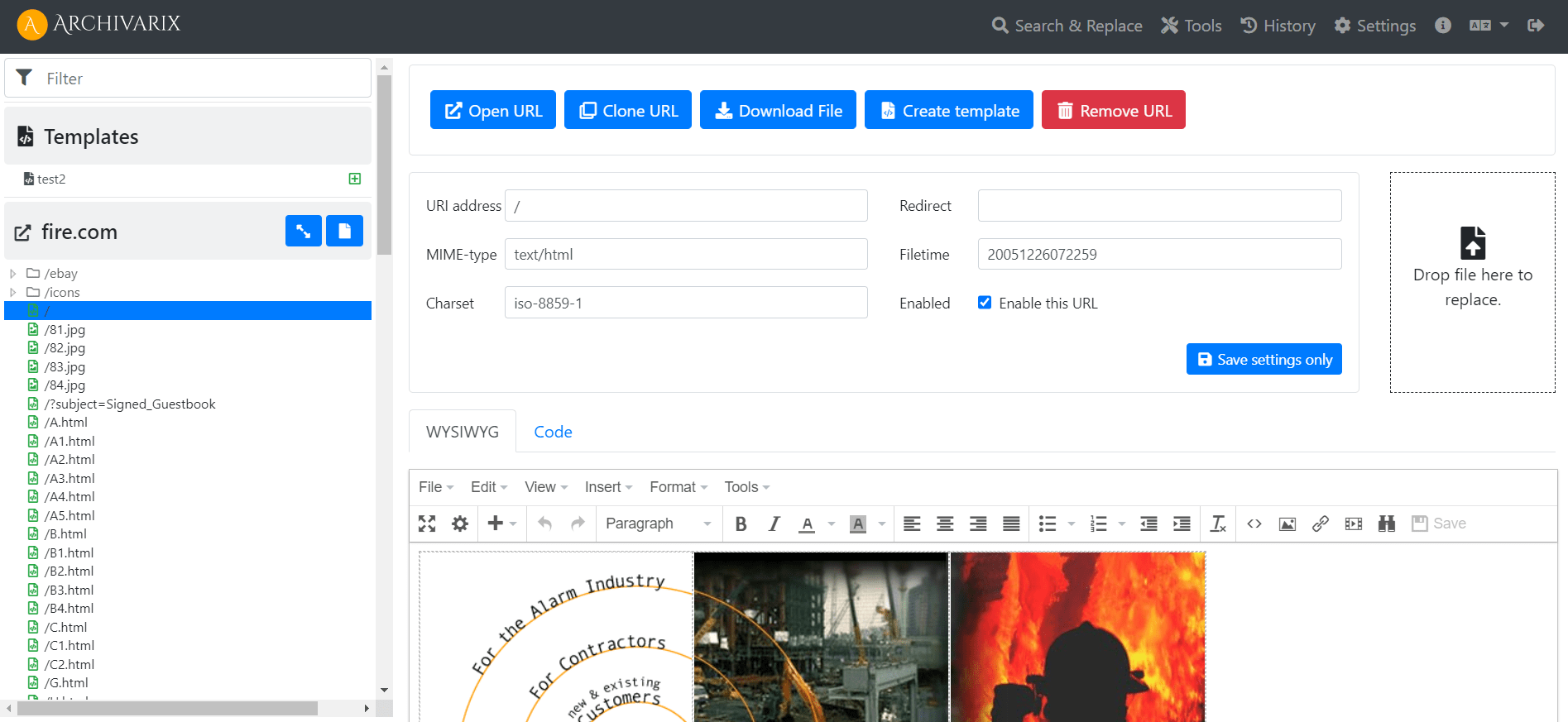
Простая и легкая Archivarix CMS. Редактор копированных сайтов.
Для того, чтобы вам было удобно редактировать восстановленные в нашей системе сайты, мы разработали простую Flat File CMS состоящую всего из одного небольшого файла. Не смотря на свой размер, эта CMS является мощным и универсальным инструментом для работы с вашими сайтами. В ней доступны все базовые возможности любой CMS, а так же специальные фишки для вебмастеров, создающих PBN на основе восстановленного из Веб Архива контента.
Читать дальше…
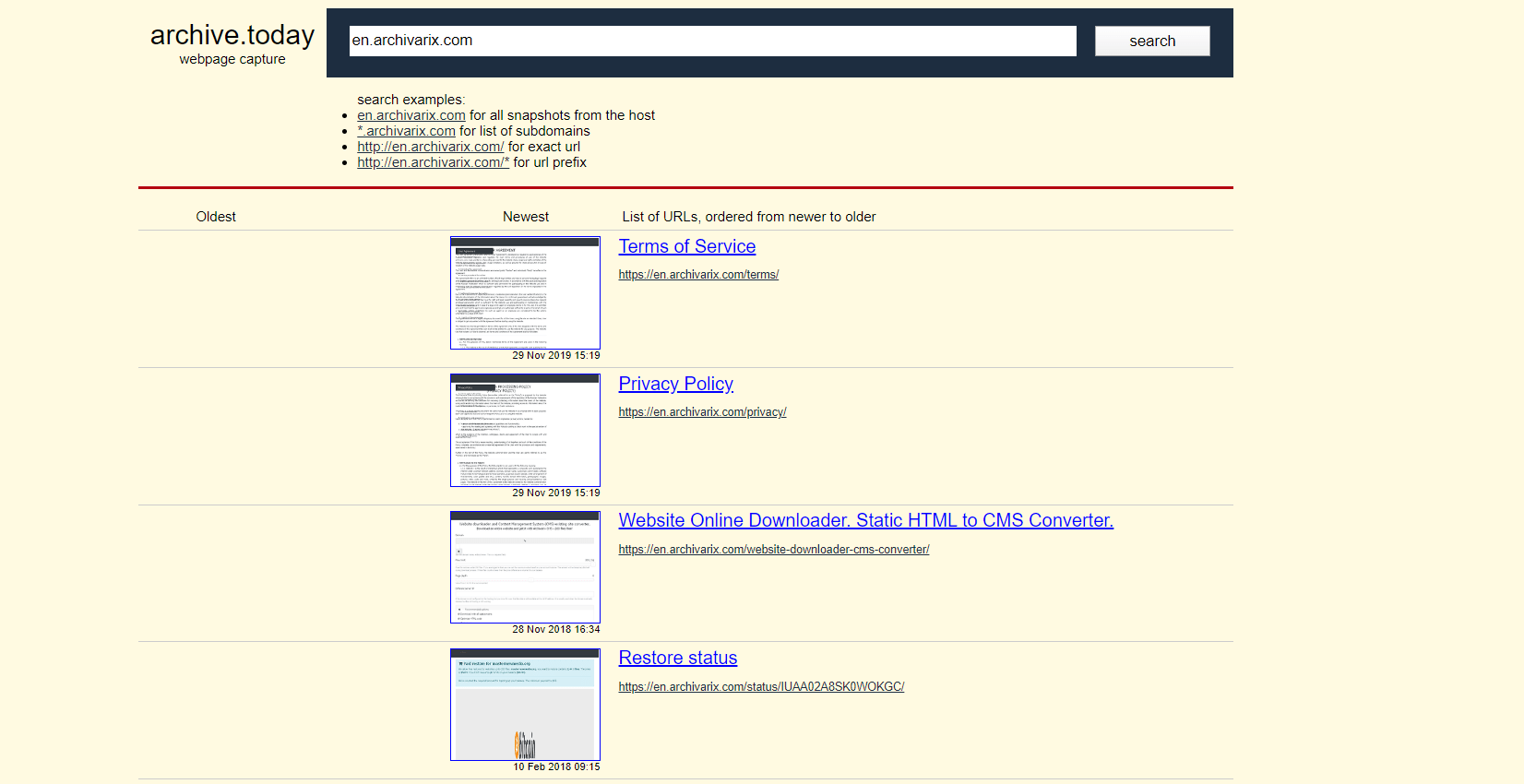
Аналоги web.archive.org. Как найти удаленные сайты?
Веб Архив ( Archive.org) - самый известный и самый большой архив сайтов в мире. На их серверах сейчас находится более 400 миллиардов страниц. Существуют ли какие-либо системы, аналогичные Archive.org?
Читать дальше…
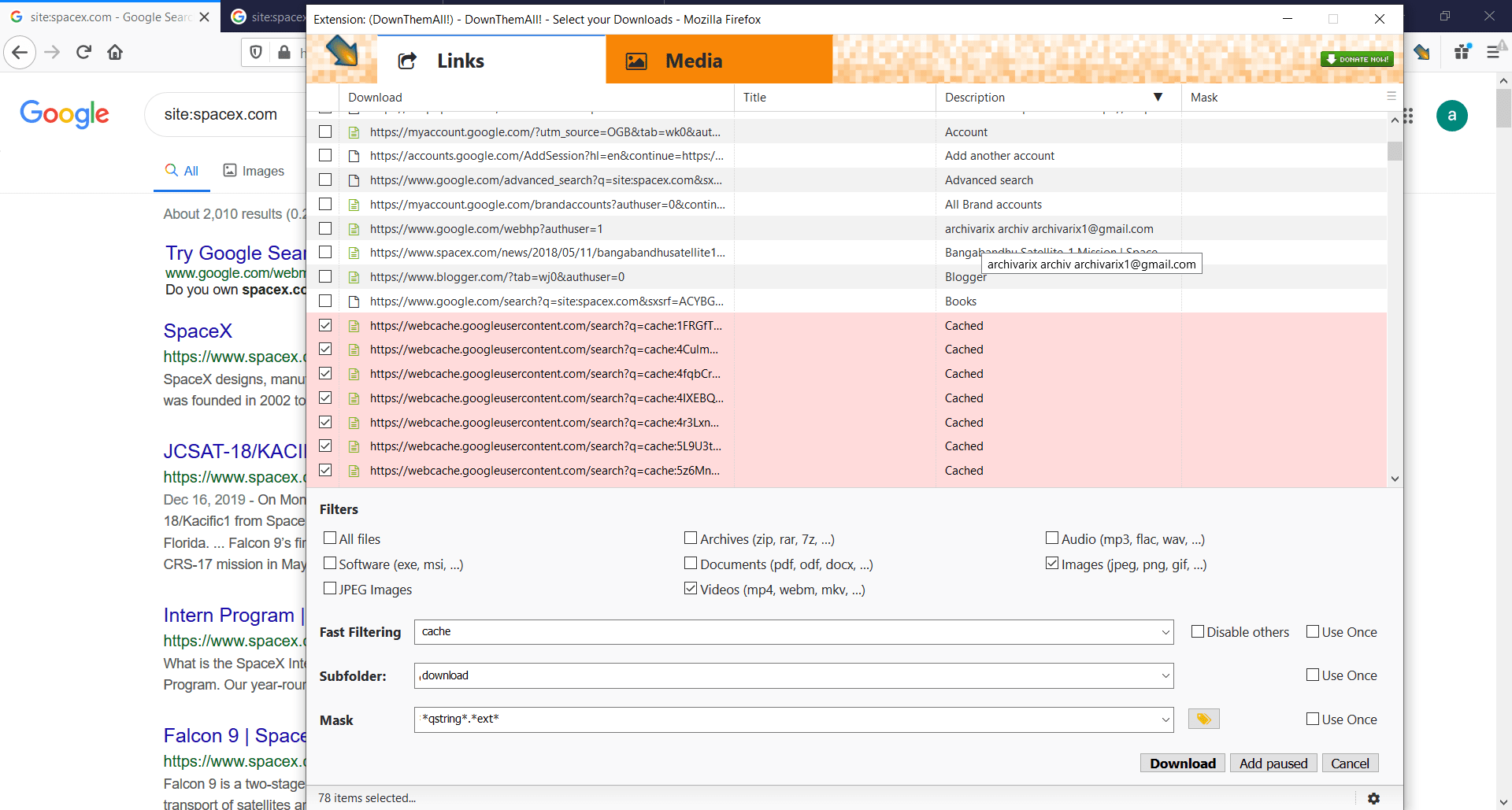
Как скачать сайт целиком из кэша Google?
Если нужный вам сайт был недавно удален, но Archive.org не сохранил последнюю версию, что можно сделать, чтобы получить его контент? Google Cache поможет это сделать. Все, что вам нужно, это установить вот такой плагин -
Читать дальше…
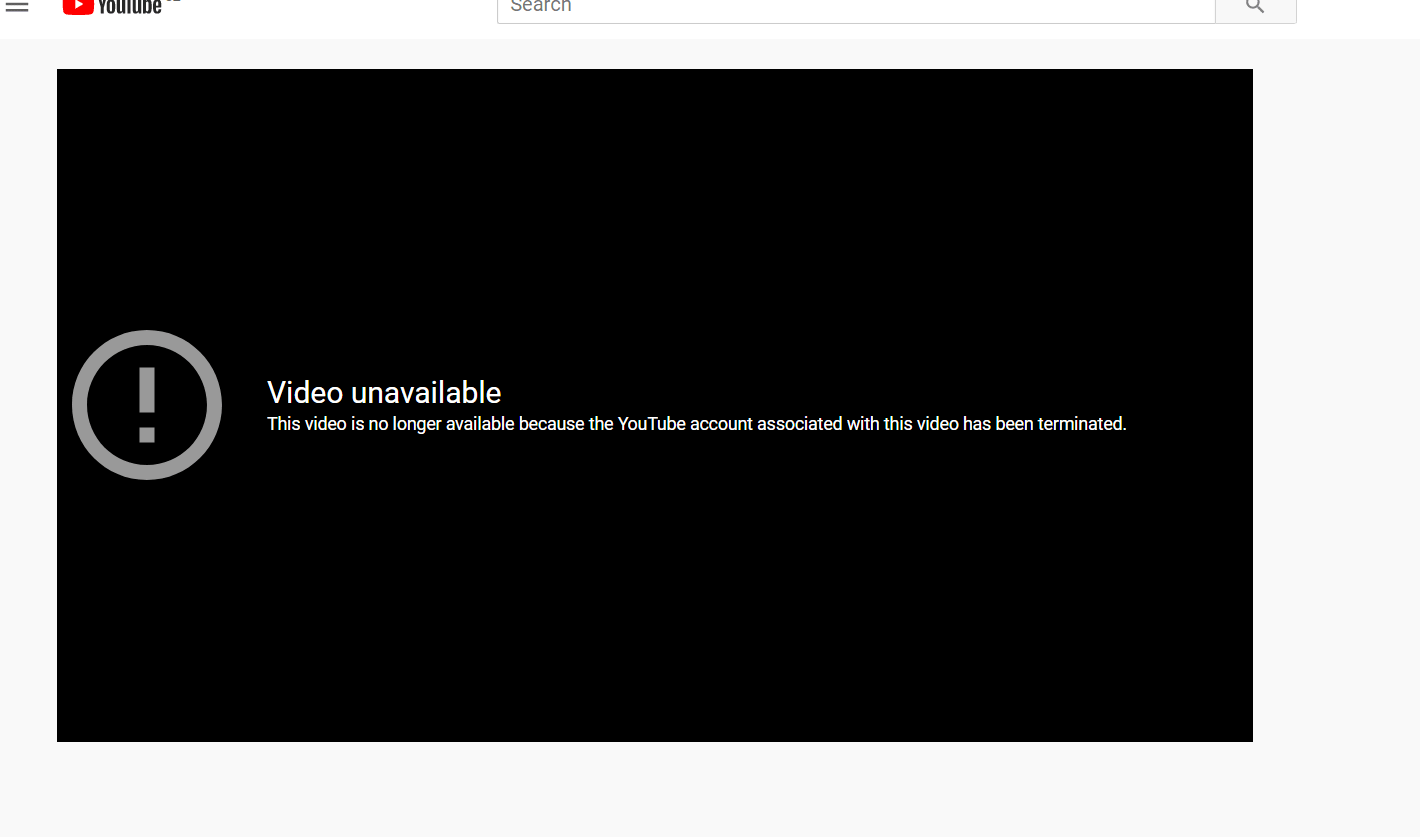
Как восстановить удаленные видео с YouTube?
Иногда вы можете увидеть это сообщение «Видео недоступно» на Youtube. Обычно это означает, что Youtube удалил это видео со своего сервера. Но есть простой способ, как получить его из Archive.org. Для начала вам нужна ссылка на видео с YouTube, она выглядит так: https://www.youtube.com/watch?v= 1vpS_-nN3JM Последние символы после watch?v= это код видео, который нам потребуется для восстановления.
Читать дальше…
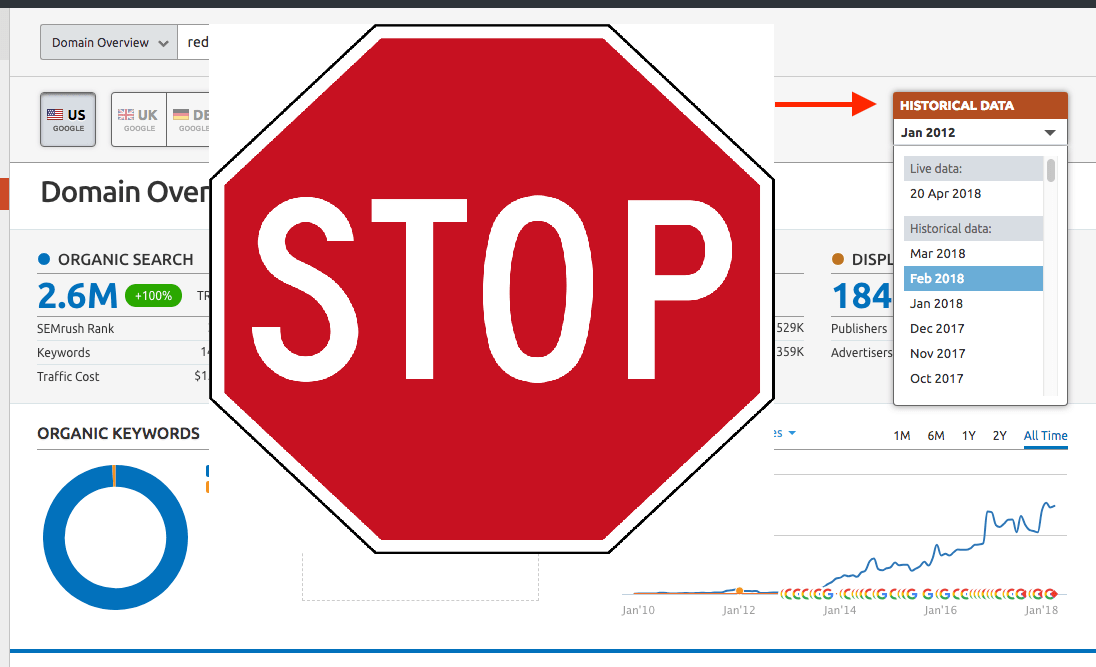
Как спрятать от конкурентов обратные ссылки?
Известно, что анализ обратных ссылок конкурентов является важной частью работы СЕО оптимизатора. Если вы делаете сетку PBN блогов, то возможно вам не особо хотелось чтобы другие вебмастера знали, где вы размещаете свои ссылки. Анализом ссылочной массы занимается большое количество сервисов, самые известные из них Majestic, Ahrefs, Semrush. У всех них есть свои боты, которых можно заблокировать.
Читать дальше…
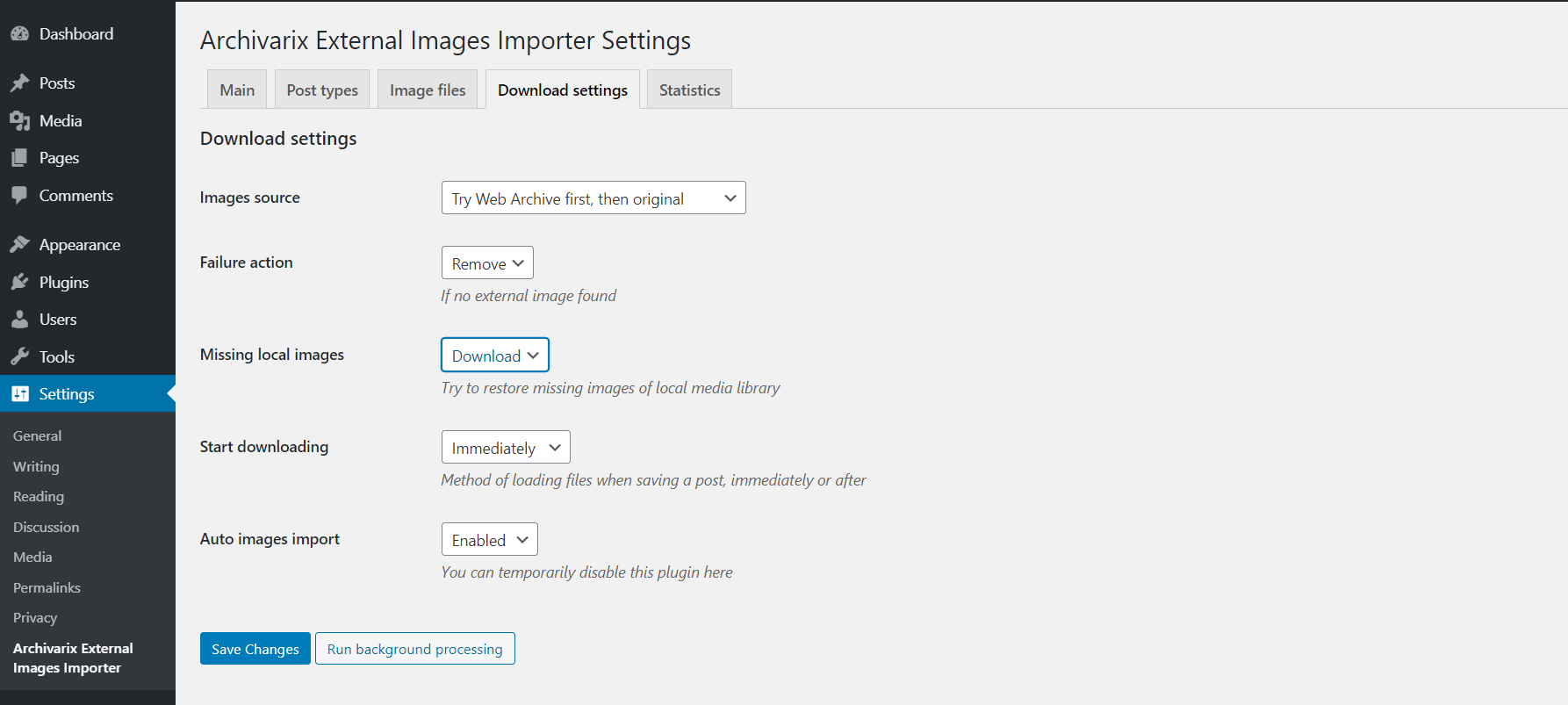
Как перенести контент из web.archive.org на Wordpress?
С помошью параметра "Извлечение структурированного контента" можно очень просто сделать Wordpress блог как из сайта, найденного в Веб Архиве, так и из любого другого сайта. Для этого находим сайт-источник, далее в инструменте Восстановить Сайт или Скачать сайт отмечаем опцию "Извлечь структурированный контент" и запускаем парсинг сайта.
Читать дальше…
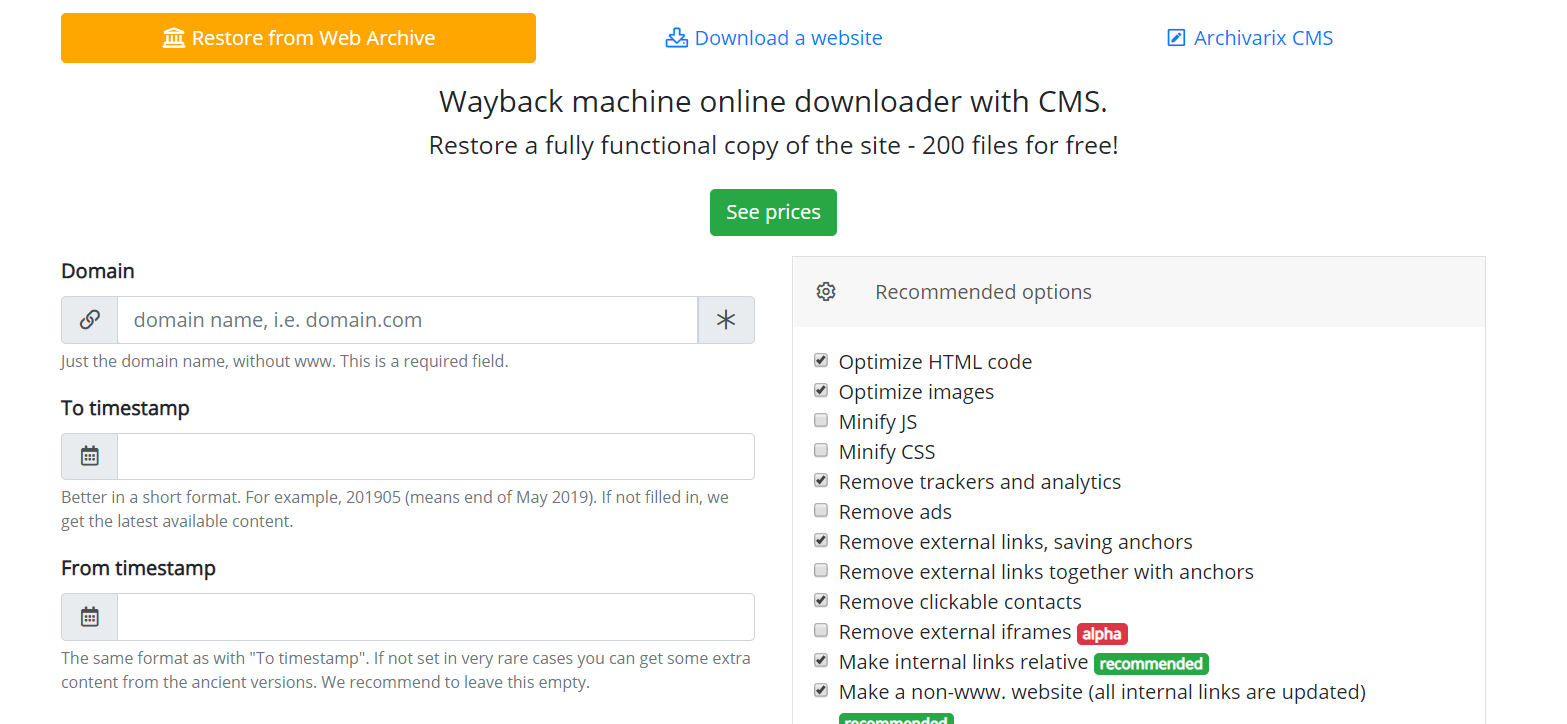
Как работает Архиварикс?
Система Архиварикс предназначена для скачивания и восстановления сайтов - как уже не работающих из Веб Архива, так и живых, находящихся в данный момент онлайн. В этом заключается ее основное отличие от прочих «качалок» и «парсеров сайтов». Задача Архиварикса - не только скачать, но и восстановить сайт в таком виде, в котором его можно будет использовать в дальнейшем на своем сервере.
Начнем с модуля, ответственного за скачивание сайтов из Веб Архива. Это виртуальные серверы, находящиеся в Калифорнии. Место расположения их было выбрано таким образом, чтобы получить максимально возможную скорость соединения с самим Веб Архивом, сервера которого расположены в Сан-Франциско. После ввода данных в соответствующих полях на странице модуля https://ru.archivarix.com/restore/ он делает скриншот архивного сайта и обращается к API Веб Архива с запросом списка файлов, содержащихся на указанную дату восстановления.
Читать дальше…
Начнем с модуля, ответственного за скачивание сайтов из Веб Архива. Это виртуальные серверы, находящиеся в Калифорнии. Место расположения их было выбрано таким образом, чтобы получить максимально возможную скорость соединения с самим Веб Архивом, сервера которого расположены в Сан-Франциско. После ввода данных в соответствующих полях на странице модуля https://ru.archivarix.com/restore/ он делает скриншот архивного сайта и обращается к API Веб Архива с запросом списка файлов, содержащихся на указанную дату восстановления.
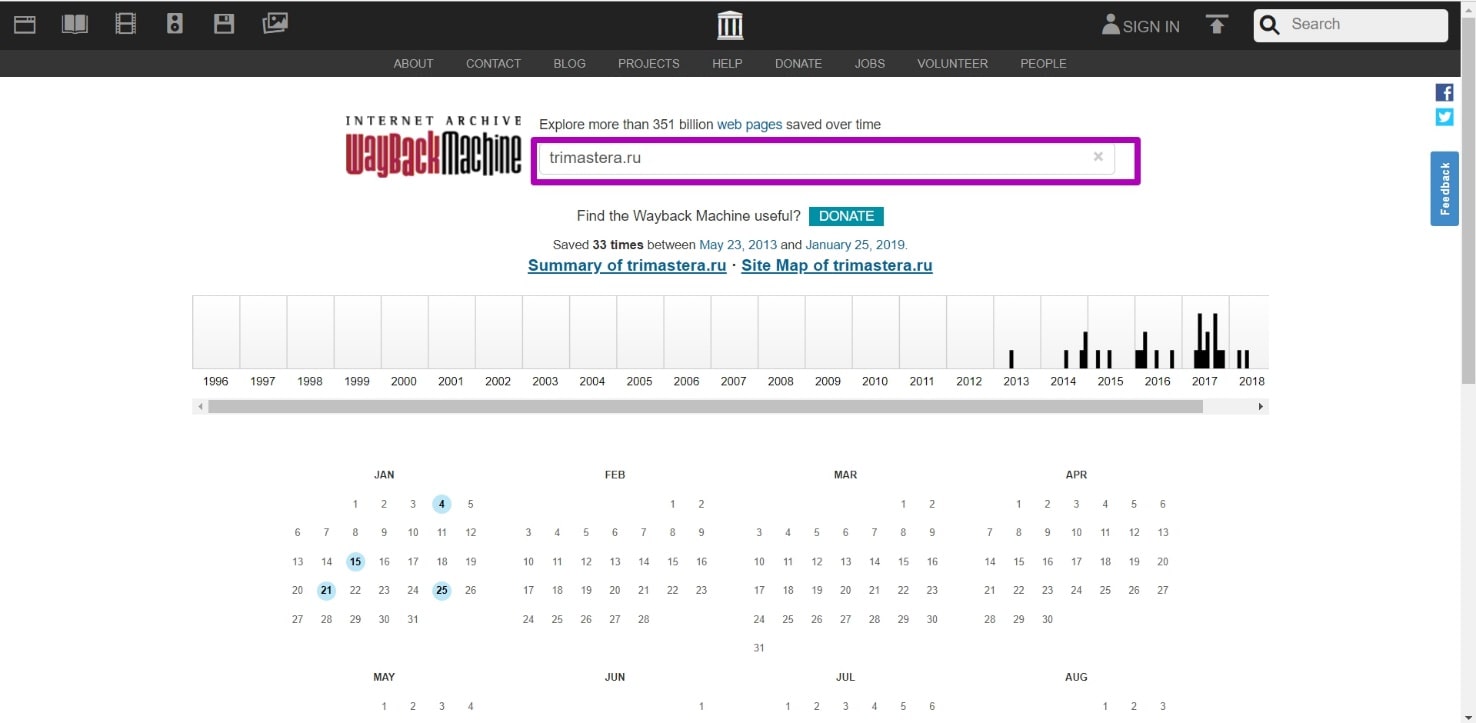
Как восстанавливать сайты из Веб Архива - archive.org. Часть 3
Выбор ограничения ДО при восстановлении сайтов из веб-архива. Когда домен заканчивается, на сайте может появится заглушка домен-провайдера или хостера. Перейдя на такую страницу, веб-архив будет ее сохранять, как полностью рабочую, отображая соответственную информацию в календаре. Если по такой дате из календаря восстановить сайт, то, вместо нормальной страницы мы получим ту самую заглушку. Как этого избежать и узнать дату работоспособности всех страниц сайта, по которой его можно восстановить?
Читать дальше…
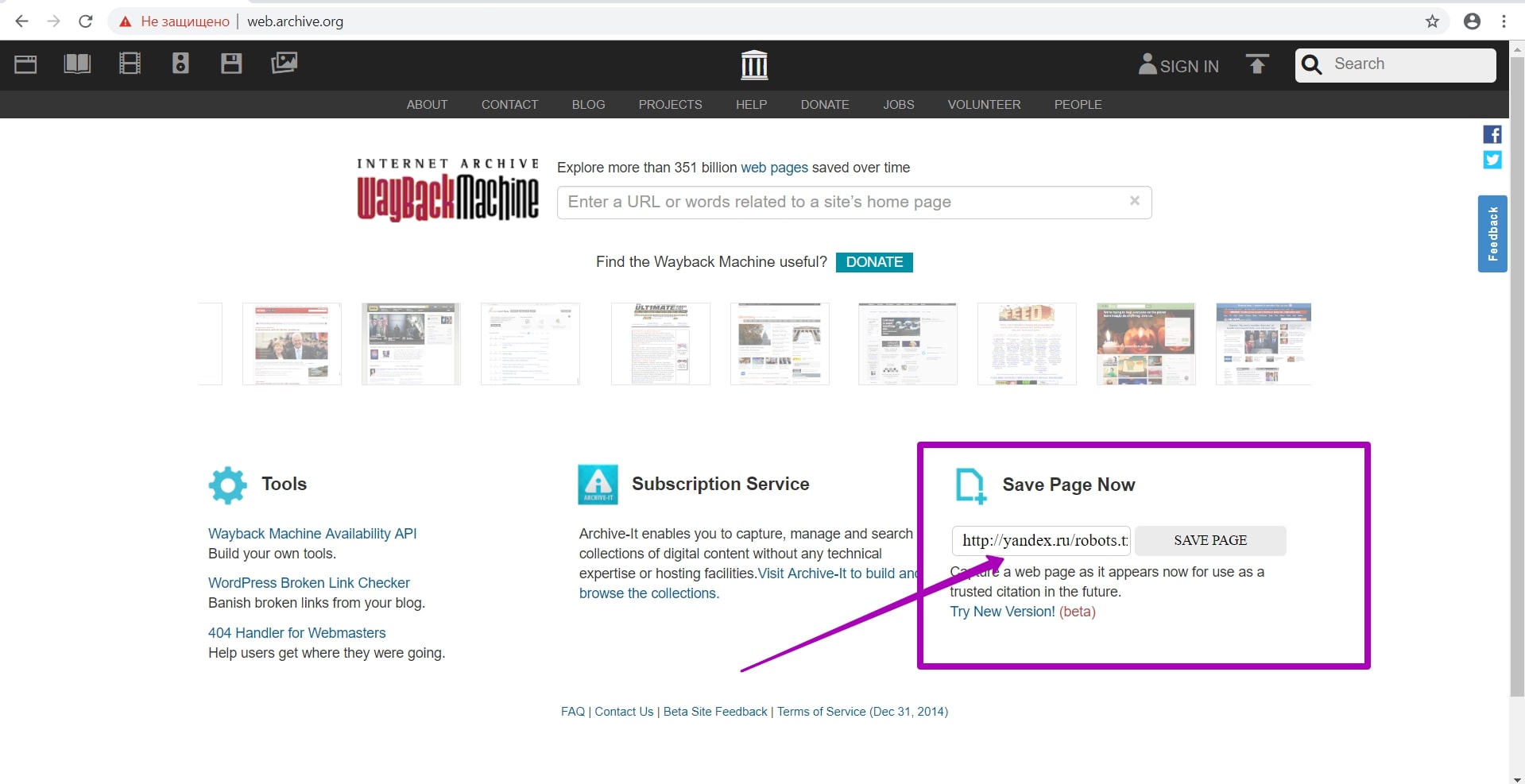
Как восстанавливать сайты из Веб Архива - archive.org. Часть 2
Подготовка домена к восстановлению. Создание robots.txt
В прошлой статье мы рассмотрели работу сервиса archive.org, а в этой статье речь пойдет об очень важном этапе восстановления сайта из веб-архива ― этапе подготовки домена к восстановлению. Именно этот шаг дает уверенность, что вы восстановите максимум контента на вашем сайте.
Читать дальше…
В прошлой статье мы рассмотрели работу сервиса archive.org, а в этой статье речь пойдет об очень важном этапе восстановления сайта из веб-архива ― этапе подготовки домена к восстановлению. Именно этот шаг дает уверенность, что вы восстановите максимум контента на вашем сайте.
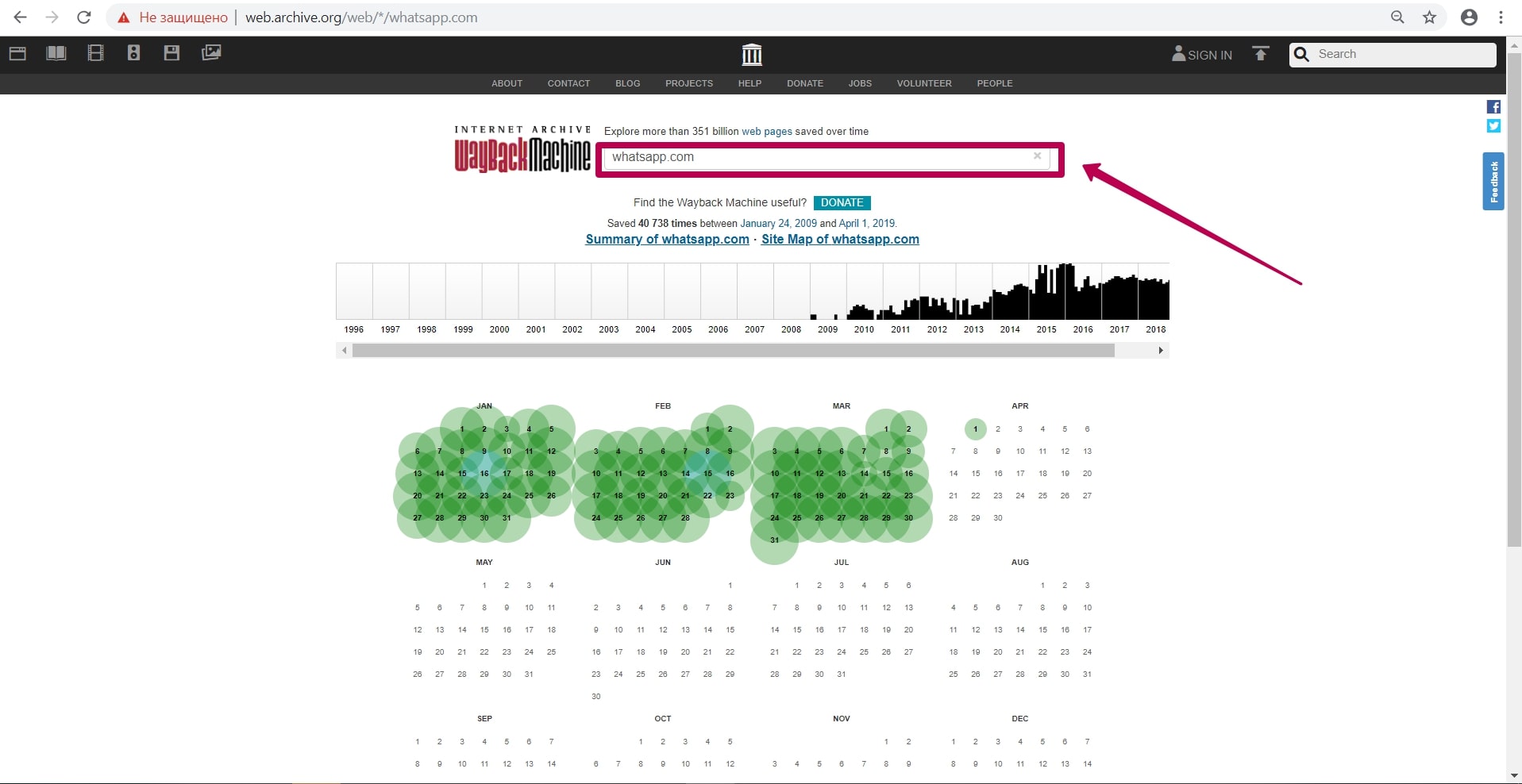
Как восстанавливать сайты из Веб Архива - archive.org. Часть 1
В этой статье мы расскажем о самом web.archive и о том, как он работает. Интерфейс веб-архива: инструкция к инструментам Summary, Explore и Site map. В этой статье мы расскажем о самом web.archive и о том, как он работает.
Читать дальше…
