How to download an entire website from Google Cache?
If the website was recently deleted, but the Wayback Machine didn't save the latest version, what you can do to get the content? Google Cache will help you to do this. All you need is to install this plugin - https://www.downthemall.net/
1 - Install DownThemall plugin to your browser.
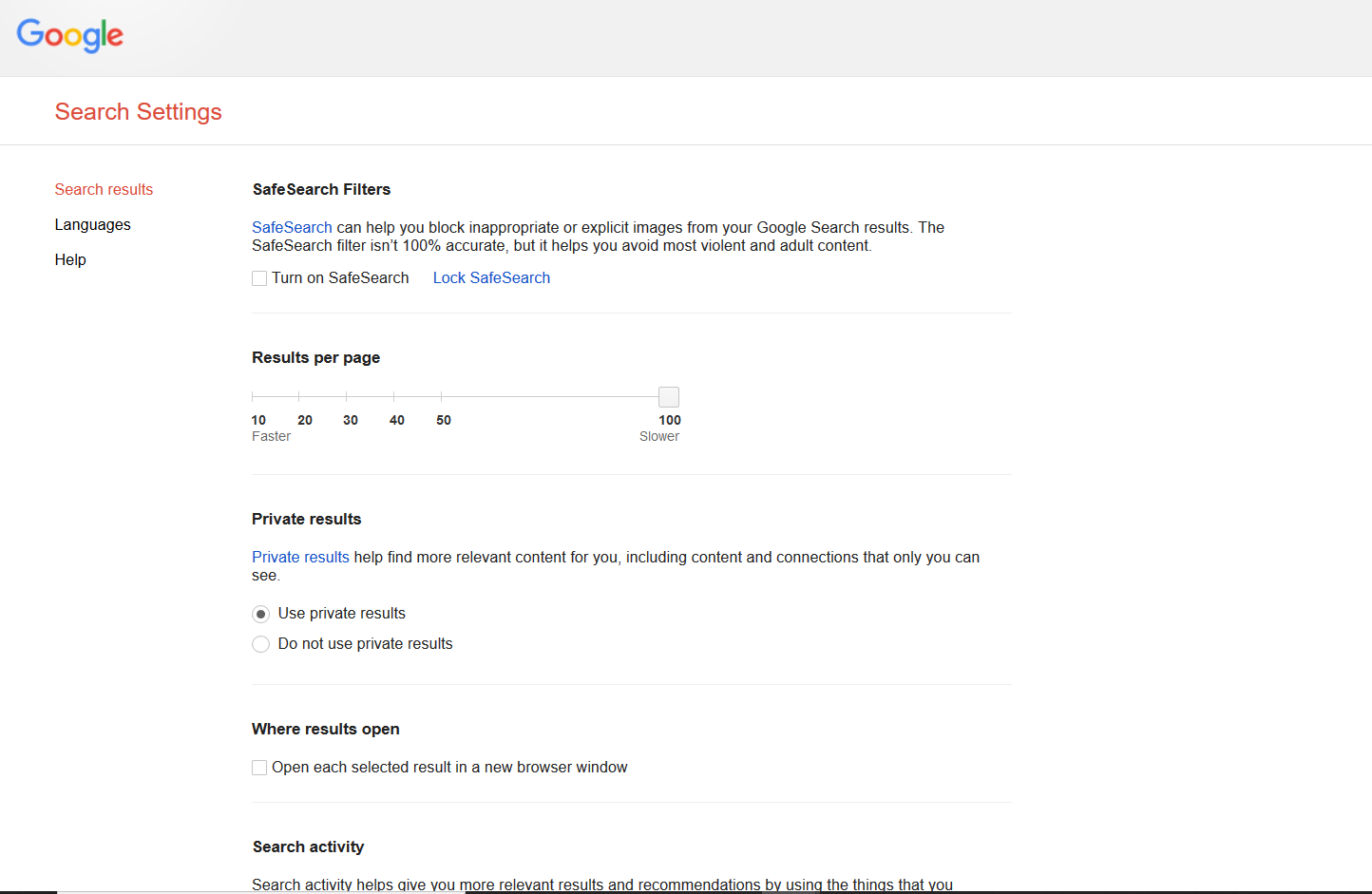
2 - Open Google Search in the browser and set "100 Results per page" in "Settings" - "Search Settings" menu. It will give you more downloadable cache pages per one click. Unfortunately 100 results are maximum in Google search:
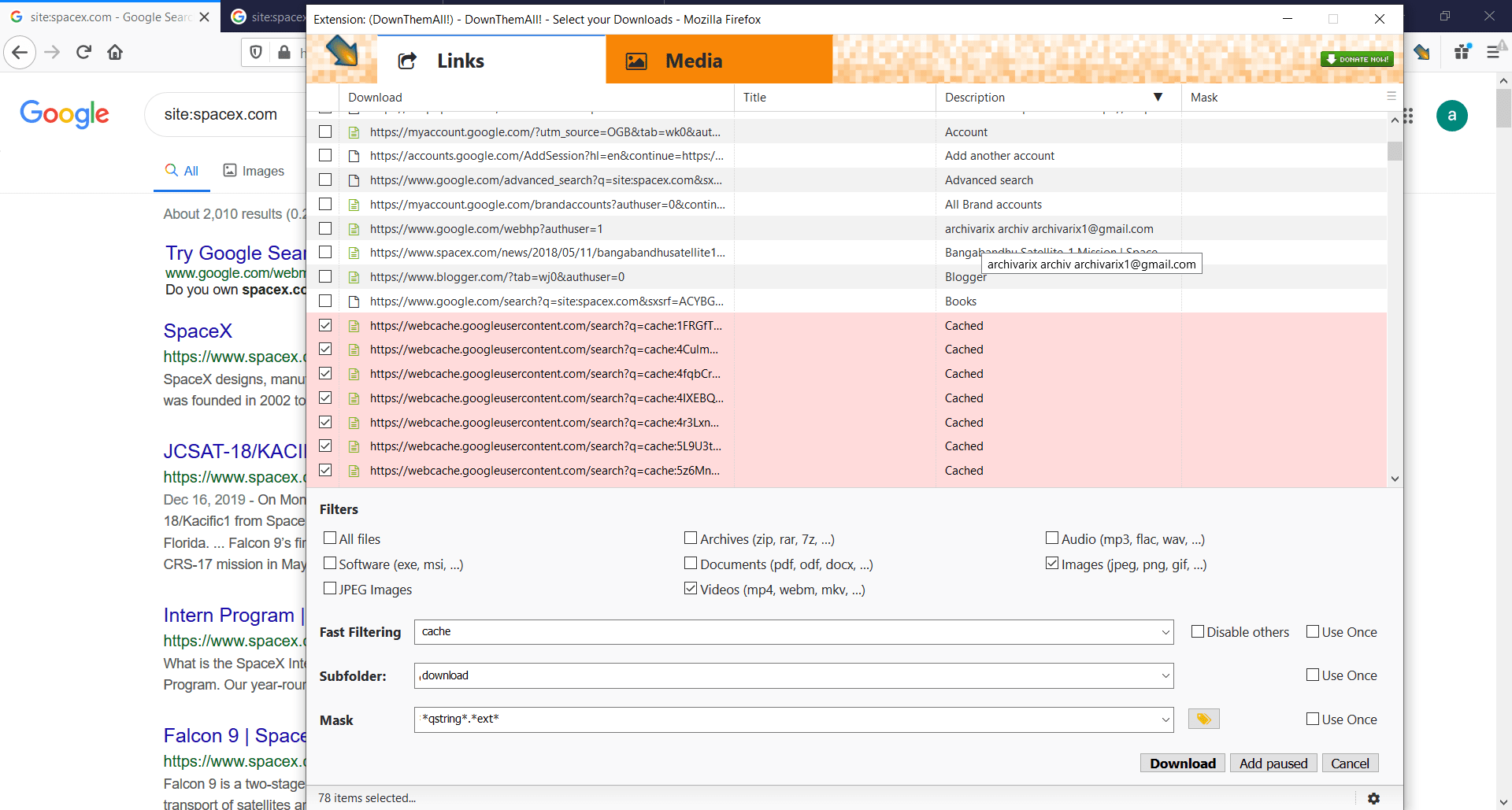
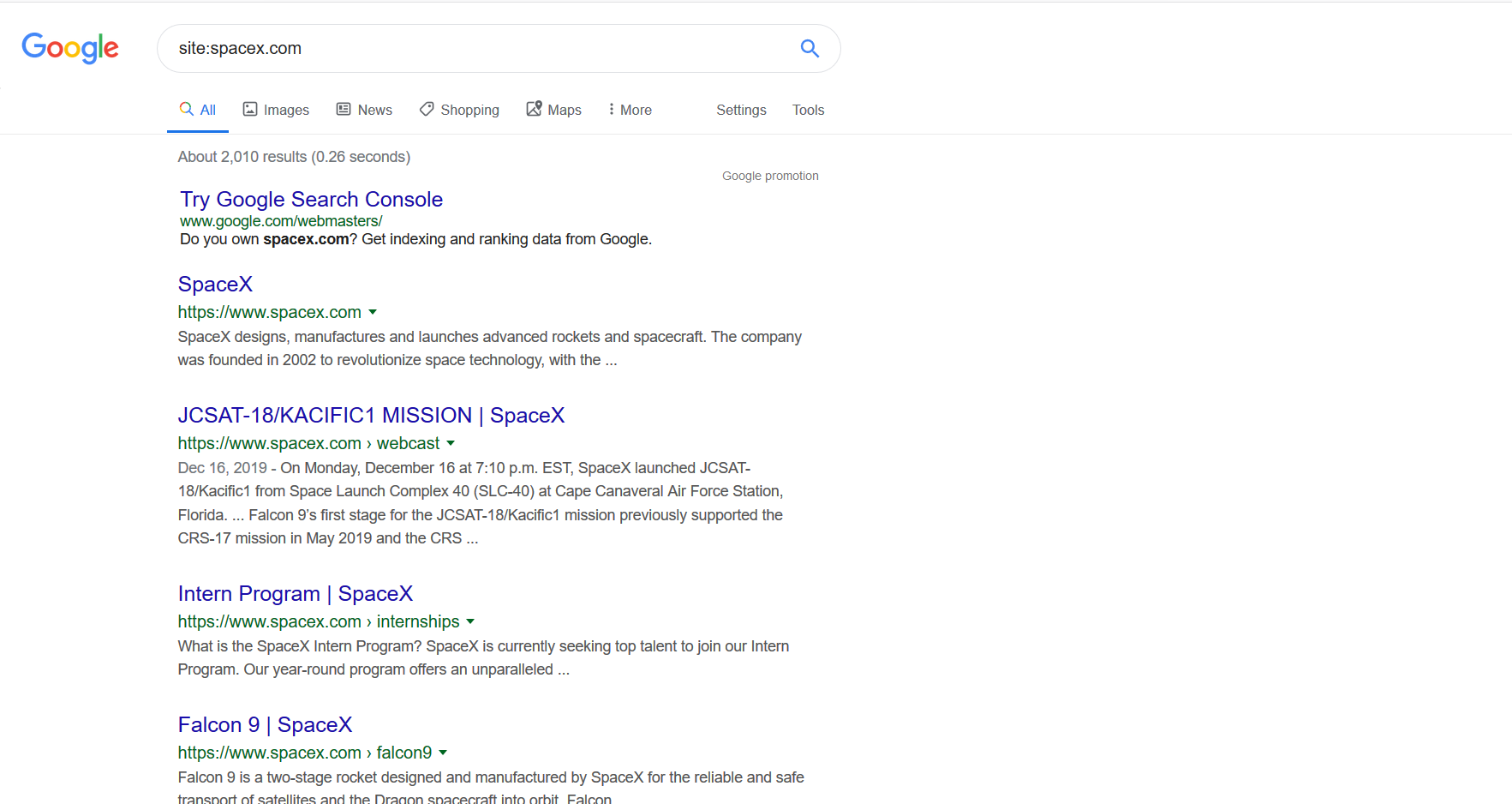
3 - Find on Google all cached pages of your site. Just enter in search field this: site:yourwebsite.com. Here is an example with spacex.com:
4 - In DownThemall plugin enter cache in "Fast Filtering" field. This regular expression will choose all of cached pages. Press Download button and wait for... download error.
5 - After 100 or more downloaded files Google will interrupt the process and ask you to verify yourself via captcha. DownThemall plugin can't solve captcha, it just stops downloading. So you need to return to Google search, open any search result, solve the captcha manually and restart the download process. It will give you next batch of files to download.
As you see the process is not fully automated but it is quite fast, and completely free. If you want to scrape thousands and millions cached pages the better way to buy some SEO tool with "google cache scraper" option.
The use of article materials is allowed only if the link to the source is posted: https://archivarix.com/en/blog/download-website-google-cache/

When you find a deleted YouTube video through Tube Search, you typically get metadata: a title, description, upload date, and sometimes subtitles. That is already useful. But reading through raw subti…
Tube Search is a search engine for archived YouTube data. The service aggregates information from multiple public sources: the Wayback Machine (Internet Archive), Common Crawl, and various collected Y…
Over time, external links in WordPress posts inevitably break, pages get deleted, domains expire, videos become unavailable. Checking hundreds or thousands of links manually is impractical. Archivarix…
One trillion saved pages. Over 99 petabytes of data. Hundreds of crawls running simultaneously every day. Behind these numbers lies a question that everyone who professionally works with web archives …
Buying an expired domain with history is one of the most effective ways to launch a new project with an already existing backlink profile, trust, and even traffic. Instead of promoting a bare domain f…
When it comes to restoring websites from archives, almost everyone thinks only of the Wayback Machine. That's understandable: archive.org is well known, it has a convenient interface, a trillion saved…
We've released a browser extension called Archivarix Cache Viewer. It's available for Chrome, Edge and Firefox. The extension is free and contains no ads whatsoever.
The idea is simple: quick access …
When you restore a website from the Web Archive, you expect to get original content that was once written by real people. But if the site's archives were made after 2023, there's a real chance of enco…
In October 2025, the Wayback Machine reached the milestone of one trillion archived web pages. Over 100,000 terabytes of data. This is a massive achievement for a nonprofit organization that has been …
We are pleased to introduce version 2.0 of our WordPress plugin for importing external images. This is not just an update, the plugin has been completely rewritten from scratch based on modern requir…