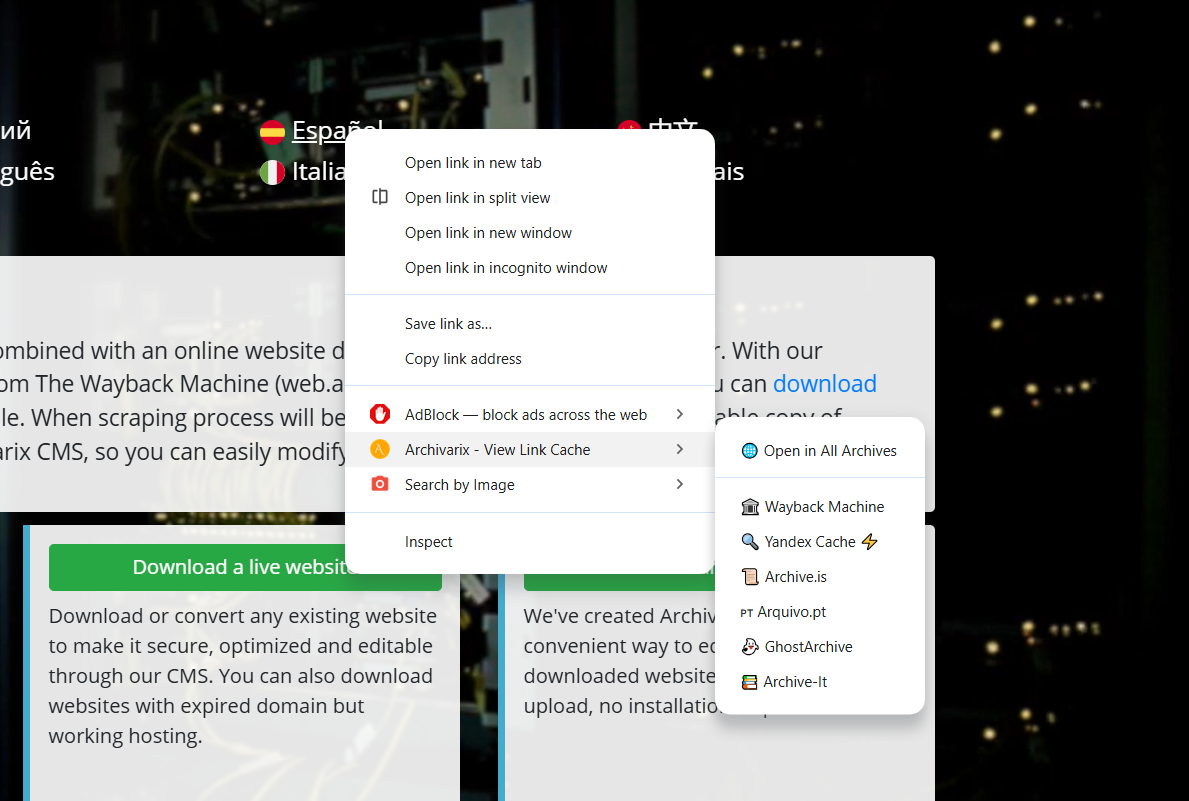
Extensão Archivarix Cache Viewer para Chrome e Firefox
Lançamos uma extensão de navegador chamada Archivarix Cache Viewer. Está disponível tanto para Chrome quanto para Firefox. A extensão é gratuita e não contém nenhuma publicidade.
A ideia é simples: acesso rápido a versões em cache e arquivadas de qualquer página web diretamente do menu de contexto do navegador. Chega de copiar URLs manualmente, abrir o Wayback Machine e colar o endereço lá. Clique com o botão direito, escolha o arquivo que precisa, pronto.
Leia mais…
A ideia é simples: acesso rápido a versões em cache e arquivadas de qualquer página web diretamente do menu de contexto do navegador. Chega de copiar URLs manualmente, abrir o Wayback Machine e colar o endereço lá. Clique com o botão direito, escolha o arquivo que precisa, pronto.
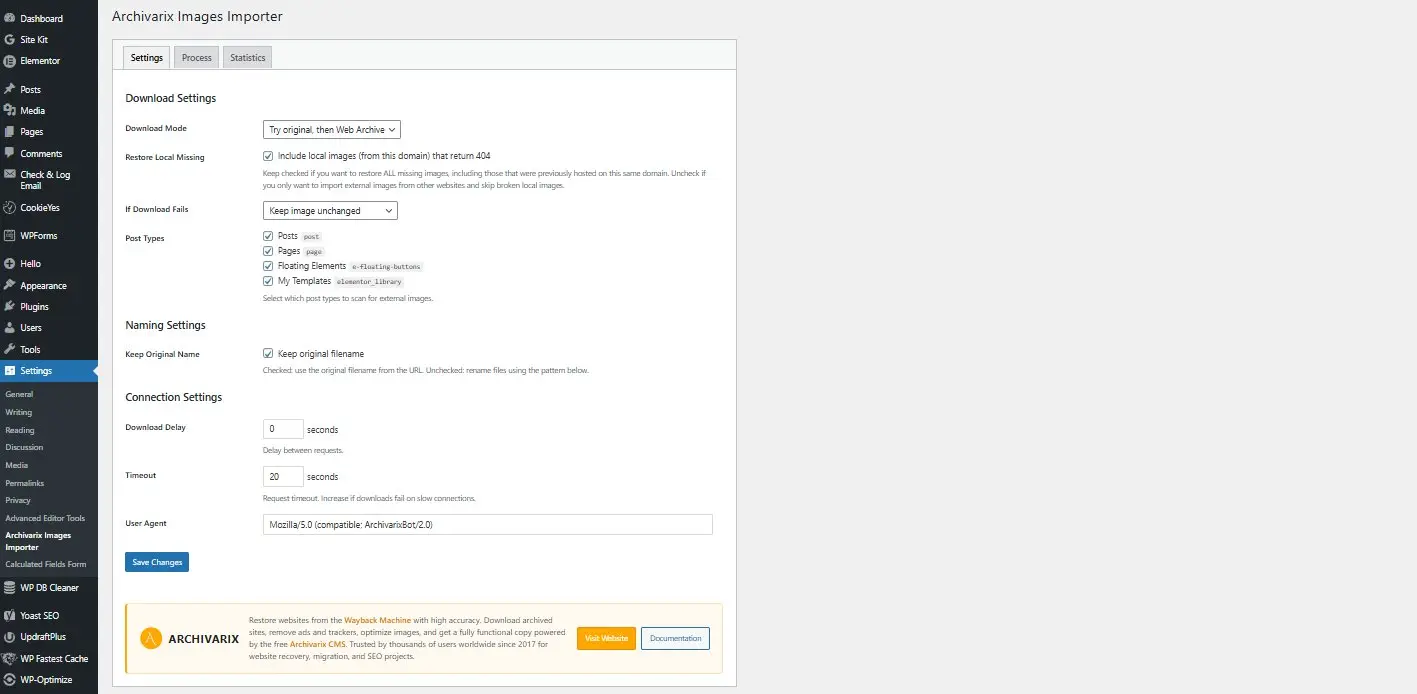
Archivarix External Images Importer 2.0 — Nova versão do plugin para WordPress
Temos o prazer de apresentar a versão 2.0 do nosso plugin WordPress para importação de imagens externas. Isso não é apenas uma atualização — o plugin foi completamente reescrito do zero com base nos requisitos modernos e no feedback dos usuários.
Leia mais…

Expressões regulares usadas no Archivarix CMS
Este artigo descreve expressões regulares usadas para procurar e substituir conteúdo em sites restaurados usando o Sistema Archivarix. Eles não são exclusivos para este sistema. Se você conhece as expressões regulares de PHP, Perl, Java ou outras linguagens de programação, já sabe como usar nossa pesquisa e substituição. Caso contrário, esperamos que este artigo o ajude.
Leia mais…
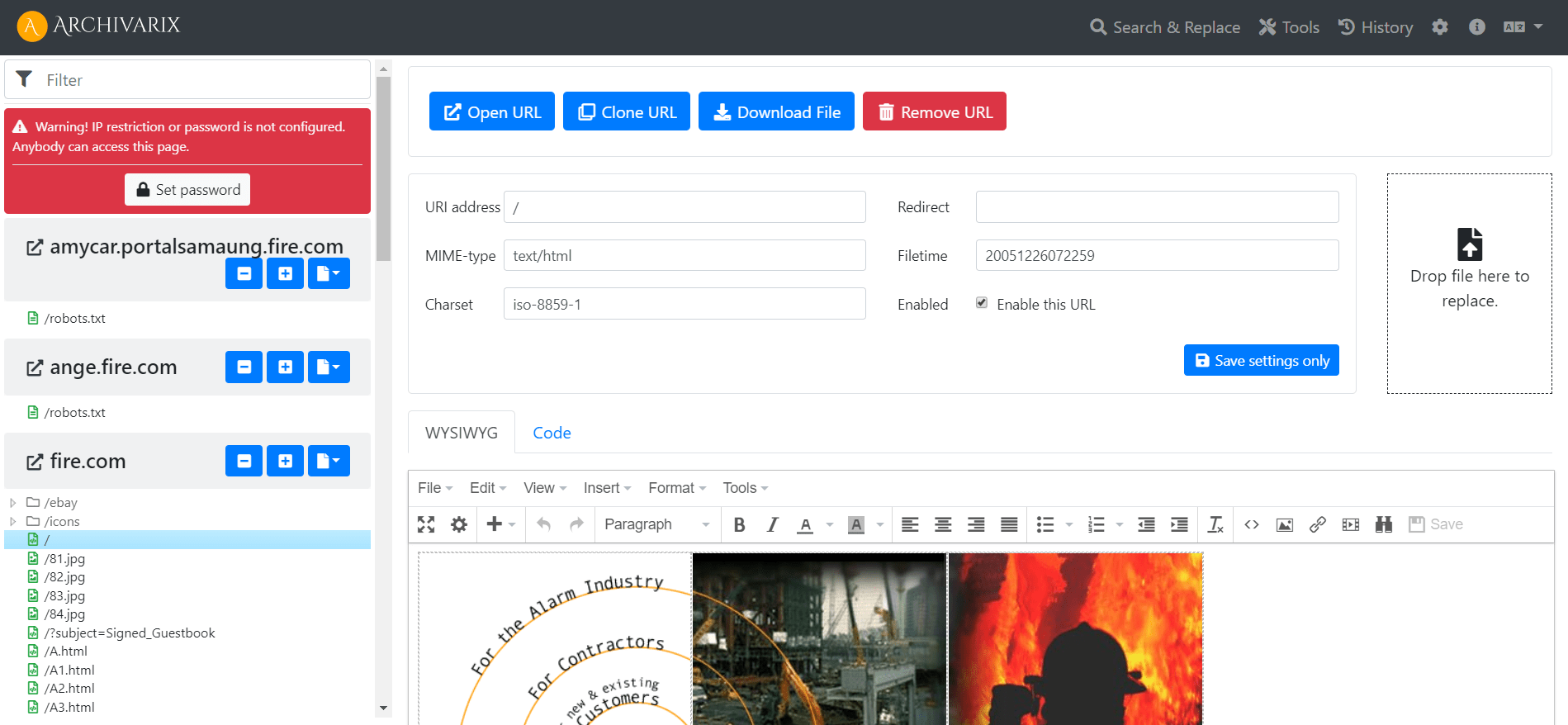
Archivarix CMS simples e compacto. CMS de arquivo simples para sites baixados.
Para facilitar a edição dos sites restaurados em nosso sistema, desenvolvemos um CMS de arquivo simples, que consiste em apenas um pequeno arquivo php. Apesar de seu tamanho, este CMS é uma ferramenta poderosa e versátil para trabalhar com seus sites. Todos os recursos básicos de qualquer CMS estão disponíveis, bem como recursos especiais para webmasters que criam PBNs com base no conteúdo restaurado do Web Archive.
Leia mais…
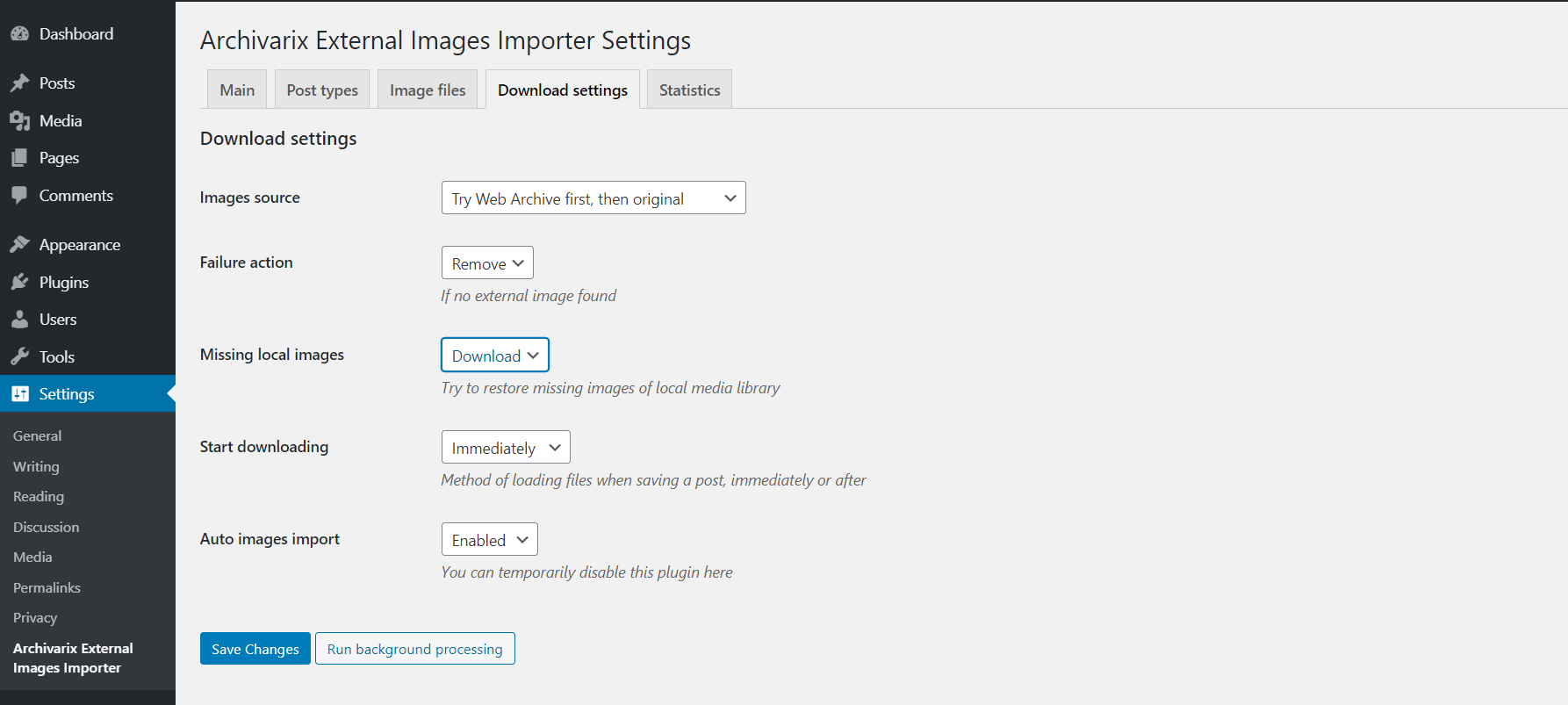
Como transferir conteúdo do Wayback Machine (archive.org) para o Wordpress?
Ao usar a opção “Extrair conteúdo estruturado”, você pode criar facilmente um blog Wordpress no site encontrado no Arquivo da Web e em qualquer outro site. Para fazer isso, primeiro encontre o site de origem e, em seguida, na ferramenta "Recuperar o site" ou "Baixar um site", marque a opção "Extrair conteúdo estruturado". Digite suas opções (email, timestamps, etc.) e comece o download.
Leia mais…
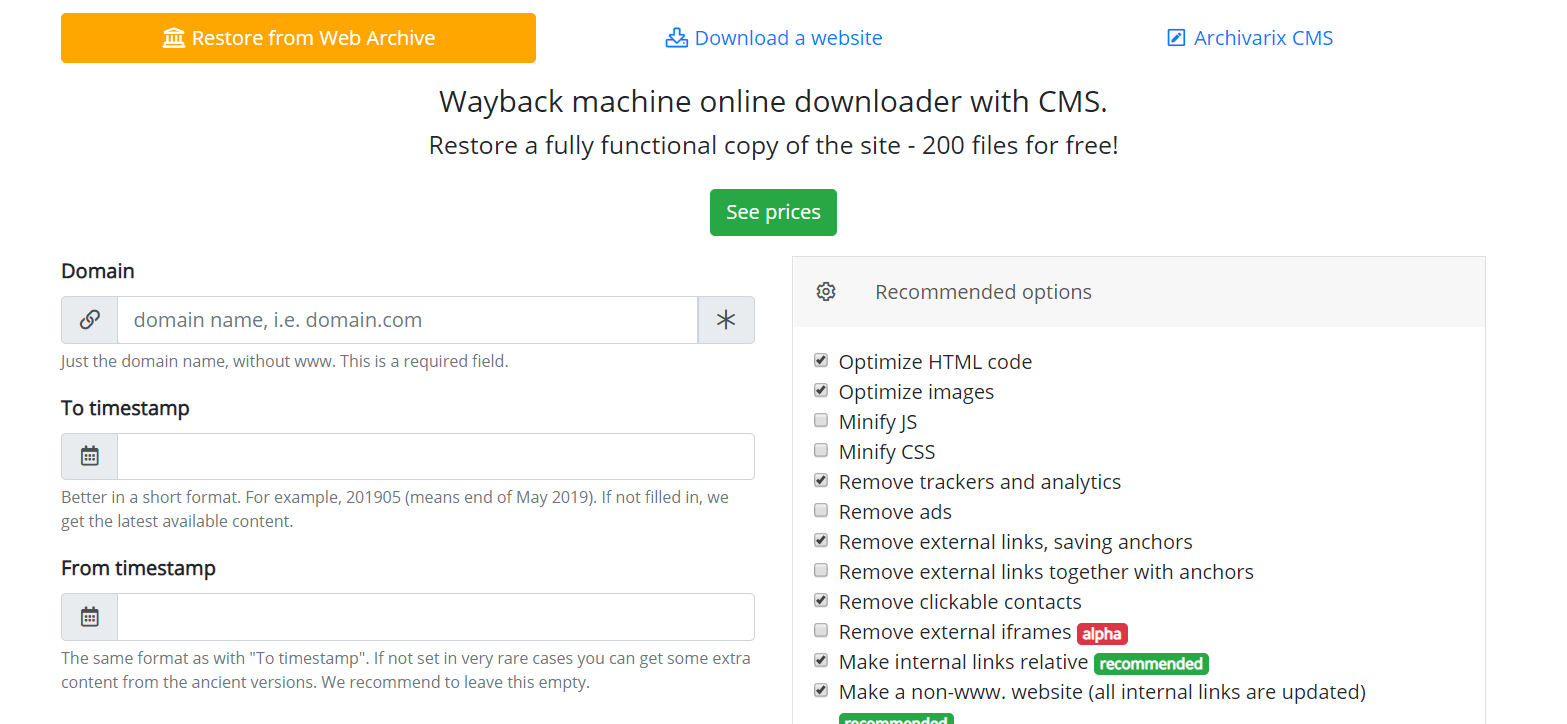
Como o Archivarix funciona?
O sistema Archivarix foi projetado para baixar e restaurar sites que não são mais acessíveis no Web Archive e aqueles que estão atualmente online. Essa é a principal diferença do restante dos "downloaders" e "site parsers". O objetivo do Archivarix não é apenas fazer o download, mas também restaurar o site de uma forma que seja acessível no seu servidor.
Vamos começar com o módulo que baixa sites da Web Archive. Estes são servidores virtuais localizados na Califórnia. Sua localização foi escolhida de forma a obter a velocidade máxima de conexão possível com o próprio Web Archive, porque seus servidores estão localizados em São Francisco. Depois de inserir dados no campo apropriado na página do módulo https://pt.archivarix.com/restore/, a captura de tela do site arquivado e endereça a API de arquivamento da Web para solicitar uma lista de arquivos contidos na data de recuperação especificada .
Leia mais…
Vamos começar com o módulo que baixa sites da Web Archive. Estes são servidores virtuais localizados na Califórnia. Sua localização foi escolhida de forma a obter a velocidade máxima de conexão possível com o próprio Web Archive, porque seus servidores estão localizados em São Francisco. Depois de inserir dados no campo apropriado na página do módulo https://pt.archivarix.com/restore/, a captura de tela do site arquivado e endereça a API de arquivamento da Web para solicitar uma lista de arquivos contidos na data de recuperação especificada .
