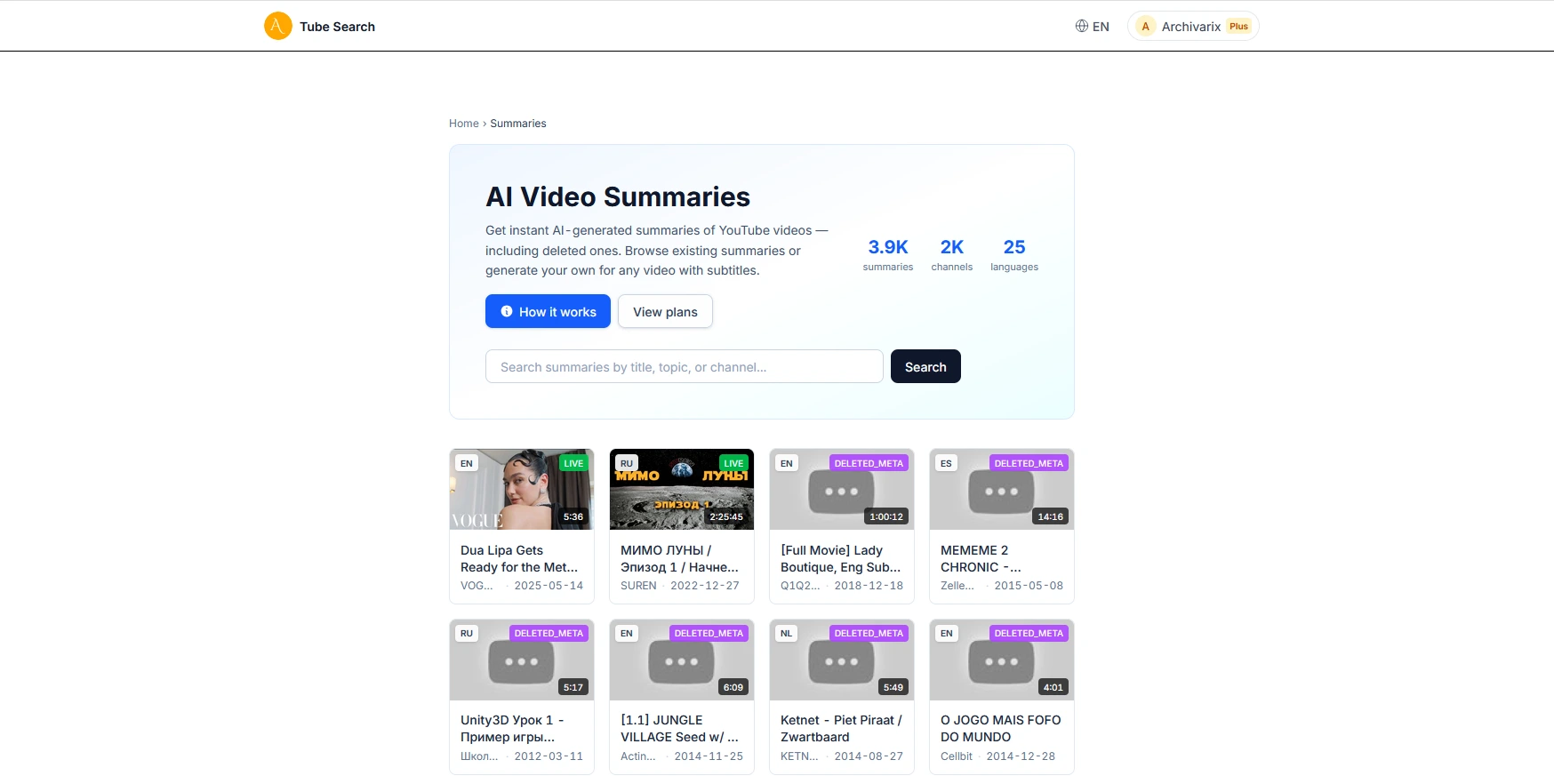
AI Video Summaries in Archivarix Tube Search
When you find a deleted YouTube video through Tube Search, you typically get metadata: a title, description, upload date, and sometimes subtitles. That is already useful. But reading through raw subtitles to understand what a video was about takes time, especially for longer recordings.
We have added AI-powered video summaries to Tube Search. If a video has archived subtitles, the system can now generate a structured summary of its content in seconds.
Read more…
We have added AI-powered video summaries to Tube Search. If a video has archived subtitles, the system can now generate a structured summary of its content in seconds.

Archivarix Tube Search - A Search Engine for Deleted YouTube Videos
Tube Search is a search engine for archived YouTube data. The service aggregates information from multiple public sources: the Wayback Machine (Internet Archive), Common Crawl, and various collected YouTube metadata datasets. When a video is deleted from YouTube, its page ceases to exist. But if a web archive managed to index that page before deletion, the video metadata is preserved: title, description, upload date, view count, thumbnails, subtitles.
Read more…

Archivarix Broken Links Recovery: Free WordPress Plugin for Finding and Fixing Broken Links
Over time, external links in WordPress posts inevitably break, pages get deleted, domains expire, videos become unavailable. Checking hundreds or thousands of links manually is impractical. Archivarix Broken Links Recovery automates this process: the plugin scans your content, finds broken links, and replaces them with working copies from the Wayback Machine.
Read more…
How the Internet Archive Decides What to Archive: Priorities, Frequency, and Data Sources
One trillion saved pages. Over 99 petabytes of data. Hundreds of crawls running simultaneously every day. Behind these numbers lies a question that everyone who professionally works with web archives asks themselves: how exactly does the Wayback Machine decide which sites to scan, how often to return to them, and why are some domains represented in the archive with thousands of snapshots while others have only a few records over ten years?
Understanding these mechanisms is critically important for anyone involved in website restoration. If you know how the system works from the inside, you can predict what you'll find in the archive and what won't be there. And you can influence the archiving of your own sites while they're still live.
Read more…
Understanding these mechanisms is critically important for anyone involved in website restoration. If you know how the system works from the inside, you can predict what you'll find in the archive and what won't be there. And you can influence the archiving of your own sites while they're still live.
How to Find and Buy an Expired Domain with a Good History
Buying an expired domain with history is one of the most effective ways to launch a new project with an already existing backlink profile, trust, and even traffic. Instead of promoting a bare domain from scratch, you get a platform that search engines already know and to some extent trust.
Read more…
Common Crawl as an Alternative Data Source for Website Restoration
When it comes to restoring websites from archives, almost everyone thinks only of the Wayback Machine. That's understandable: archive.org is well known, it has a convenient interface, a trillion saved pages. But the Wayback Machine is not the only major web archive in the world. There is a project that is comparable in the volume of collected data to the Internet Archive, and in some respects even surpasses it. This project is called Common Crawl, and surprisingly few people know about it, even among those who work professionally with web archives.
Read more…
Archivarix Cache Viewer Extension for Chrome, Edge and Firefox
We've released a browser extension called Archivarix Cache Viewer. It's available for Chrome, Edge and Firefox. The extension is free and contains no ads whatsoever.
The idea is simple: quick access to cached and archived versions of any web page right from the browser's context menu. No more manually copying URLs, opening Wayback Machine and pasting the address there. Right-click, pick the archive you need, done.
Read more…
The idea is simple: quick access to cached and archived versions of any web page right from the browser's context menu. No more manually copying URLs, opening Wayback Machine and pasting the address there. Right-click, pick the archive you need, done.

AI Content on Restored Websites: How to Detect It and What to Do About It
When you restore a website from the Web Archive, you expect to get original content that was once written by real people. But if the site's archives were made after 2023, there's a real chance of encountering texts generated by language models. Website owners were mass-replacing original content with texts from ChatGPT and similar tools, often without even trying to edit them.
Read more…

Web Archive in 2026: What Has Changed and How It Affects Website Restoration
In October 2025, the Wayback Machine reached the milestone of one trillion archived web pages. Over 100,000 terabytes of data. This is a massive achievement for a nonprofit organization that has been operating since 1996. But behind this impressive number lies a difficult period that Internet Archive has gone through over the past year and a half. Cyberattacks, lawsuits, changes in access policies, and new challenges from AI companies - all of this directly affects those who use the web archive for website restoration.
Read more…
Archivarix External Images Importer 2.0 - New Plugin Version for WordPress
We are pleased to introduce version 2.0 of our WordPress plugin for importing external images. This is not just an update, the plugin has been completely rewritten from scratch based on modern requirements and user feedback.
Read more…

Black Friday & Cyber Monday Coupons
Dear friends!
Black Friday and Cyber Monday are the best time to save on future website restores.
If you plan to restore websites, top up your balance in advance, or simply want to get more – now is the most profitable moment.
From November 28 to December 15, 2025 you can use special coupon codes that give bonuses for any balance top-up. The bonus is credited instantly after applying the coupon.
Read more…
Black Friday and Cyber Monday are the best time to save on future website restores.
If you plan to restore websites, top up your balance in advance, or simply want to get more – now is the most profitable moment.
From November 28 to December 15, 2025 you can use special coupon codes that give bonuses for any balance top-up. The bonus is credited instantly after applying the coupon.

Archivarix is 8 years old!
Dear friends!
Today we celebrate Archivarix's 8th anniversary, and it's the perfect occasion to say a huge thank you!
We are truly grateful that you chose our service for website recovery from web archives. Many of you use Archivarix on a regular basis, and this inspires us to keep improving.
Read more…
Today we celebrate Archivarix's 8th anniversary, and it's the perfect occasion to say a huge thank you!
We are truly grateful that you chose our service for website recovery from web archives. Many of you use Archivarix on a regular basis, and this inspires us to keep improving.

7 Years of Archivarix
Today is a special day — Archivarix is celebrating its 7th anniversary! We want to thank you for your trust, ideas, and feedback, which have helped us become the best service for restoring websites from the Wayback Machine.
Read more…

To everyone who has been waiting for top-up discounts!
Dear Archivarix users, Congratulations on the upcoming holidays and thank you for choosing our service to archive and restore your websites!
Read more…

6 Years of Archivarix
It's that special time when we take a moment to reflect not just on our achievements, but also on the incredible journey we've shared with you. This year, Archivarix celebrates its 6th anniversary, and foremost, we want to extend our heartfelt gratitude to you, our dedicated users.
Read more…

Price Changes
On Feb 1st 2023 our prices will change. Activate the promo-code and get a huge bonus in advance.
Read more…


4 years of Archivarix!
It has been four years since we made the Archivarix service public on September 29, 2017. Users make thousands of restorations every day. The number of servers that distribute downloads and processing among themselves consistently exceeds 40, and the system automatically adds new machines under load.
Read more…
What can be recovered from the Web Archive?
Sometimes our users ask why the website was not fully restored? Why the website doesn't it work the way I would like it to? Known issues when restoring sites from archive.org.
Read more…

BLACKFRIDAY
Two big tasty coupons are valid from Friday 27.11.2020 to Monday 30.11.2020. Each of them gives a balance bonus in the form of 20% or 50% of the amount of your last or new payment.
Read more…
Happy 3rd birthday to Archivarix
Three years ago, on September 29, 2017, our archive.org downloader service was launched. All these 3 years we have been continuously developing, we have created our own CMS, a Wordpress plugin, a system for downloading live sites, significantly improved and accelerated the recovery algorithm and much more.
Read more…

Archivarix.net - Web archive and search engine.
Wayback Machine ( web.archive.org ) Alternative. Internet archive search engine. Find archived copies of websites. Data from 1996. Full-text search.
In the near future, our team plans to launch a unique service that combines the capabilities of the Internet Archive (archive.org) and a search engine.
Read more…
In the near future, our team plans to launch a unique service that combines the capabilities of the Internet Archive (archive.org) and a search engine.
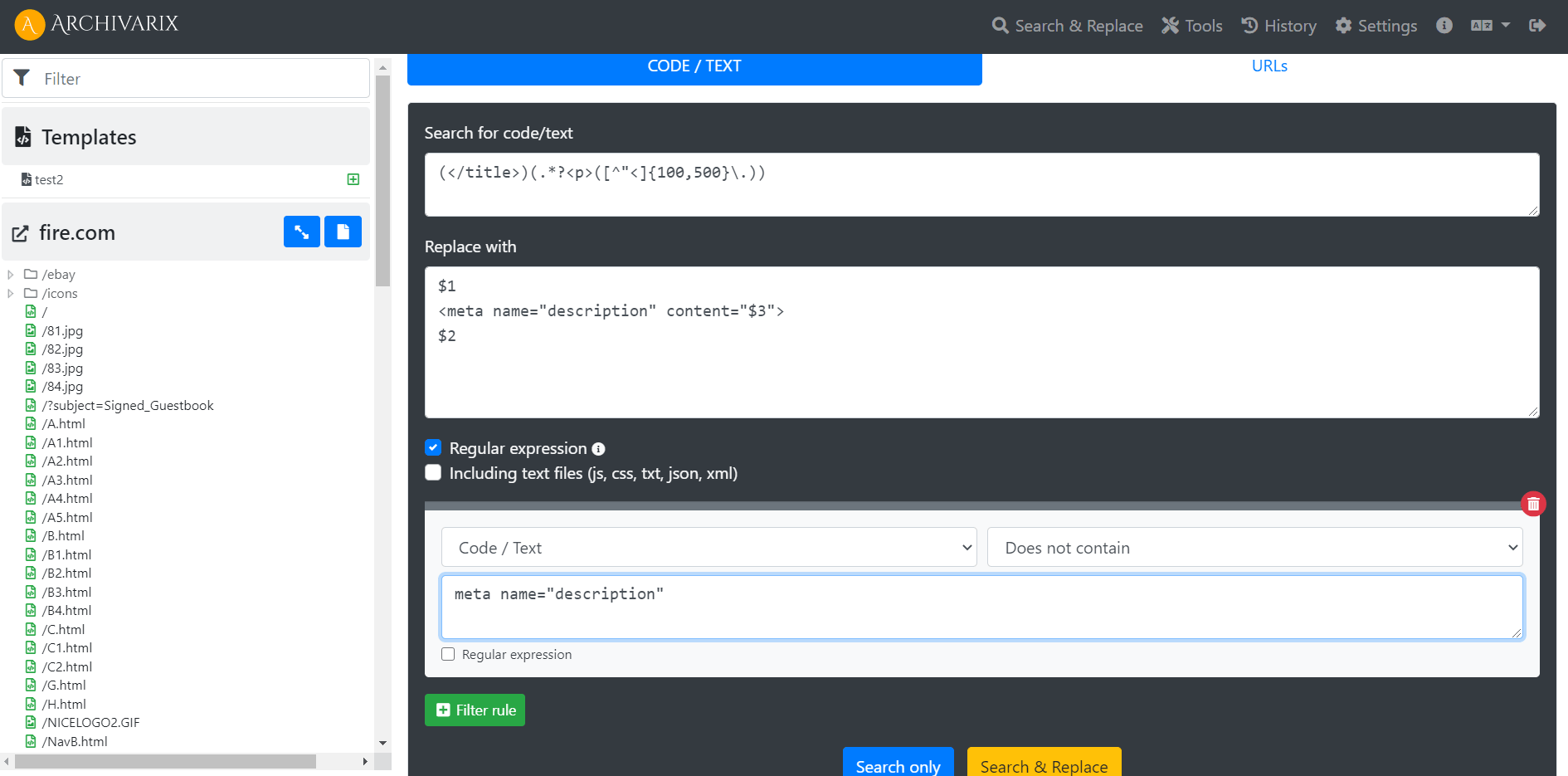
Examples of using regular expressions in Archivarix CMS
How to generate meta name="description" on all pages of a website? How to make the site work not from the root, but from a subdirectory?
Read more…

How to show hidden files on macOS.
How to show hidden files on macOS. How to view and edit files starting with dot ( like .htaccess ) in macOS?
Read more…
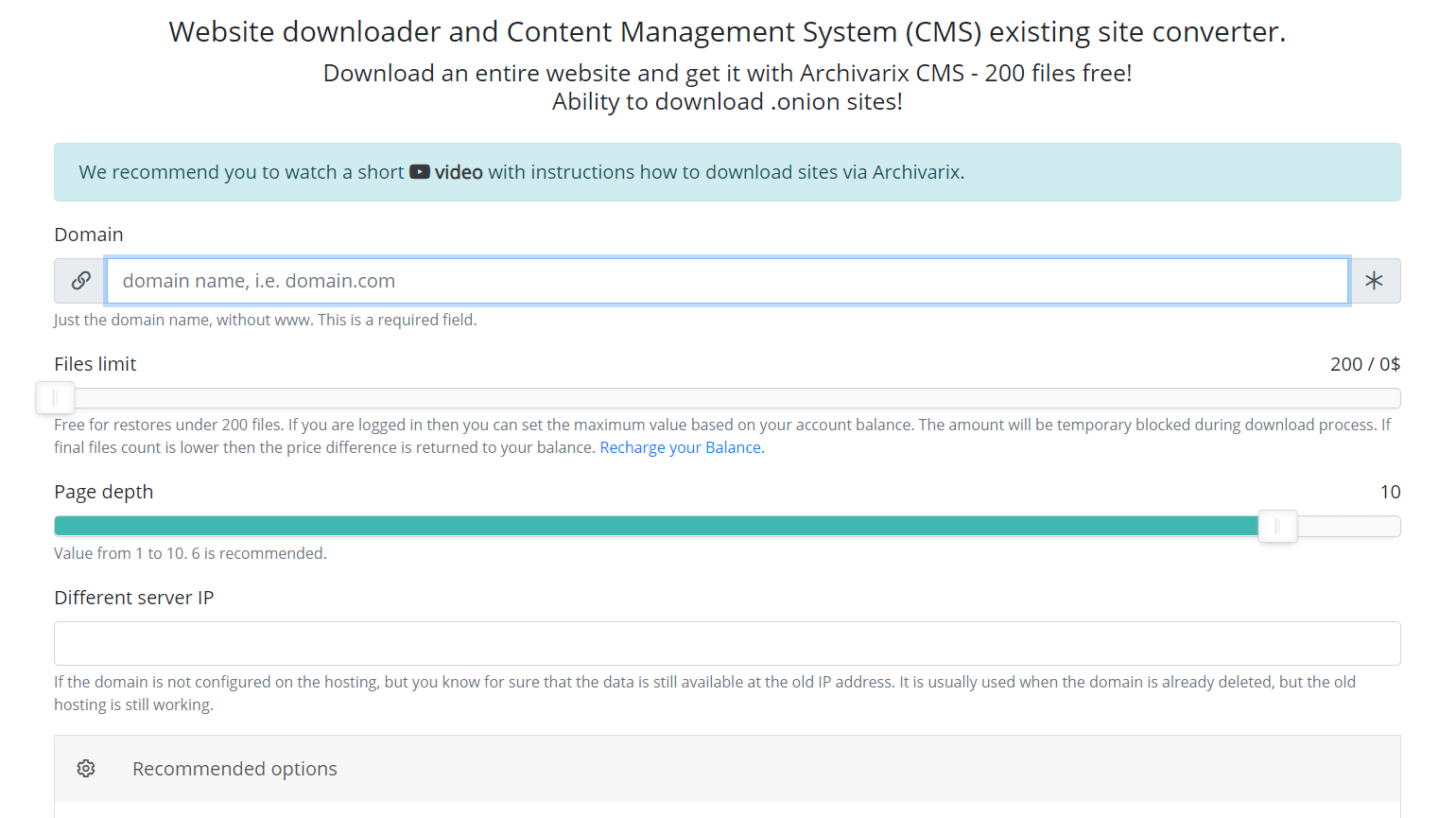
Website downloader. How to choose the files limit?
Our Website downloader system allows you to download up to 200 files from a website for free. If there are more files on the site and you need all of them, then you can pay for this service. Download cost depends on the number of files. How to find out how many files are really on the website and how much it will cost to download them?
Read more…

Regular expressions used in Archivarix CMS
This article describes regular expressions used to search and replace content in websites restored using the Archivarix System. They are not unique to this system. If you know the regular expressions of PHP, Perl, Java or other programming languages, then you already know how to use our search and replace. If not, we hope this article helps you.
Read more…
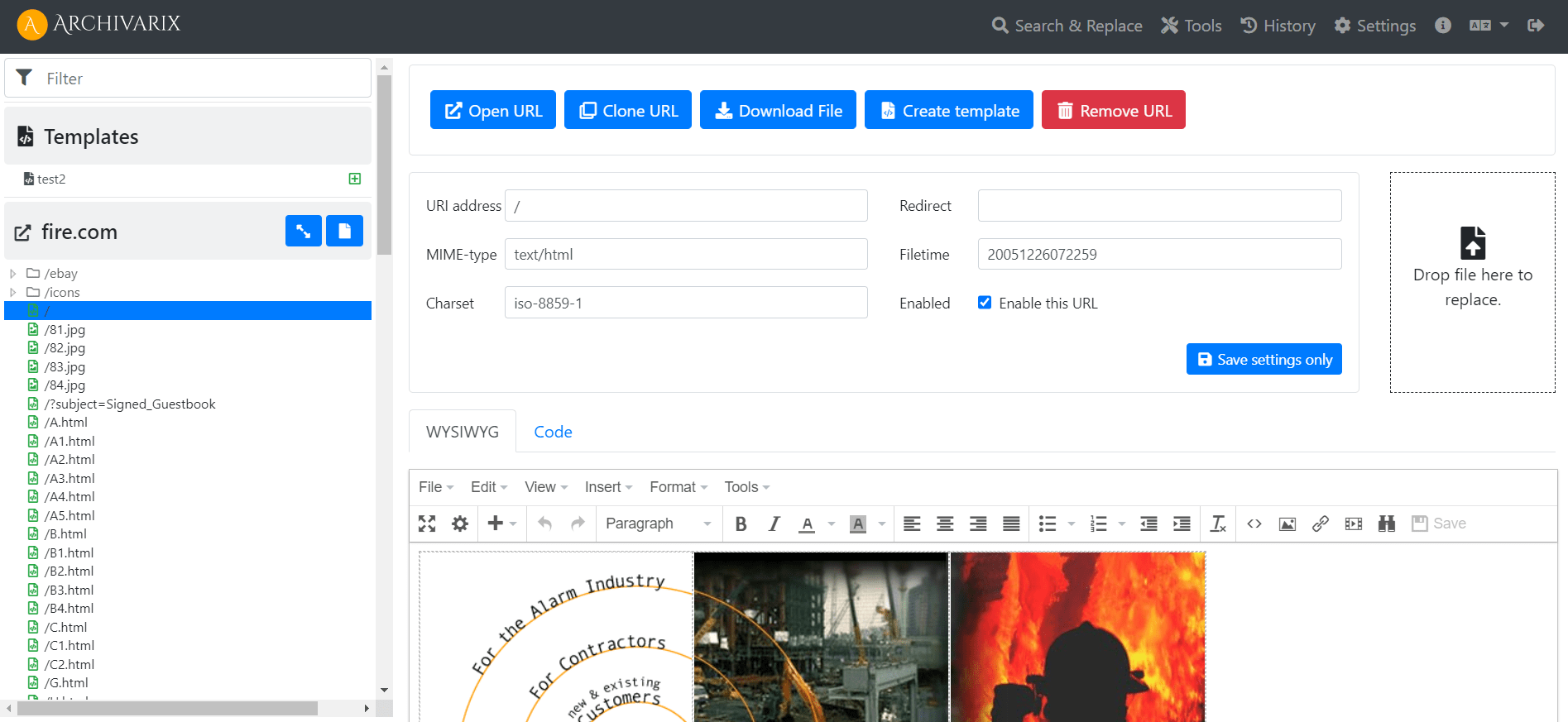
Simple and compact Archivarix CMS. Flat-file CMS for downloaded websites.
In order to make it convenient for you to edit the websites restored in our system, we have developed a simple Flat File CMS consisting of just one small php file. Despite its size, this CMS is a powerful and versatile tool for working with your sites. All the basic features of any CMS are available in it, as well as special features for webmasters creating PBNs based on content restored from the Web Archive.
Read more…
Best Wayback Machine alternatives. How to find deleted websites.
The Wayback Machine is the famous and biggest archive of websites in the world. It has more than 400 billion pages on their servers. Is there any archiving services like Archive.org?
Read more…
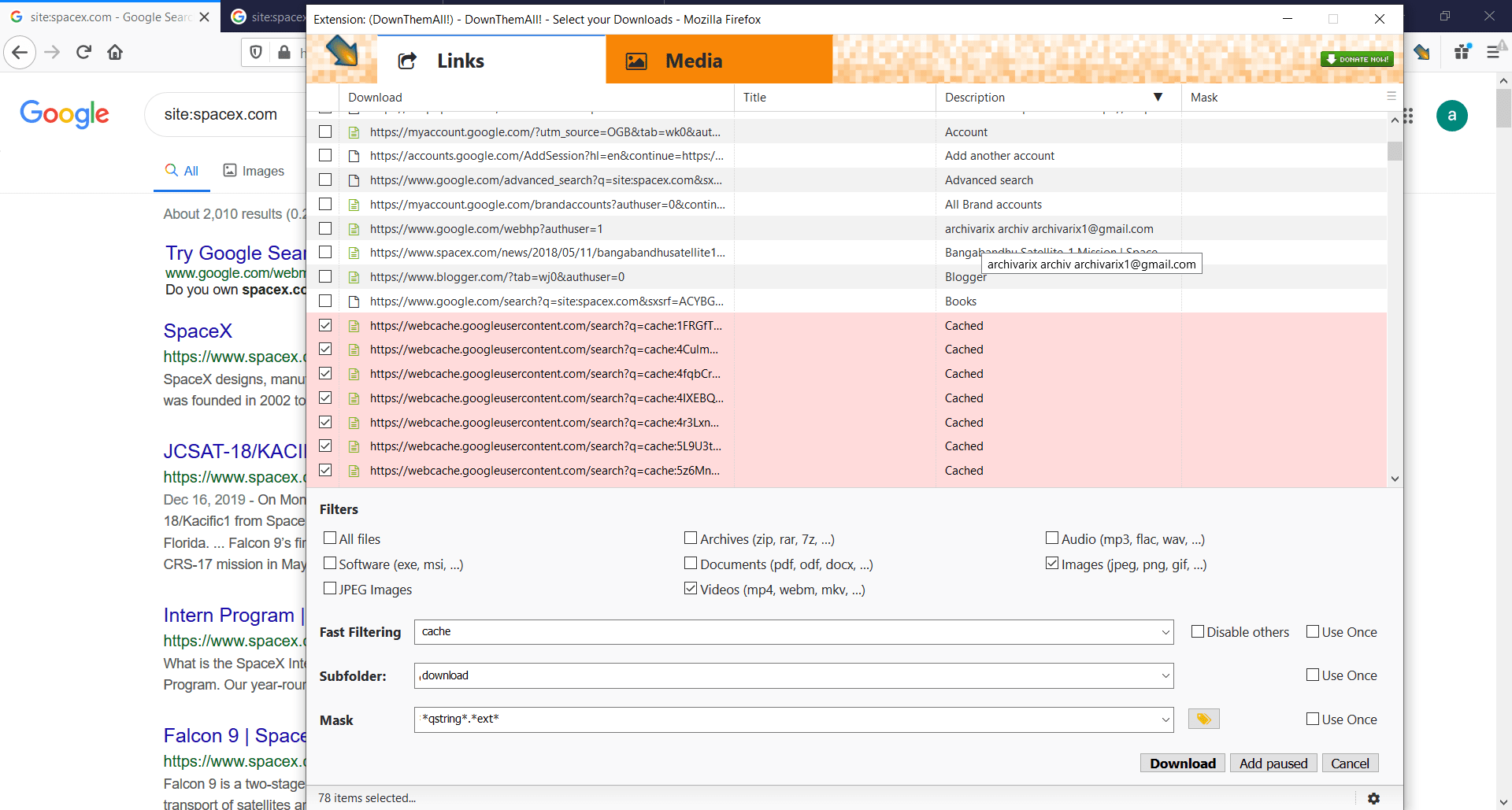
How to download an entire website from Google Cache?
If the website was recently deleted, but the Wayback Machine didn't save the latest version, what you can do to get the content? Google Cache will help you to do this. All you need is to install this plugin -
Read more…
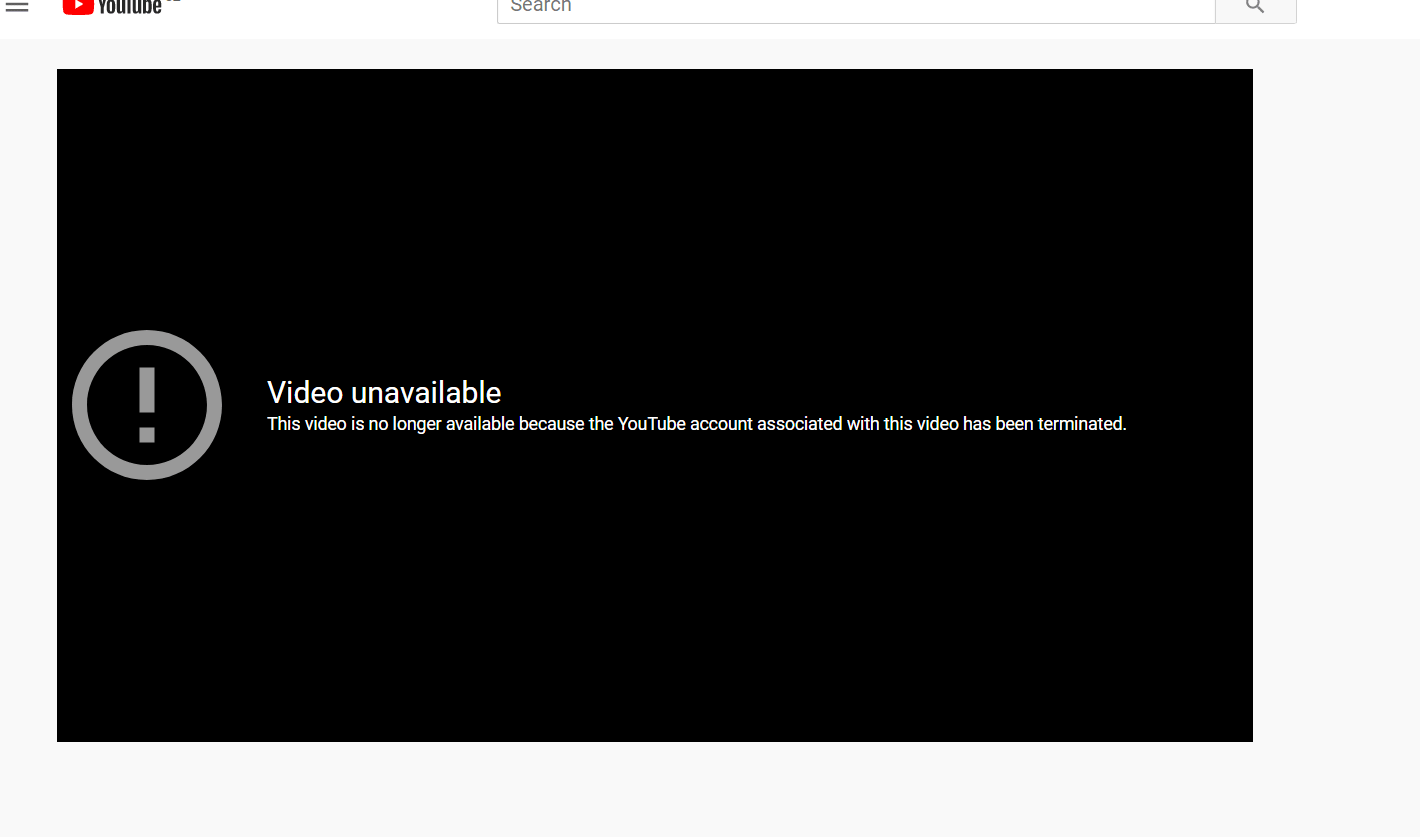
How to recover deleted YouTube videos?
Sometimes you can see this "Video unavailable" message from Youtube. Usually it means that Youtube has deleted this video from their server. But there is an easy way how to get it from the Wayback Machine. Firstly, you need a Youtube video link. It looks like this: https://www.youtube.com/watch?v=1vpS_-nN3JM The last symbols after watch?v= is a code of the video.
Read more…
How to hide your backlinks from competitors?
If you are making a PBN (Private Blog Network) , then you probably didn’t really want other webmasters to know where you get your backlinks. A large number of services are involved in backlink and keyword analysis, the most famous of which are Majestic, Ahrefs, Semrush. All of them have their own bots that can be blocked. One way is to write Disallow rules for these bots in the robots.txt file, but then this file will be visible to everyone, and this may turn out to be one of the footprints by which you can identify the website as a part of your PBN competitor backlink analysis.
Read more…
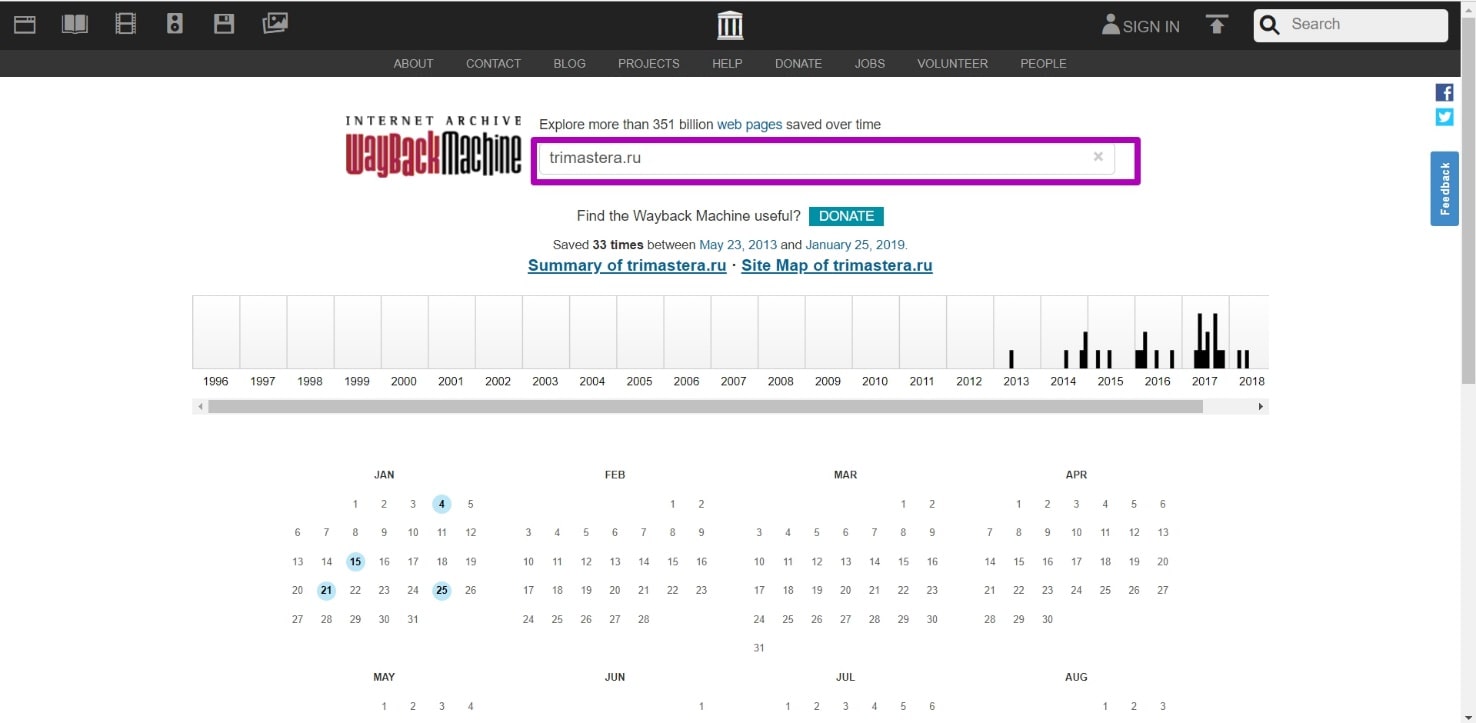
How to restore websites from the Web Archive - archive.org. Part 3
Choosing “BEFORE” limit when restoring websites from archive.org. When domain expires, domain provider or hoster’s parking page may appear. When entering such a page, the Internet Archive will save it as fully operational one, displaying the relevant information on the calendar. If you restore a website from the calendar by such a date, then instead of a normal page will see that mentioned parking page. How can I avoid such a problem and find out the working date of all website pages in order to restore it?
Read more…
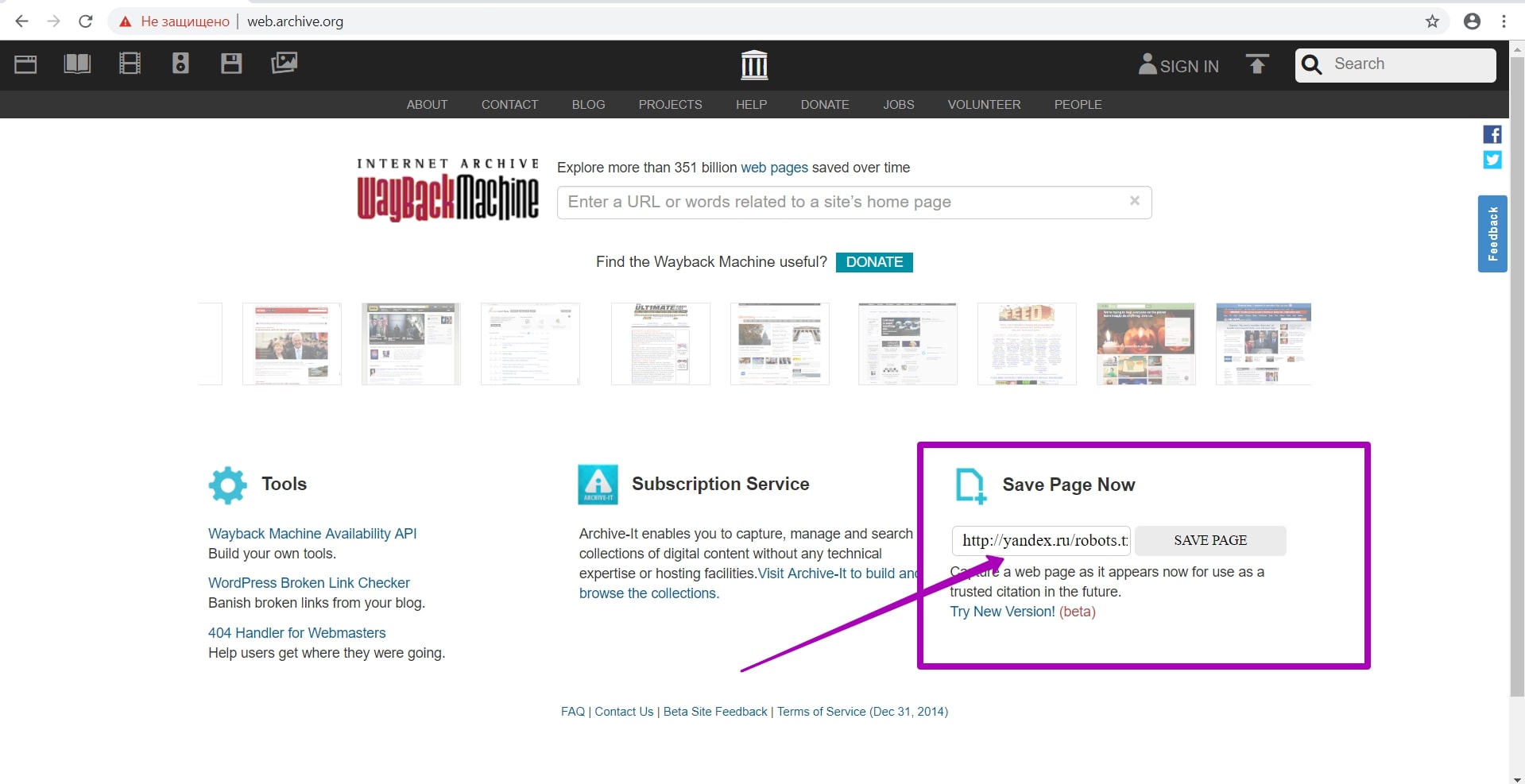
How to restore websites from the Web Archive - archive.org. Part 2
In the previous article we examined archive.org operation, and in this article we will talk about a very important stage of site restoring from the Wayback Machine that relates to domain preparation for restoring. This step gives confidence that you will restore the maximum content on your website.
Read more…
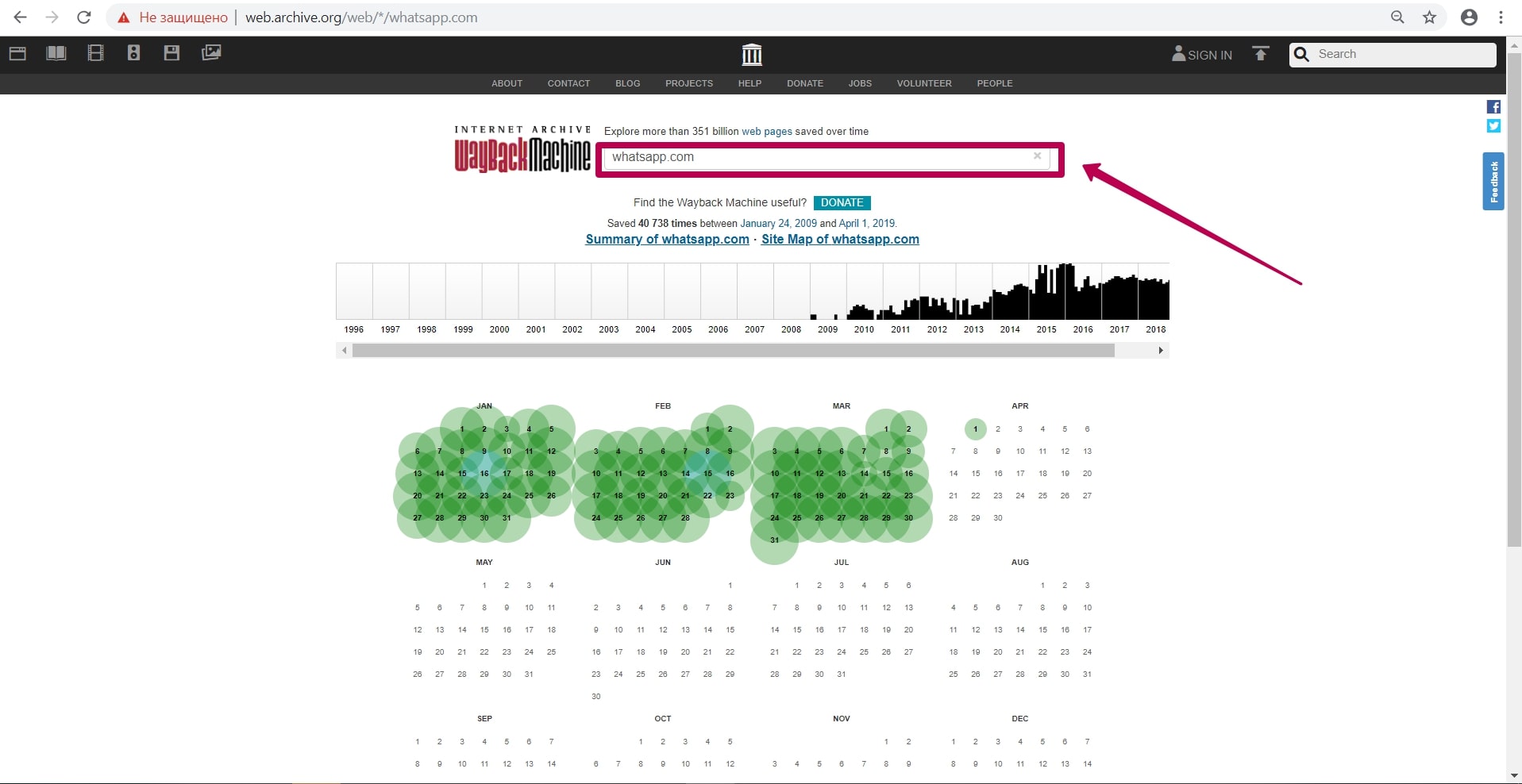
How to restore websites from the Web Archive - archive.org. Part 1
Web Archive Interface: Instructions for the Summary, Explore, and Site map tools. For reference: Archive.org (Wayback Machine - Internet Archive) was created by Brewster Cale in 1996 about at the same time when he founded Alexa Internet, a company that collects statistics on website traffic. In October of that year, company started archiving and storing copies of web pages.
Read more…
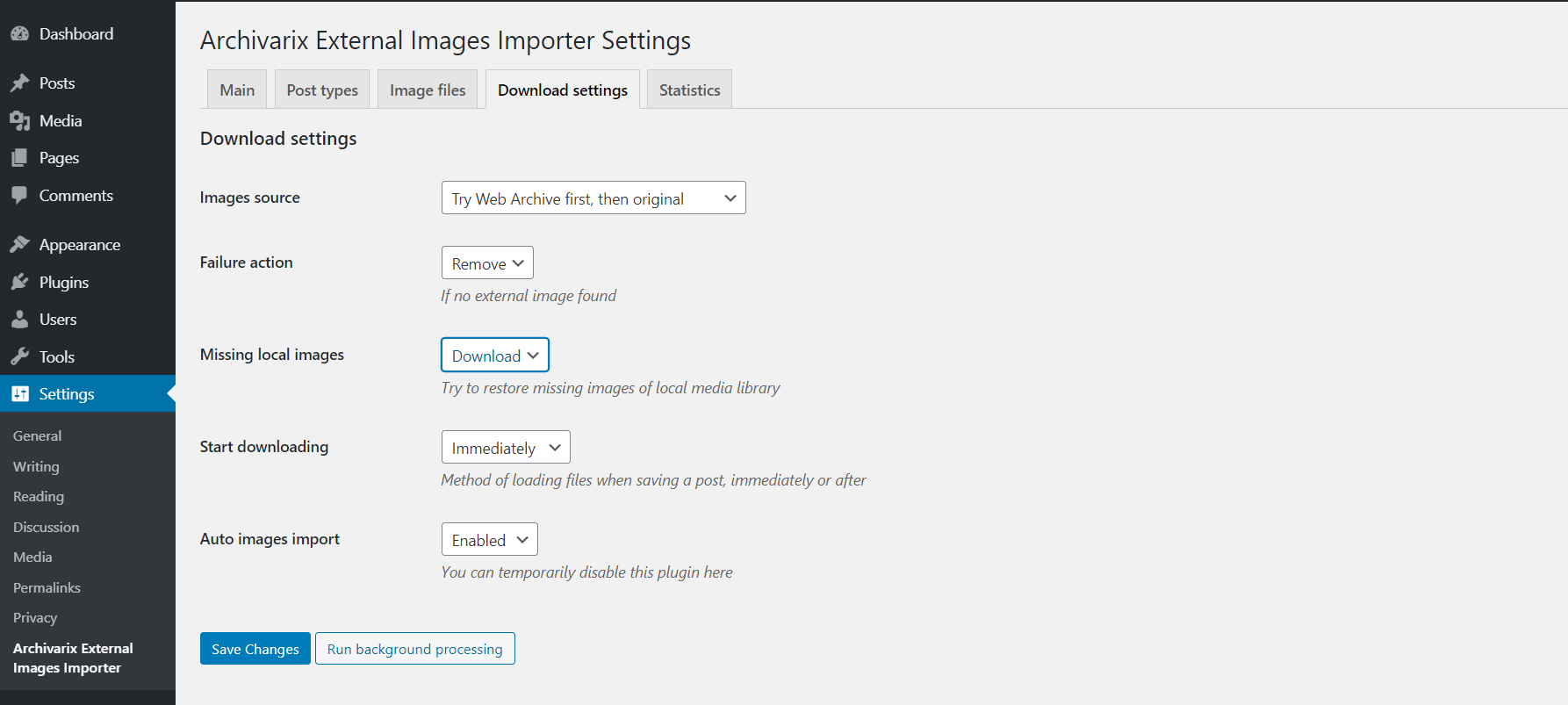
How to transfer content from the Wayback Machine (archive.org) to Wordpress?
By using the “Extract structured content” option you can easily make a Wordpress blog both from the site found on the Web Archive and from any other website. To do this, firstly find the source website and then in one of our download tools "Restore A Website" or "Download A Website" check in "Advanced Options" - "Extract structured content". After that enter all your data ( email, timestamps, etc. ) and start downloading.
Read more…
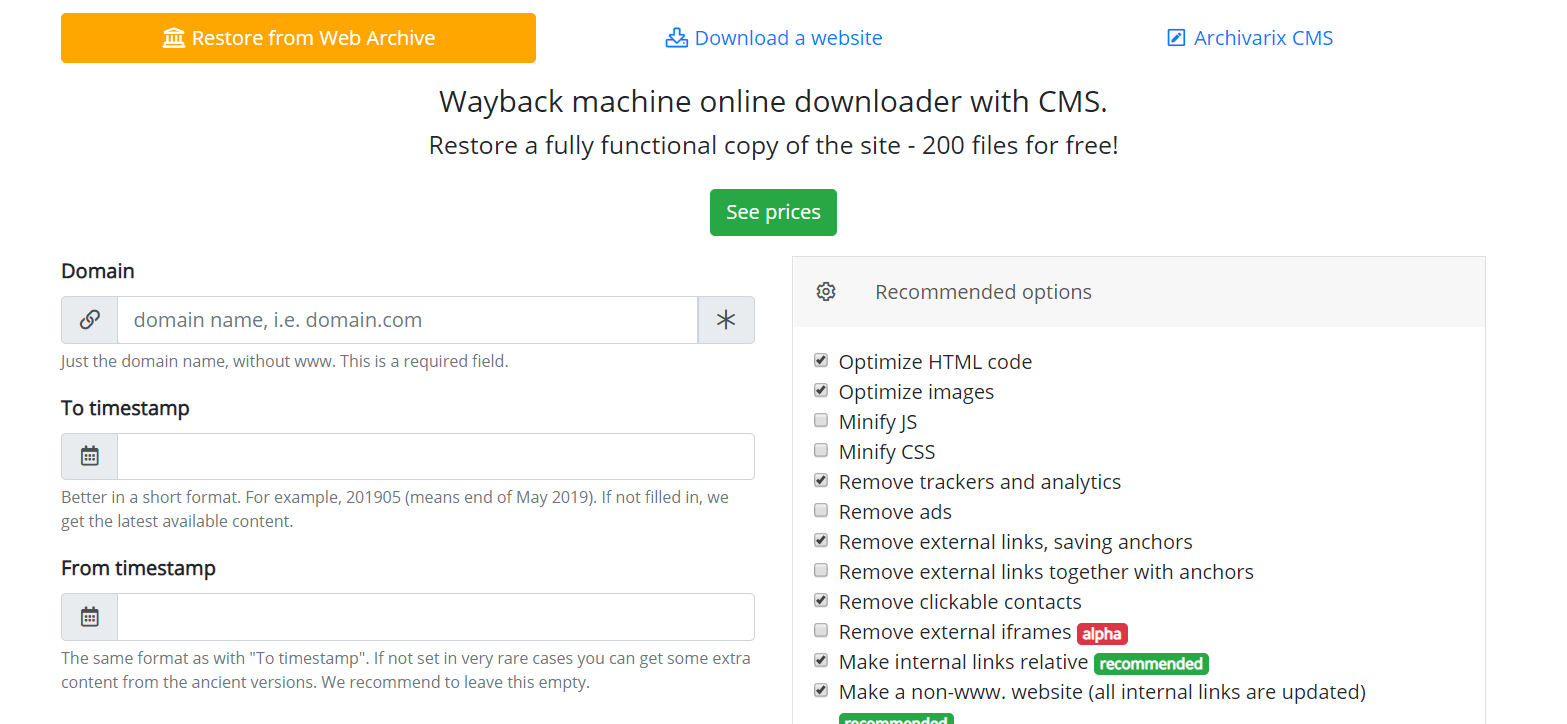
How does Archivarix work?
The Archivarix system is designed to download and restore sites that are no longer accessible from Web Archive, and those that are currently online. This is the main difference from the rest of “downloaders” and “site parsers”. Archivarix goal is not only to download, but also to restore the website in a form that it will be accessible on your server.
Let's start with the module that downloads websites from Web Archive. These are virtual servers located in California. Their location was chosen in such a way as to obtain the maximum possible connection speed with the Web Archive itself, because its servers are located in San Francisco. After entering data in the appropriate field on the module’s page https://en.archivarix.com/restore/, it takes a screenshot of the archived website and addresses the Web Archive API to request a list of files contained on the specified recovery date
Read more…
Let's start with the module that downloads websites from Web Archive. These are virtual servers located in California. Their location was chosen in such a way as to obtain the maximum possible connection speed with the Web Archive itself, because its servers are located in San Francisco. After entering data in the appropriate field on the module’s page https://en.archivarix.com/restore/, it takes a screenshot of the archived website and addresses the Web Archive API to request a list of files contained on the specified recovery date
