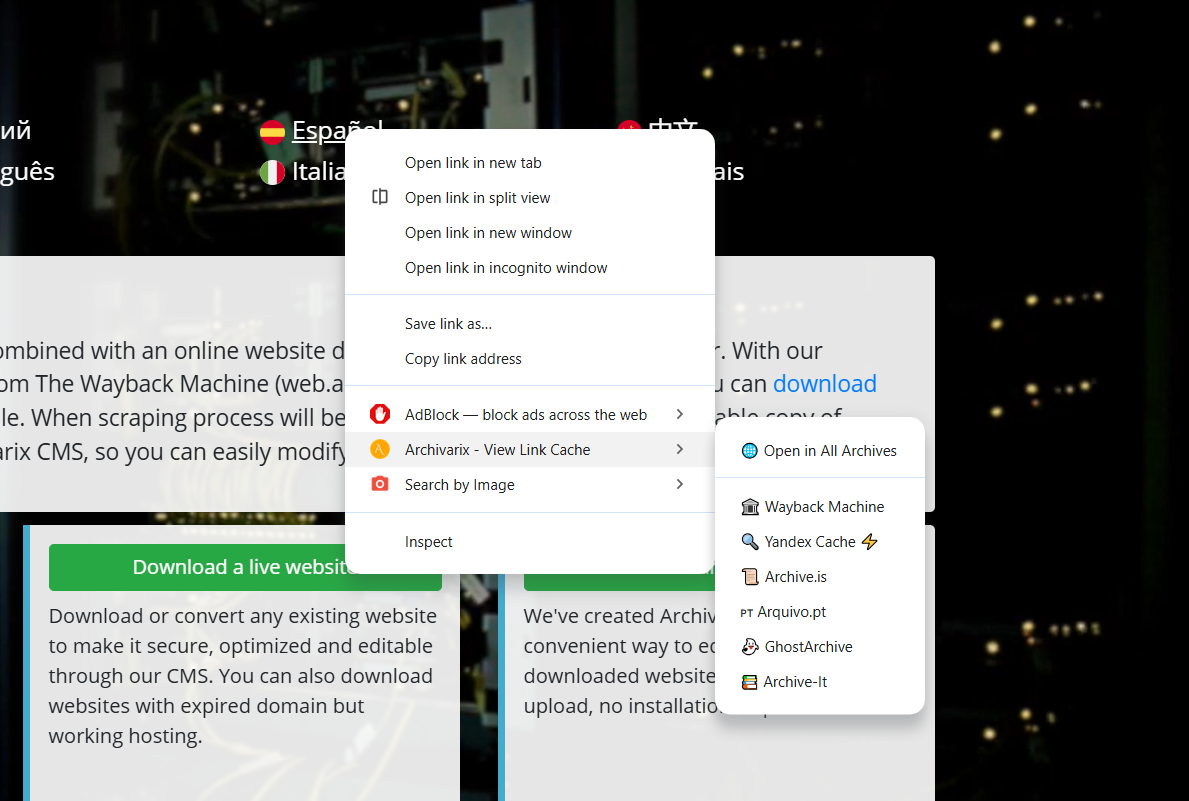
Rozszerzenie Archivarix Cache Viewer dla Chrome i Firefox
Wydaliśmy rozszerzenie przeglądarki o nazwie Archivarix Cache Viewer. Jest dostępne zarówno dla Chrome, jak i Firefox. Rozszerzenie jest darmowe i nie zawiera żadnych reklam.
Idea jest prosta: szybki dostęp do zbuforowanych i zarchiwizowanych wersji dowolnej strony internetowej bezpośrednio z menu kontekstowego przeglądarki. Koniec z ręcznym kopiowaniem adresów URL, otwieraniem Wayback Machine i wklejaniem tam adresu. Kliknij prawym przyciskiem, wybierz potrzebne archiwum, gotowe.
Czytaj dalej…
Idea jest prosta: szybki dostęp do zbuforowanych i zarchiwizowanych wersji dowolnej strony internetowej bezpośrednio z menu kontekstowego przeglądarki. Koniec z ręcznym kopiowaniem adresów URL, otwieraniem Wayback Machine i wklejaniem tam adresu. Kliknij prawym przyciskiem, wybierz potrzebne archiwum, gotowe.
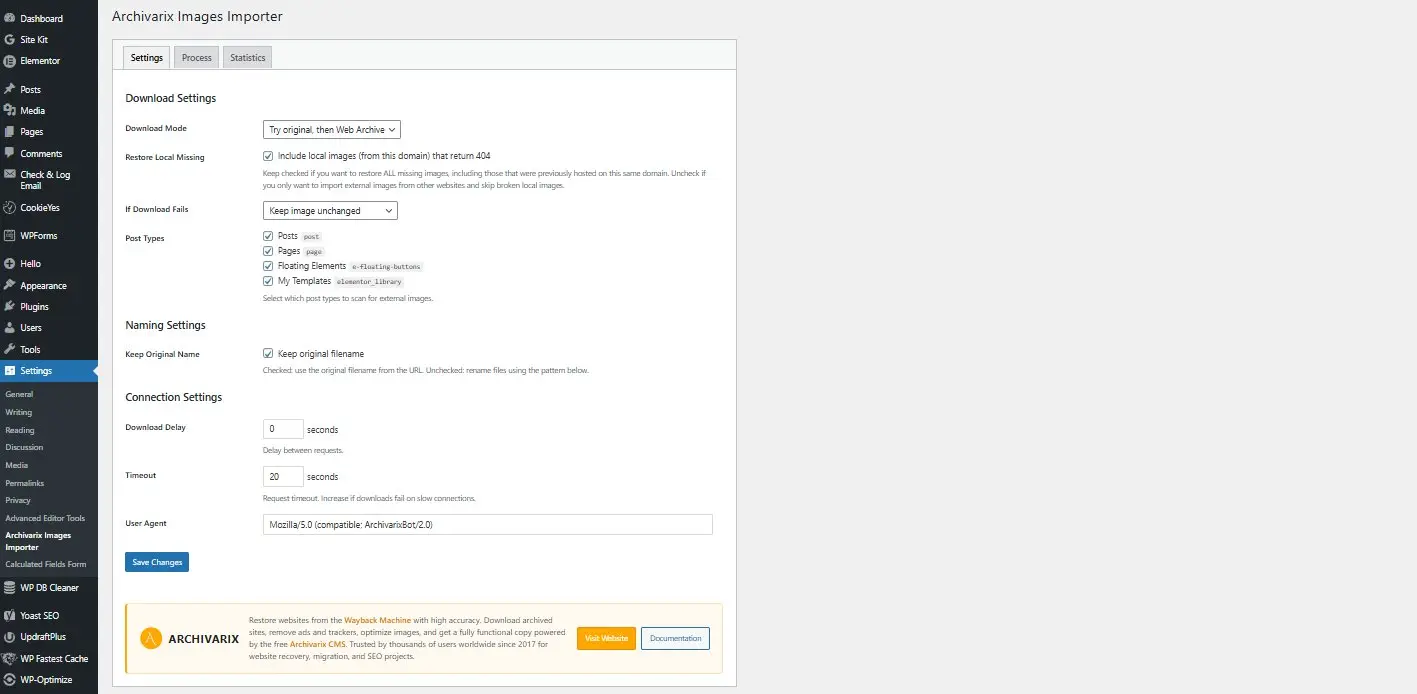
Archivarix External Images Importer 2.0 — Nowa wersja wtyczki dla WordPress
Z przyjemnością przedstawiamy wersję 2.0 naszej wtyczki WordPress do importowania zewnętrznych obrazów. To nie tylko aktualizacja — wtyczka została całkowicie przepisana od zera z uwzględnieniem nowoczesnych wymagań i opinii użytkowników.
Czytaj dalej…

Wyrażenia regularne używane w Archivarix CMS
W tym artykule opisano wyrażenia regularne używane do wyszukiwania i zastępowania treści na stronach internetowych przywróconych za pomocą systemu Archivarix. Nie są one unikalne dla tego systemu. Jeśli znasz wyrażenia regularne PHP, Perl, Java lub innych języków programowania, to wiesz już, jak korzystać z naszego wyszukiwania i zamieniać. Jeśli nie, mamy nadzieję, że ten artykuł Ci pomoże.
Czytaj dalej…
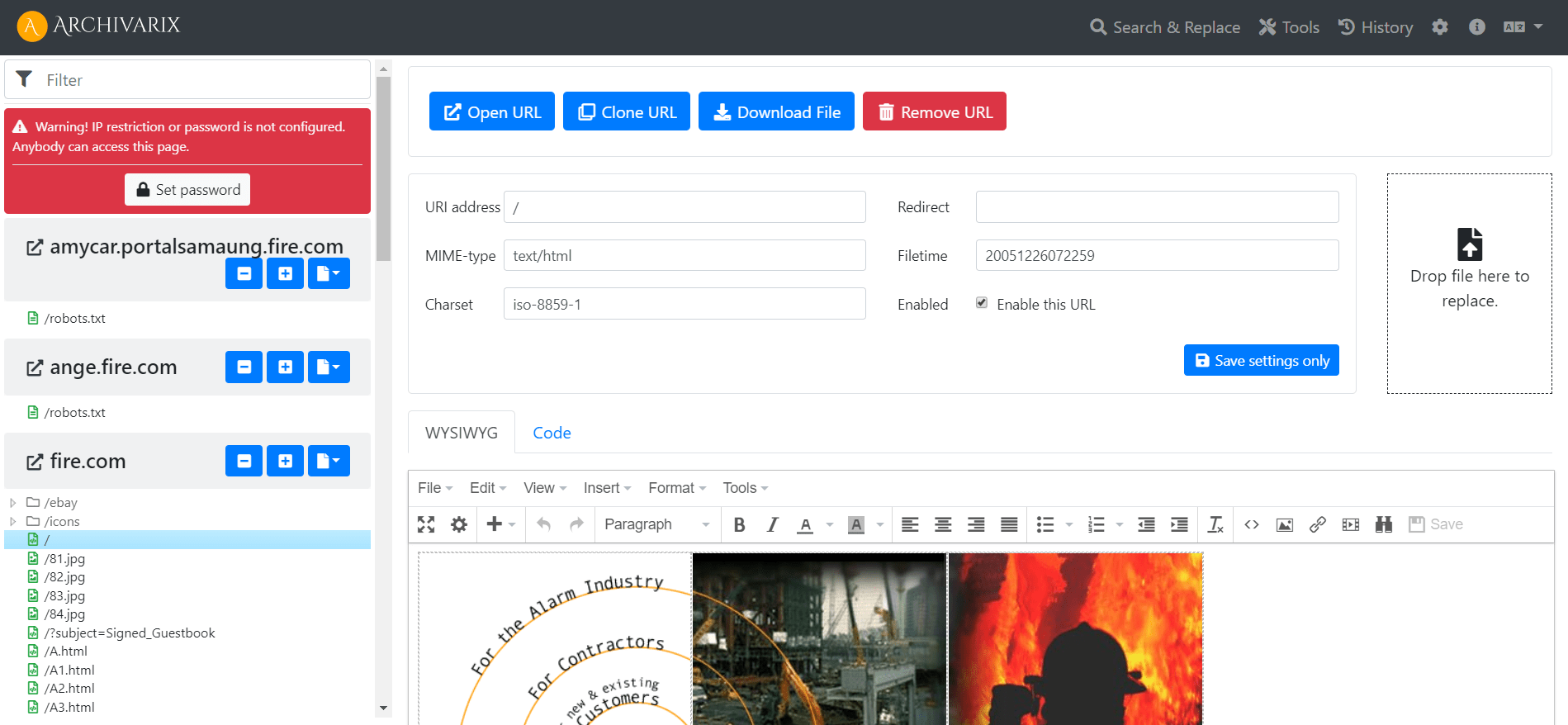
Prosty i kompaktowy CMS Archivarix. Płaski plik CMS dla pobranych stron internetowych.
Aby ułatwić edytowanie stron internetowych przywróconych w naszym systemie, opracowaliśmy prosty system plików Flat File CMS składający się tylko z jednego małego pliku php. Pomimo swoich rozmiarów, ten CMS jest potężnym i wszechstronnym narzędziem do pracy z twoimi witrynami. Dostępne są w nim wszystkie podstawowe funkcje dowolnego CMS, a także specjalne funkcje dla webmasterów tworzących PBN na podstawie treści przywróconych z archiwum internetowego.
Czytaj dalej…
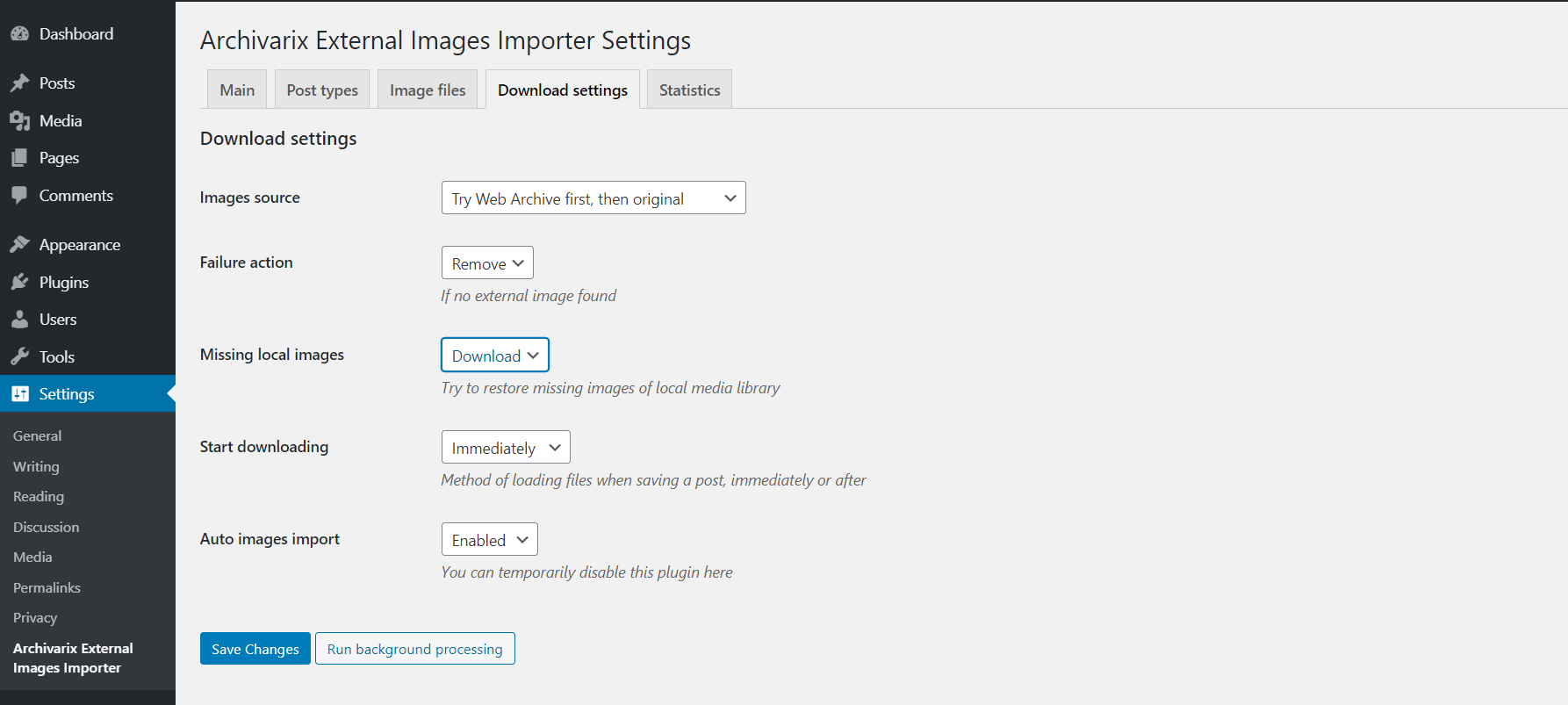
Jak przenieść zawartość z Wayback Machine (archive.org) do Wordpress?
Korzystając z opcji „Wyciąg z ustrukturyzowanej treści”, możesz łatwo utworzyć blog Wordpress zarówno ze strony znalezionej w archiwum internetowym, jak iz dowolnej innej witryny. Aby to zrobić, najpierw znajdź witrynę źródłową, a następnie w narzędziu "Wznowienie stronę" lub "Pobierz stronę" zaznacz opcję „Wyciąg z ustrukturyzowanej treści”. Wprowadź swoje opcje (e-mail, znaczniki czasu itp.) I rozpocznij pobieranie.
Czytaj dalej…
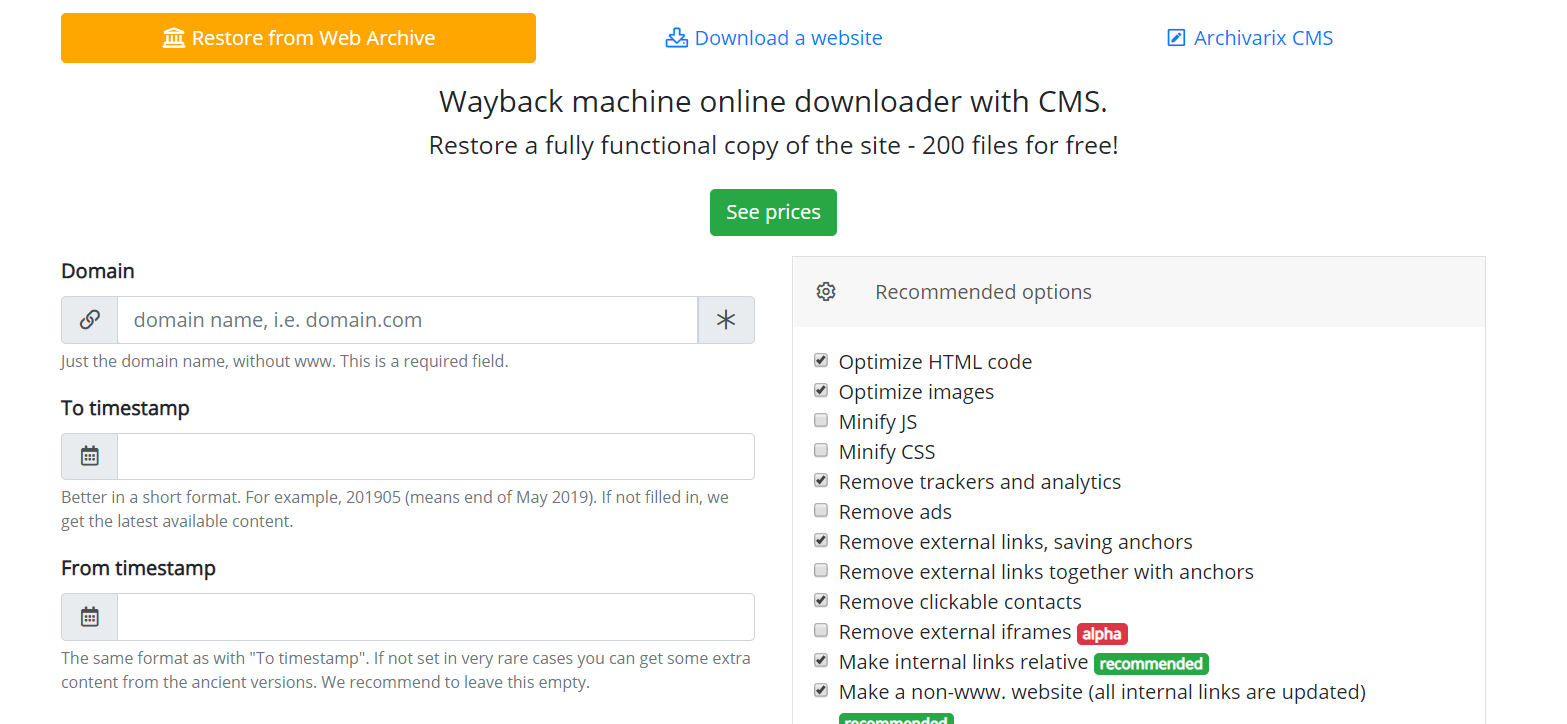
Jak działa Archivarix?
System Archivarix został zaprojektowany do pobierania i przywracania witryn, które nie są już dostępne z Archive.org oraz tych, które są obecnie online. Jest to główna różnica w stosunku do reszty „downloaderów” i „parserów witryn”. Celem Archivarix jest nie tylko pobranie, ale także przywrócenie strony internetowej w formie, która będzie dostępna na twoim serwerze.
Zacznijmy od modułu, który pobiera strony internetowe z archiwum internetowego. Są to serwery wirtualne zlokalizowane w Kalifornii. Ich lokalizację wybrano w taki sposób, aby uzyskać maksymalną możliwą prędkość połączenia z samym archiwum internetowym, ponieważ jego serwery znajdują się w San Francisco. Po wprowadzeniu danych w odpowiednim polu na stronie modułu https://pl.archivarix.com/restore/, wykonuje zrzut ekranu zarchiwizowanej witryny i zwraca się do interfejsu API Web Archive, aby poprosić o listę plików zawartych w określonym terminie odzyskiwania .
Czytaj dalej…
Zacznijmy od modułu, który pobiera strony internetowe z archiwum internetowego. Są to serwery wirtualne zlokalizowane w Kalifornii. Ich lokalizację wybrano w taki sposób, aby uzyskać maksymalną możliwą prędkość połączenia z samym archiwum internetowym, ponieważ jego serwery znajdują się w San Francisco. Po wprowadzeniu danych w odpowiednim polu na stronie modułu https://pl.archivarix.com/restore/, wykonuje zrzut ekranu zarchiwizowanej witryny i zwraca się do interfejsu API Web Archive, aby poprosić o listę plików zawartych w określonym terminie odzyskiwania .
