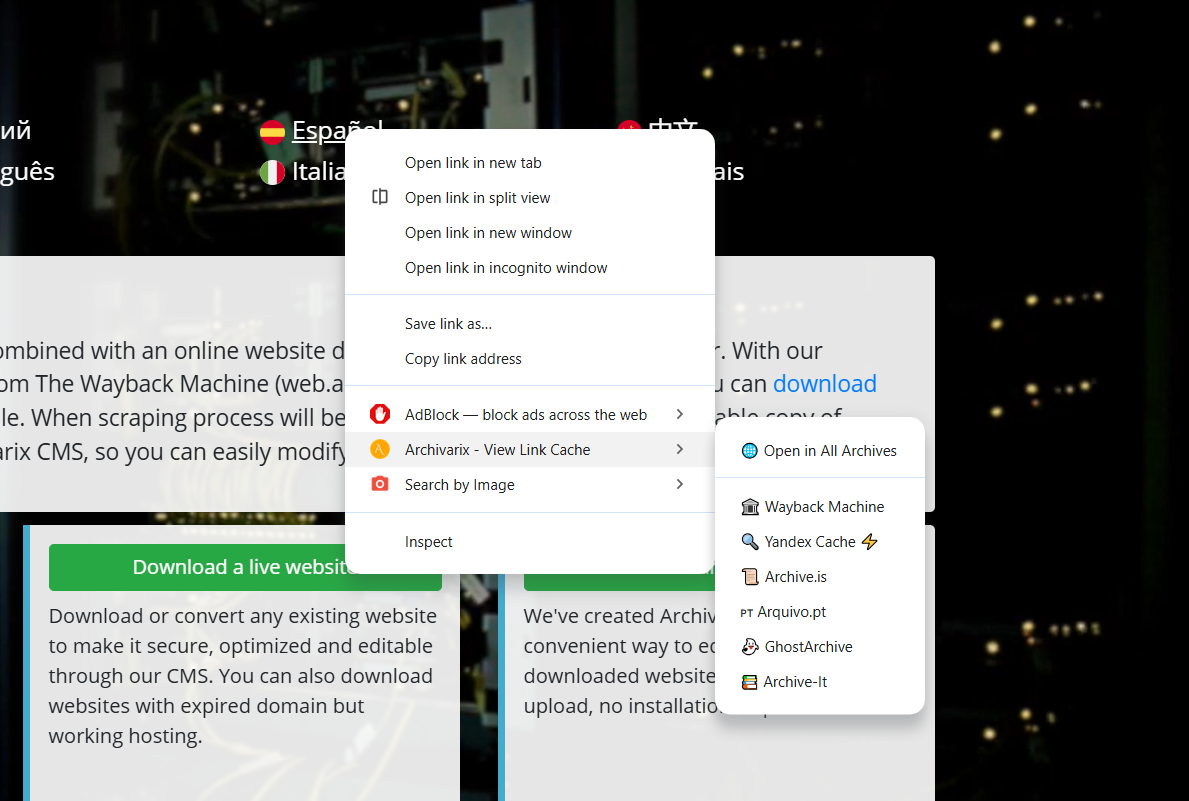
Extension Archivarix Cache Viewer pour Chrome et Firefox
Nous avons publié une extension de navigateur appelée Archivarix Cache Viewer. Elle est disponible pour Chrome et Firefox. L'extension est gratuite et ne contient aucune publicité.
Le principe est simple : un accès rapide aux versions en cache et archivées de n'importe quelle page web directement depuis le menu contextuel du navigateur. Plus besoin de copier manuellement les URL, d'ouvrir Wayback Machine et d'y coller l'adresse. Clic droit, choix de l'archive souhaitée, terminé.
Lire la suite…
Le principe est simple : un accès rapide aux versions en cache et archivées de n'importe quelle page web directement depuis le menu contextuel du navigateur. Plus besoin de copier manuellement les URL, d'ouvrir Wayback Machine et d'y coller l'adresse. Clic droit, choix de l'archive souhaitée, terminé.
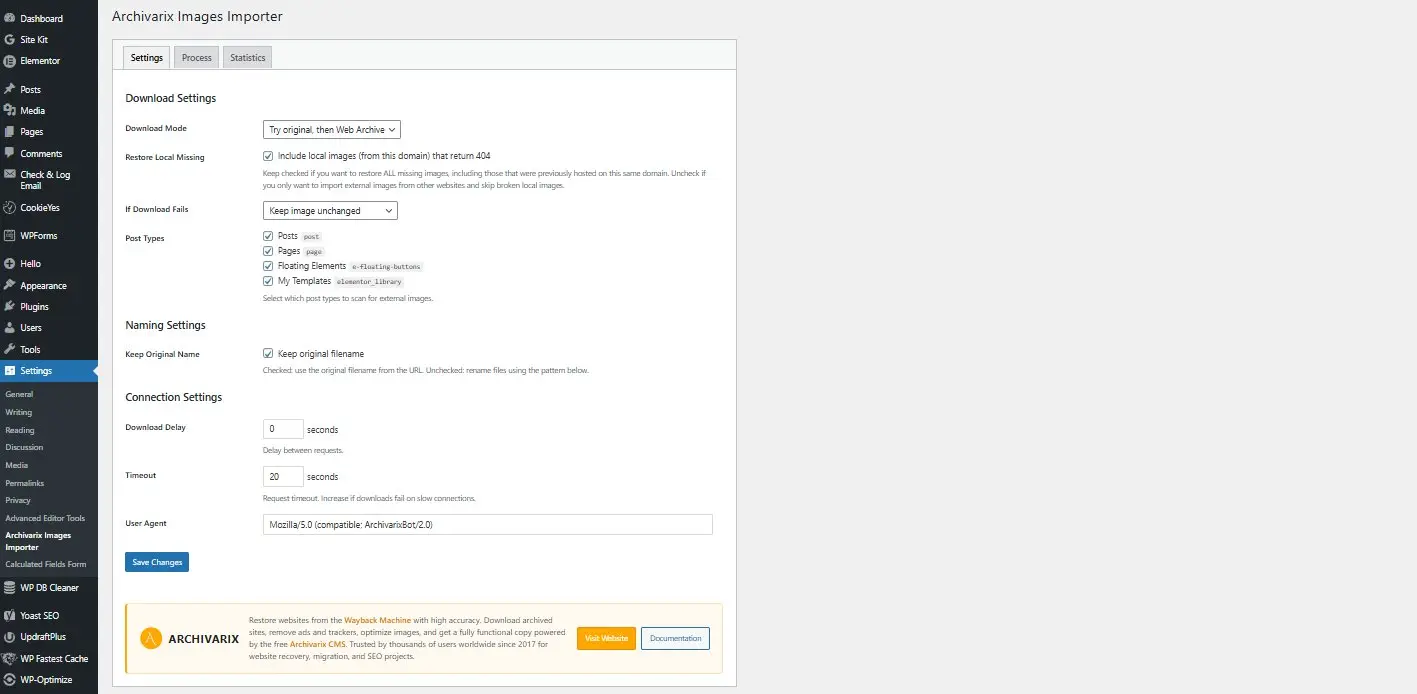
Archivarix External Images Importer 2.0 - Nouvelle version du plugin pour WordPress
Nous sommes heureux de présenter la version 2.0 de notre plugin WordPress pour l'importation d'images externes. Ce n'est pas qu'une simple mise à jour - le plugin a été entièrement réécrit en tenant compte des exigences modernes et des retours utilisateurs.
Lire la suite…

Expressions régulières utilisées dans Archivarix CMS
Cet article décrit les expressions régulières utilisées pour rechercher et remplacer du contenu dans des sites Web restaurés à l'aide du système Archivarix. Ils ne sont pas uniques à ce système. Si vous connaissez les expressions régulières de PHP, Perl, Java ou d'autres langages de programmation, alors vous savez déjà comment utiliser notre recherche et remplacer. Sinon, nous espérons que cet article vous aidera.
Lire la suite…
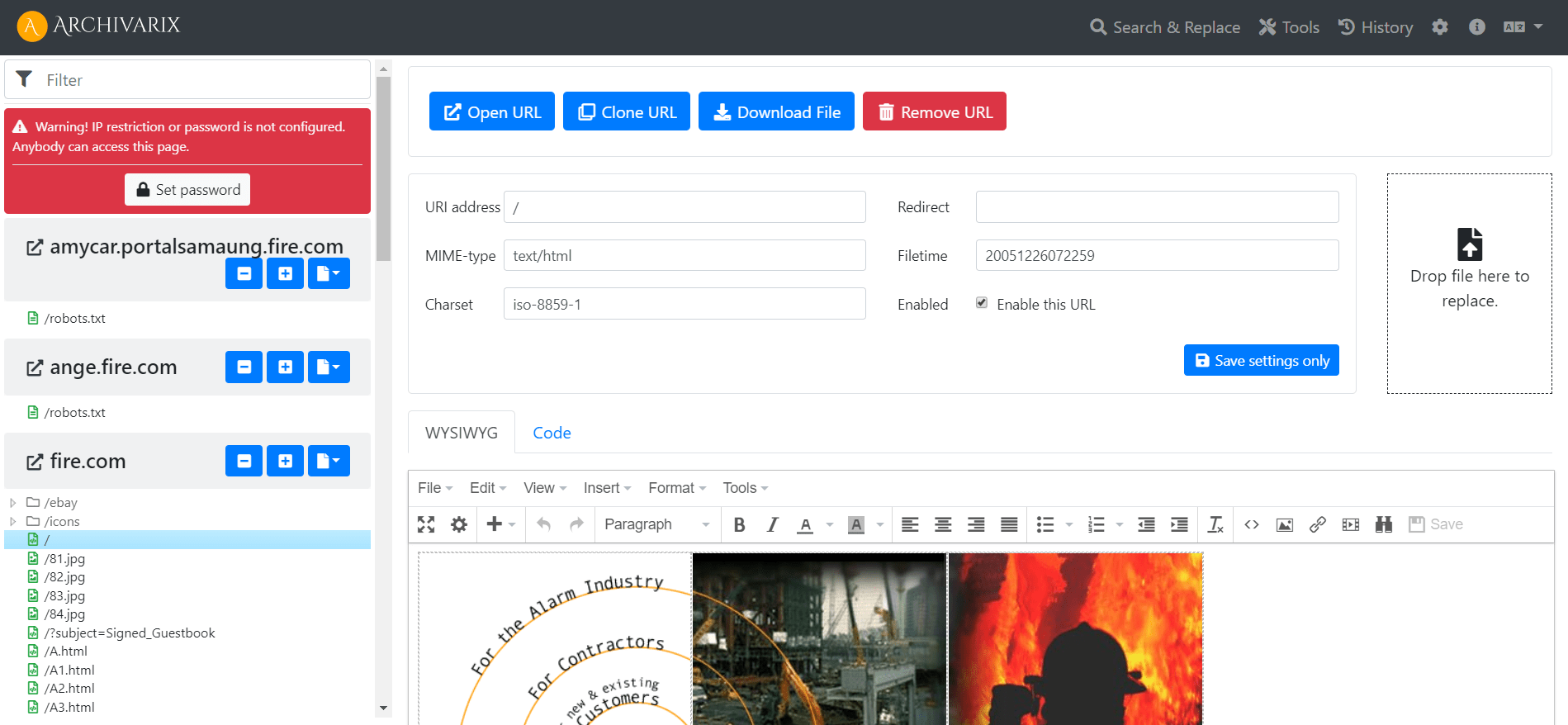
CMS Archivarix simple et compact. CMS à fichier plat pour les sites Web téléchargés.
Afin de vous permettre de modifier facilement les sites Web restaurés dans notre système, nous avons développé un CMS de fichier plat simple composé d'un seul petit fichier php. Malgré sa taille, ce CMS est un outil puissant et polyvalent pour travailler avec vos sites. Toutes les fonctionnalités de base de tout CMS y sont disponibles, ainsi que des fonctionnalités spéciales pour les webmasters créant des PBN basés sur le contenu restauré à partir des archives Web.
Lire la suite…
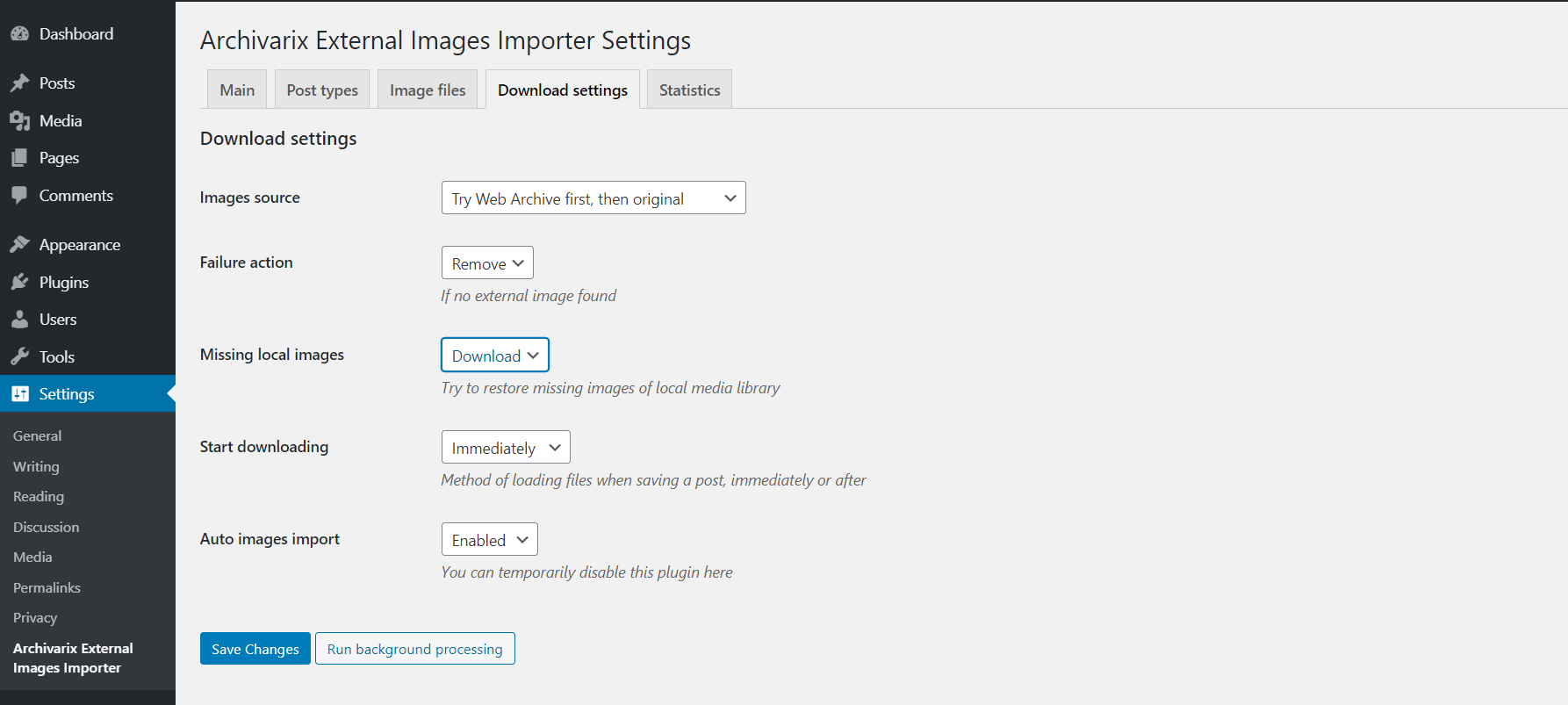
Comment transférer du contenu de la Wayback Machine (archive.org) vers Wordpress?
En utilisant l'option «Extraire du contenu structuré», vous pouvez facilement créer un blog Wordpress à partir du site présent sur les archives Web et de tout autre site. Pour ce faire, commencez par rechercher le site source, puis cochez la case "Extraire du contenu structuré" dans l'outil "Restaurer le site" ou "Télécharger le site". Entrez vos options (email, timestamps, etc.) et commencez le téléchargement.
Lire la suite…
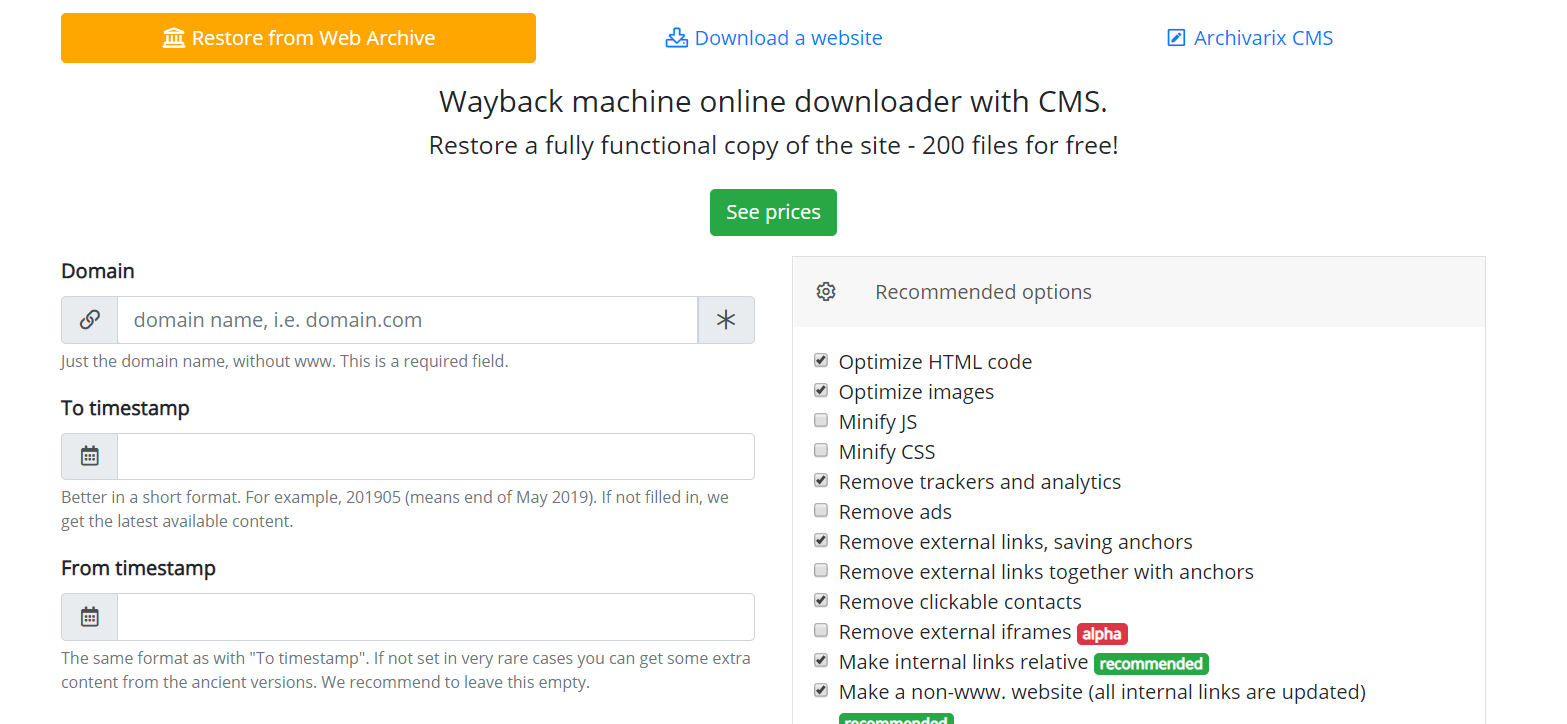
Comment Archivarix agit-il?
Le système Archivarix est conçu pour télécharger et restaurer les sites qui ne sont plus accessibles à partir de Web Archive et ceux qui sont actuellement en ligne. C'est la principale différence avec le reste des «téléchargeurs» et des «analyseurs de site». L'objectif d'Archivarix n'est pas seulement de télécharger, mais également de restaurer le site Web sous une forme qui le rendra accessible sur votre serveur.
Commençons par le module qui télécharge des sites Web à partir de Web Archive. Ce sont des serveurs virtuels situés en Californie. Leur emplacement a été choisi de manière à obtenir la vitesse de connexion maximale possible avec Web Archive elle-même, car ses serveurs sont situés à San Francisco. Une fois les données saisies dans le champ approprié de la page du module https://fr.archivarix.com/restore/, une capture d'écran du site Web archivé et l'adresse de l'API Web Archive pour demander une liste des fichiers contenus à la date de récupération spécifiée.
Lire la suite…
Commençons par le module qui télécharge des sites Web à partir de Web Archive. Ce sont des serveurs virtuels situés en Californie. Leur emplacement a été choisi de manière à obtenir la vitesse de connexion maximale possible avec Web Archive elle-même, car ses serveurs sont situés à San Francisco. Une fois les données saisies dans le champ approprié de la page du module https://fr.archivarix.com/restore/, une capture d'écran du site Web archivé et l'adresse de l'API Web Archive pour demander une liste des fichiers contenus à la date de récupération spécifiée.
