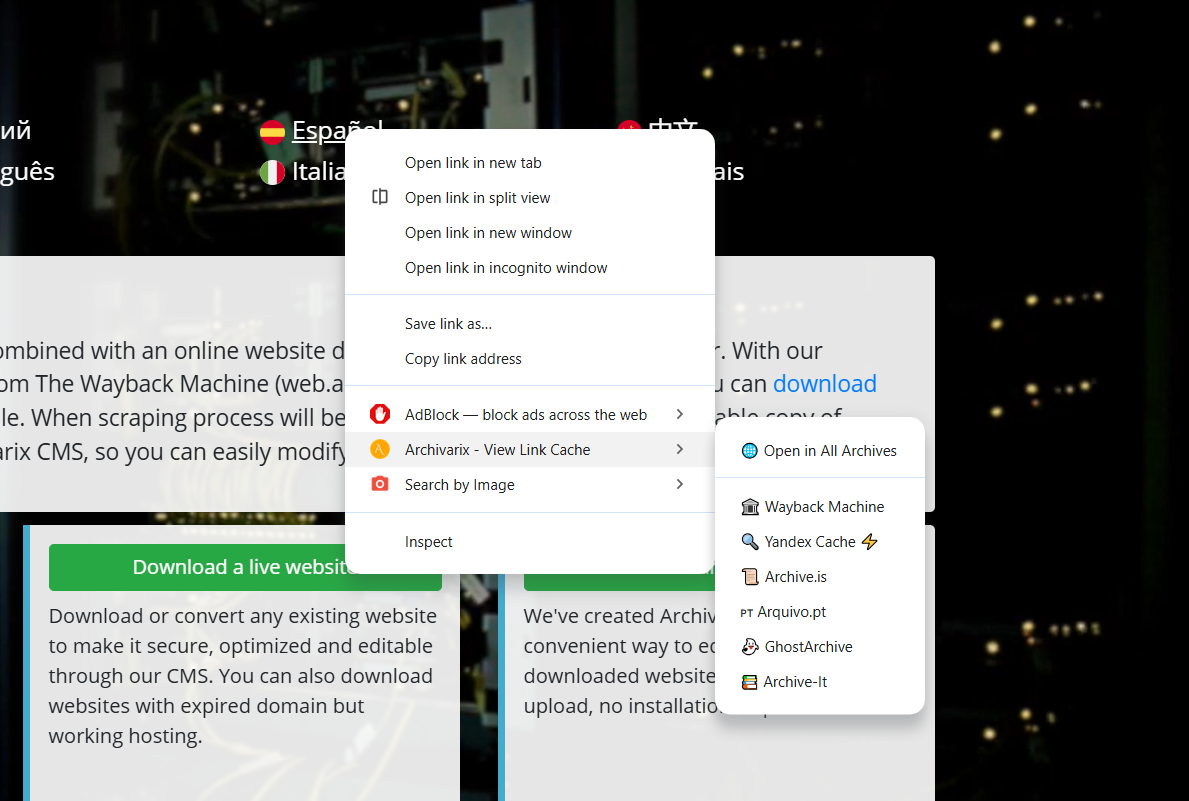
Extensión Archivarix Cache Viewer para Chrome y Firefox
Hemos lanzado una extensión de navegador llamada Archivarix Cache Viewer. Está disponible tanto para Chrome como para Firefox. La extensión es gratuita y no contiene ningún tipo de publicidad.
La idea es simple: acceso rápido a versiones en caché y archivadas de cualquier página web directamente desde el menú contextual del navegador. Se acabó copiar URLs manualmente, abrir Wayback Machine y pegar la dirección. Clic derecho, elige el archivo que necesitas, listo.
Leer más…
La idea es simple: acceso rápido a versiones en caché y archivadas de cualquier página web directamente desde el menú contextual del navegador. Se acabó copiar URLs manualmente, abrir Wayback Machine y pegar la dirección. Clic derecho, elige el archivo que necesitas, listo.
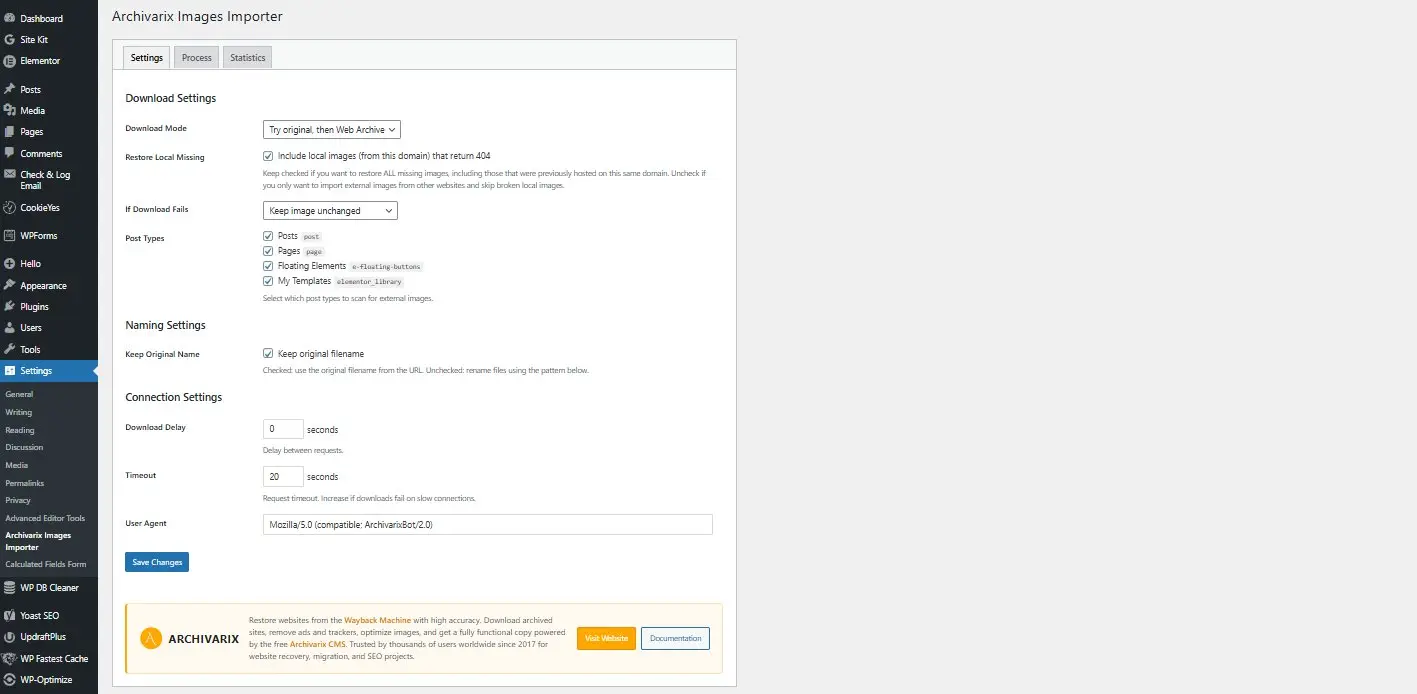
Archivarix External Images Importer 2.0 Nueva versión del plugin para WordPress
Nos complace presentar la versión 2.0 de nuestro plugin de WordPress para importar imágenes externas. Esto no es solo una actualización - el plugin ha sido completamente reescrito desde cero teniendo en cuenta los requisitos modernos y los comentarios de los usuarios.
Leer más…

Expresiones regulares utilizadas en Archivarix CMS
Este artículo describe expresiones regulares usadas para buscar y reemplazar contenido en sitios web restaurados usando el Sistema Archivarix. No son exclusivos de este sistema. Si conoce las expresiones regulares de PHP, Perl, Java u otros lenguajes de programación, entonces ya sabe cómo usar nuestra búsqueda y reemplazo. Si no, esperamos que este artículo te ayude.
Leer más…
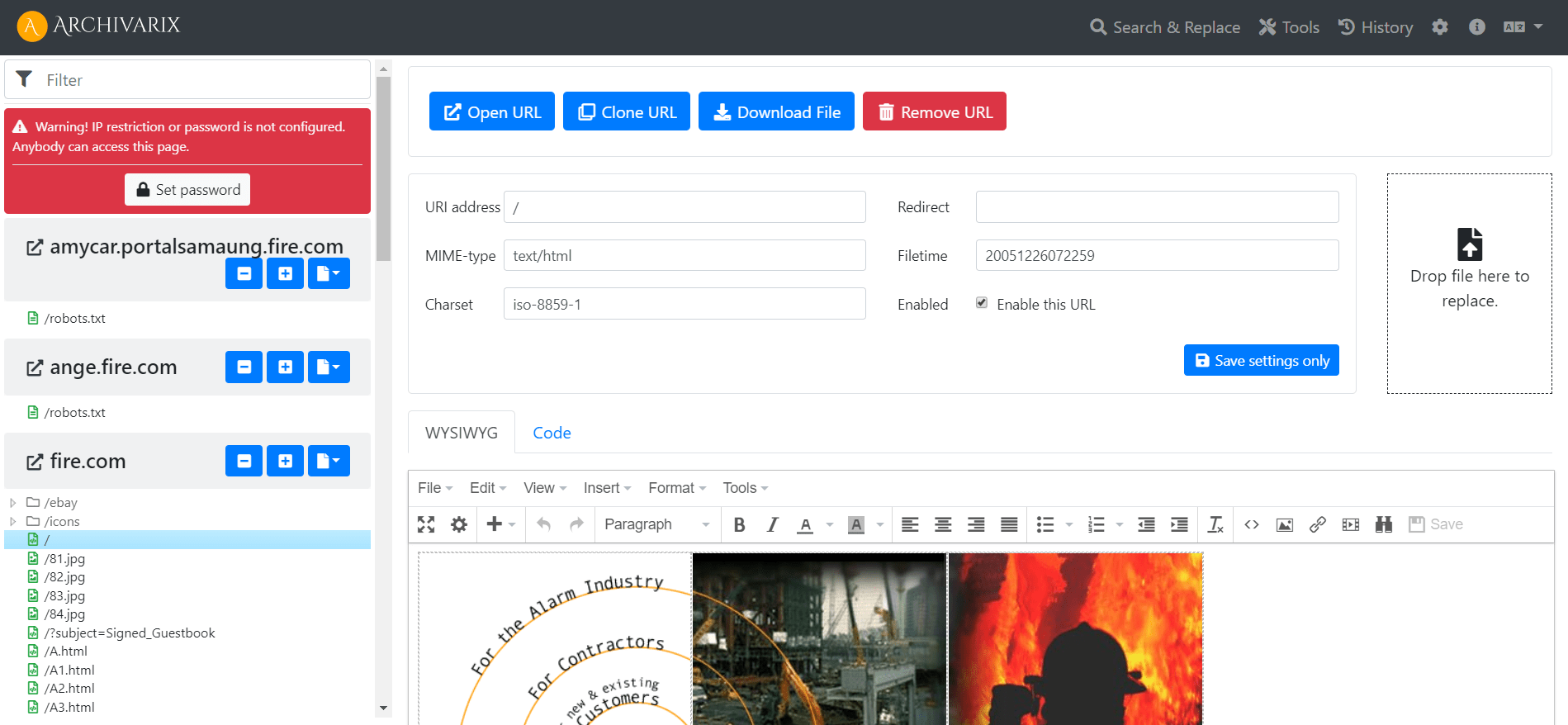
Simple y compacto Archivarix CMS. Archivo plano CMS para sitios web descargados.
Para que le resulte más cómodo editar los sitios web restaurados en nuestro sistema, hemos desarrollado un CMS de archivo plano simple que consta de un solo archivo php pequeño. A pesar de su tamaño, este CMS es una herramienta poderosa y versátil para trabajar con sus sitios. Todas las características básicas de cualquier CMS están disponibles en él, así como características especiales para los webmasters que crean PBN basados en el contenido restaurado desde el Archivo Web.
Leer más…
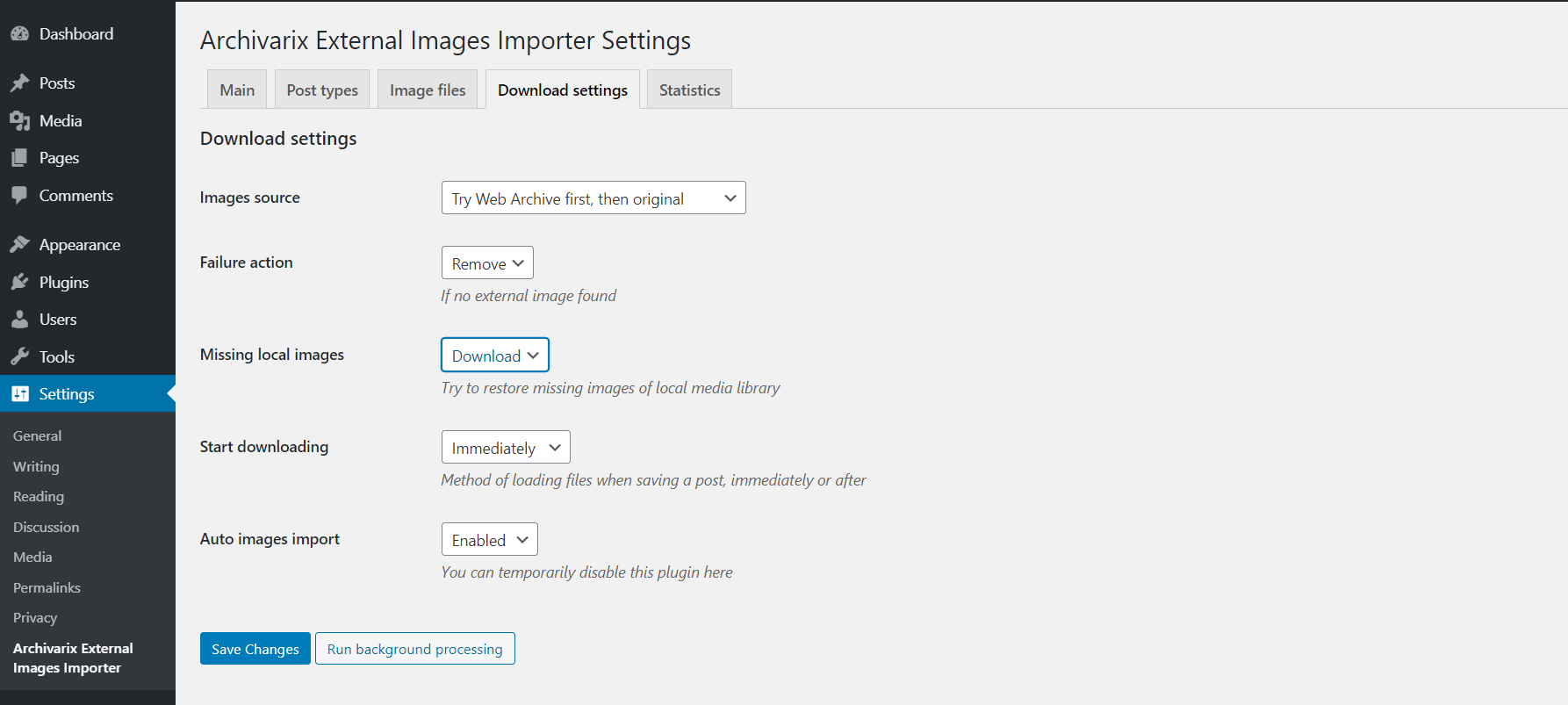
¿Cómo transferir contenido de Wayback Machine (archive.org) a Wordpress?
Al usar la opción "Extraer contenido estructurado", puede crear fácilmente un blog de Wordpress tanto desde el sitio que se encuentra en el Archivo Web como desde cualquier otro sitio. Para hacer esto, primero busque el sitio fuente y luego en la herramienta Restaurar un sitio web o Descargar un sitio web marque la opción "Extraer contenido estructurado". Ingrese sus opciones (correo electrónico, marcas de tiempo, etc.) y comience a descargar.
Leer más…
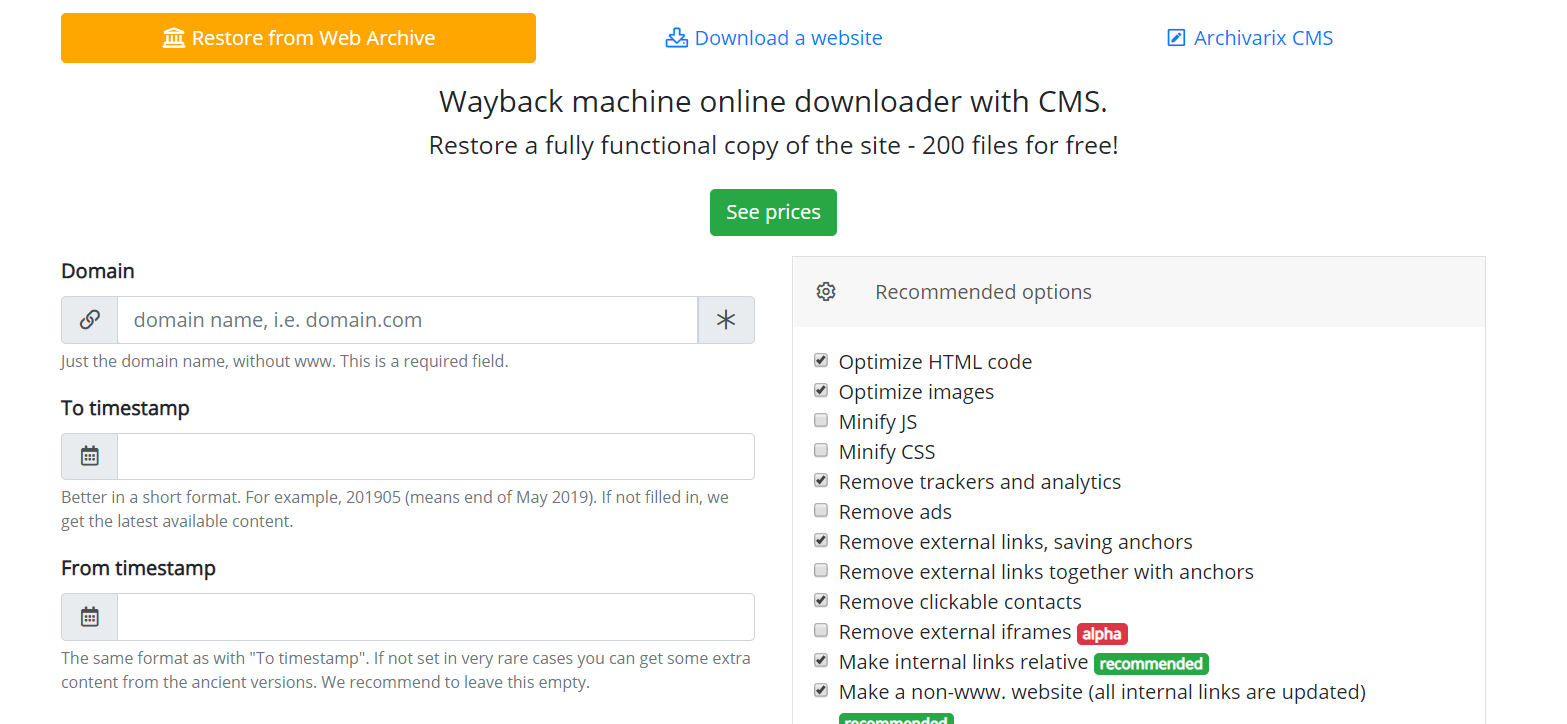
¿Cómo funciona Archivarix?
El sistema Archivarix está diseñado para descargar y restaurar sitios a los que ya no se puede acceder desde Web Archive y aquellos que están actualmente en línea. Esta es la principal diferencia del resto de "descargadores" y "analizadores de sitios". El objetivo de Archivarix no es solo descargar, sino también restaurar el sitio web de forma que esté accesible en su servidor.
Comencemos con el módulo que descarga sitios web de Web Archive. Estos son servidores virtuales ubicados en California. Su ubicación se eligió de tal manera que se obtuviera la máxima velocidad de conexión posible con el propio Archivo Web, porque sus servidores están ubicados en San Francisco. Después de ingresar datos en el campo apropiado en la página del módulo https://es.archivarix.com/restore/, toma una captura de pantalla del sitio web archivado y se dirige a la API de Web Archive para solicitar una lista de archivos contenidos en la fecha de recuperación especificada .
Leer más…
Comencemos con el módulo que descarga sitios web de Web Archive. Estos son servidores virtuales ubicados en California. Su ubicación se eligió de tal manera que se obtuviera la máxima velocidad de conexión posible con el propio Archivo Web, porque sus servidores están ubicados en San Francisco. Después de ingresar datos en el campo apropiado en la página del módulo https://es.archivarix.com/restore/, toma una captura de pantalla del sitio web archivado y se dirige a la API de Web Archive para solicitar una lista de archivos contenidos en la fecha de recuperación especificada .
