Онлайн сервис восстановления сайтов из Веб Архива.
Восстановите полностью работоспособную копию сайта!
Если вы не знаете на каком сайте из веб архива проверить нашу систему - скачайте тестовое восстановление.
Чтобы посмотреть восстановление локально без использования хостинга, рекомендуем установить XAMPP сервер на ваш компьютер. Во время установки вам достаточно выбрать только Apache и PHP.
Чтобы посмотреть восстановление локально без использования хостинга, рекомендуем установить XAMPP сервер на ваш компьютер. Во время установки вам достаточно выбрать только Apache и PHP.
Цены восстановления
Сайт содержит
до 200 файлов
- Сайты, которые содержат до 200 файлов, стоят всего $0.25.
Сайт содержит
201-1200 файлов
- Большинство сайтов, которые восстанавливают наши пользователи, содержат до 1000 файлов и стоят менее $4.
Сайт содержит
более 1200 файлов
- Если нужный вам сайт содержит более 1200 файлов, то каждая последующая тысяча файлов будет стоить всего один доллар.
Онлайн сервис скачивания сайтов и конвертации на CMS.
Скачайте полностью работоспособную копию сайта!
Возможность скачивать .onion сайты!
Если вы не знаете на каком сайте из веб архива проверить нашу систему - скачайте тестовое восстановление.
Чтобы посмотреть восстановление локально без использования хостинга, рекомендуем установить XAMPP сервер на ваш компьютер. Во время установки вам достаточно выбрать только Apache и PHP.
Чтобы посмотреть восстановление локально без использования хостинга, рекомендуем установить XAMPP сервер на ваш компьютер. Во время установки вам достаточно выбрать только Apache и PHP.
Цены скачивания
Сайт содержит
до 200 файлов
- Сайты, которые содержат до 200 файлов, стоят всего $0.25.
Сайт содержит
201-1200 файлов
- Большинство сайтов, которые скачивают наши пользователи, содержат до 1000 файлов и стоят менее $4.
Сайт содержит
более 1200 файлов
- Если нужный вам сайт содержит более 1200 файлов, то каждая последующая тысяча файлов будет стоить всего один доллар.
Последние статьи из блога:
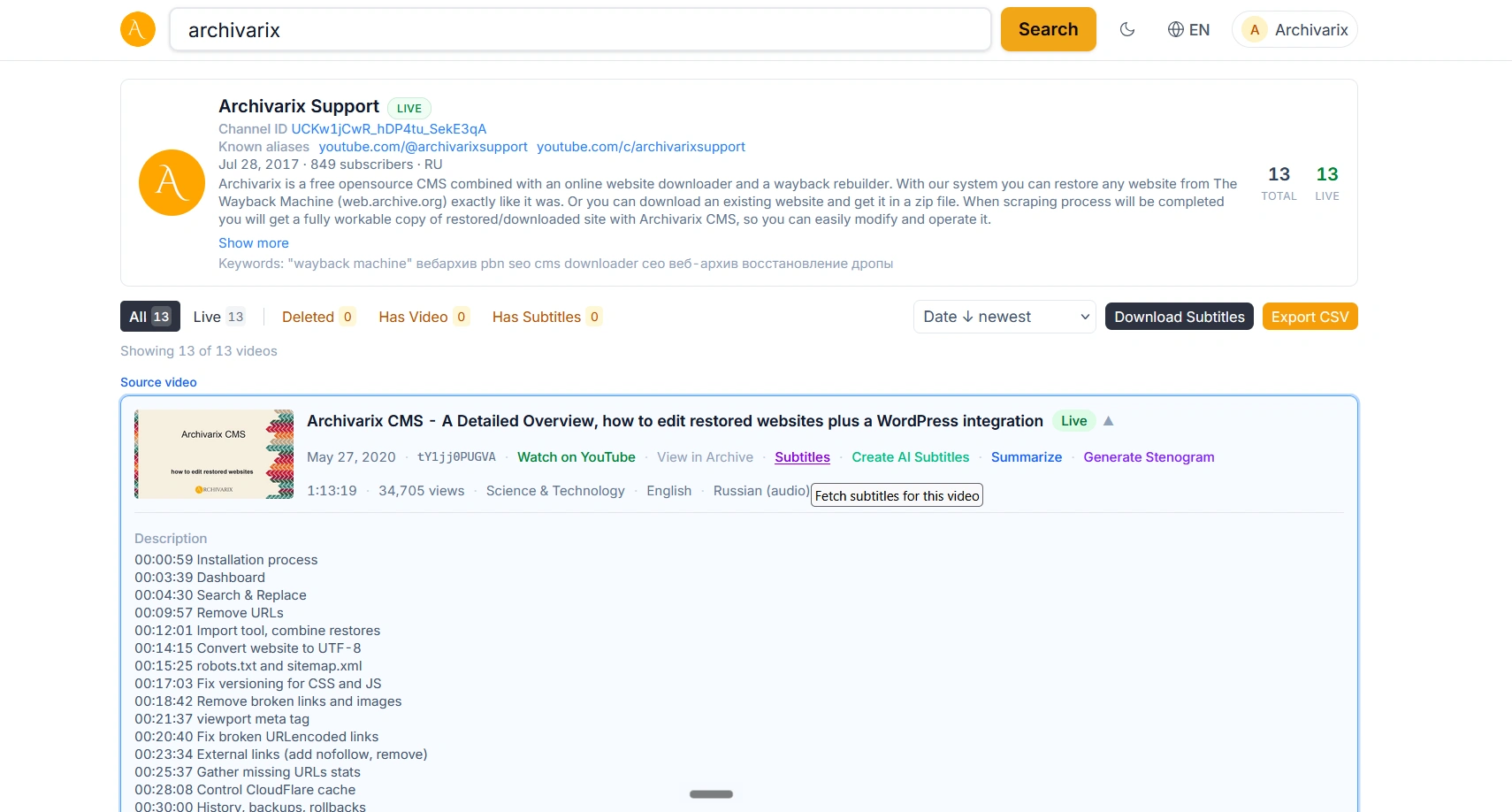
Как скачать субтитры с YouTube, даже с удалённых видео
Вы нашли на YouTube нужное видео, но не хотите его смотреть целиком ради пары фраз. Или вам нужен текст лекции, чтобы перевести его, процитировать или просто прочитать по диагонали. Субтитры YouTube решают эту задачу, но скопировать их с самого сайта не так просто: интерфейс не даёт кнопки «скачать», а сторонние сервисы часто ломаются или требуют оплаты. В Archivarix Tube Search есть простой способ получить субтитры любого видео, и, что важнее, у нас это работает даже для тех роликов, которые уже удалены с YouTube.
Читать дальше…
Сколько живёт веб-страница: что говорят исследования о link rot
Откройте любую статью десятилетней давности и пройдитесь по ссылкам в ней. С большой вероятностью часть из них уже никуда не ведёт. Вместо нужной страницы вас встретит ошибка 404, припаркованный домен с рекламой дешёвой страховки или редирект на чужой сайт. Это явление называется link rot, «гниение ссылок», и оно куда масштабнее, чем принято думать.
Читать дальше…
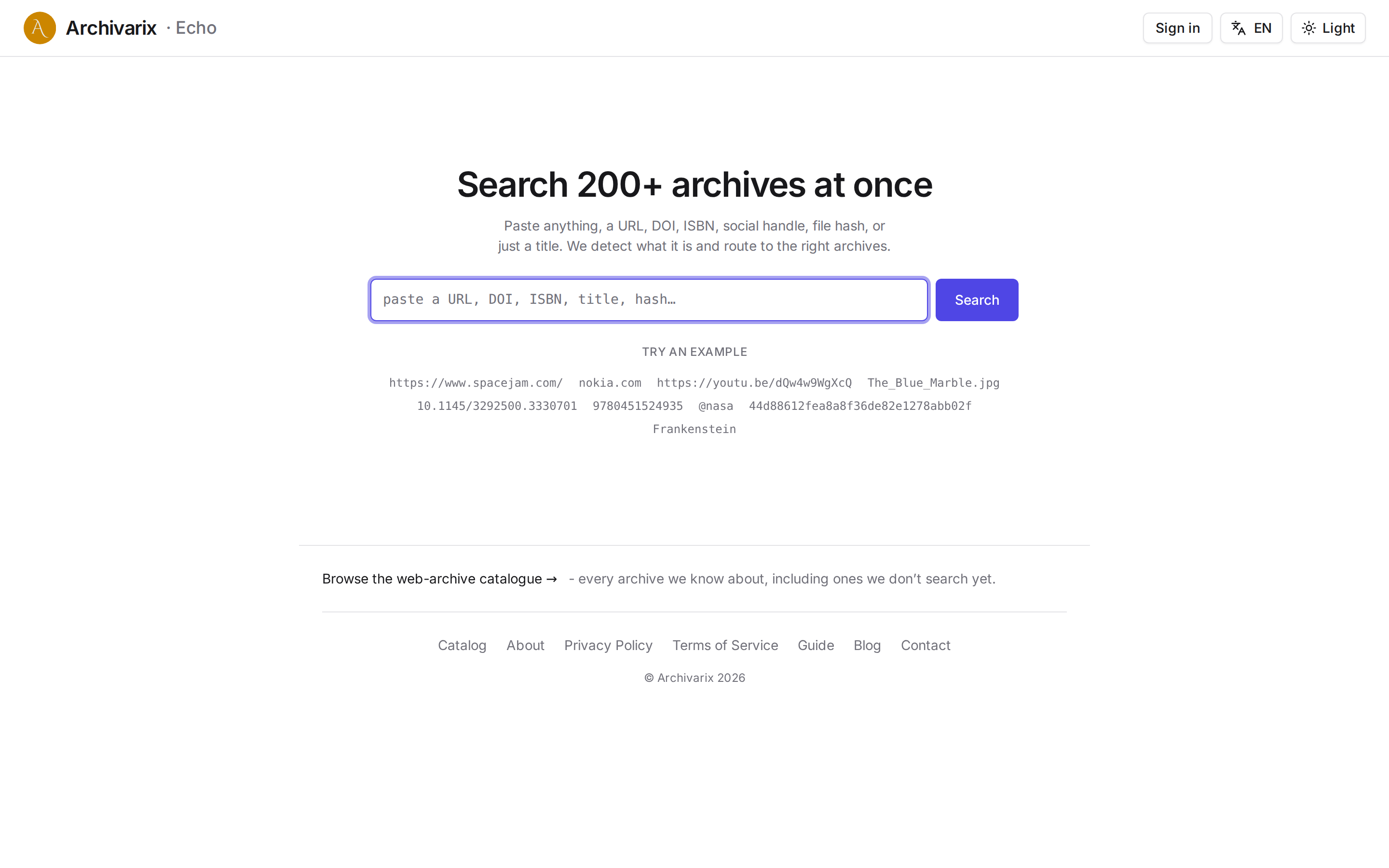
Archivarix Echo: проверьте 200+ веб-архивов одним запросом
Интернет постоянно осыпается. Страницы уходят в офлайн, аккаунты удаляют, статьи прячут за пейволл, проекты закрывают. Но копии чаще всего где-то остаются: Wayback Machine, archive.today, Common Crawl, научные индексы вроде Crossref, библиотеки вроде Open Library и ещё сотни узких, тематических архивов. Беда в том, что все они порознь. Чтобы понять, где что сохранилось, раньше приходилось открывать их по очереди: сначала Wayback, потом archive.today, потом десяток научных и книжных баз.
Читать дальше…
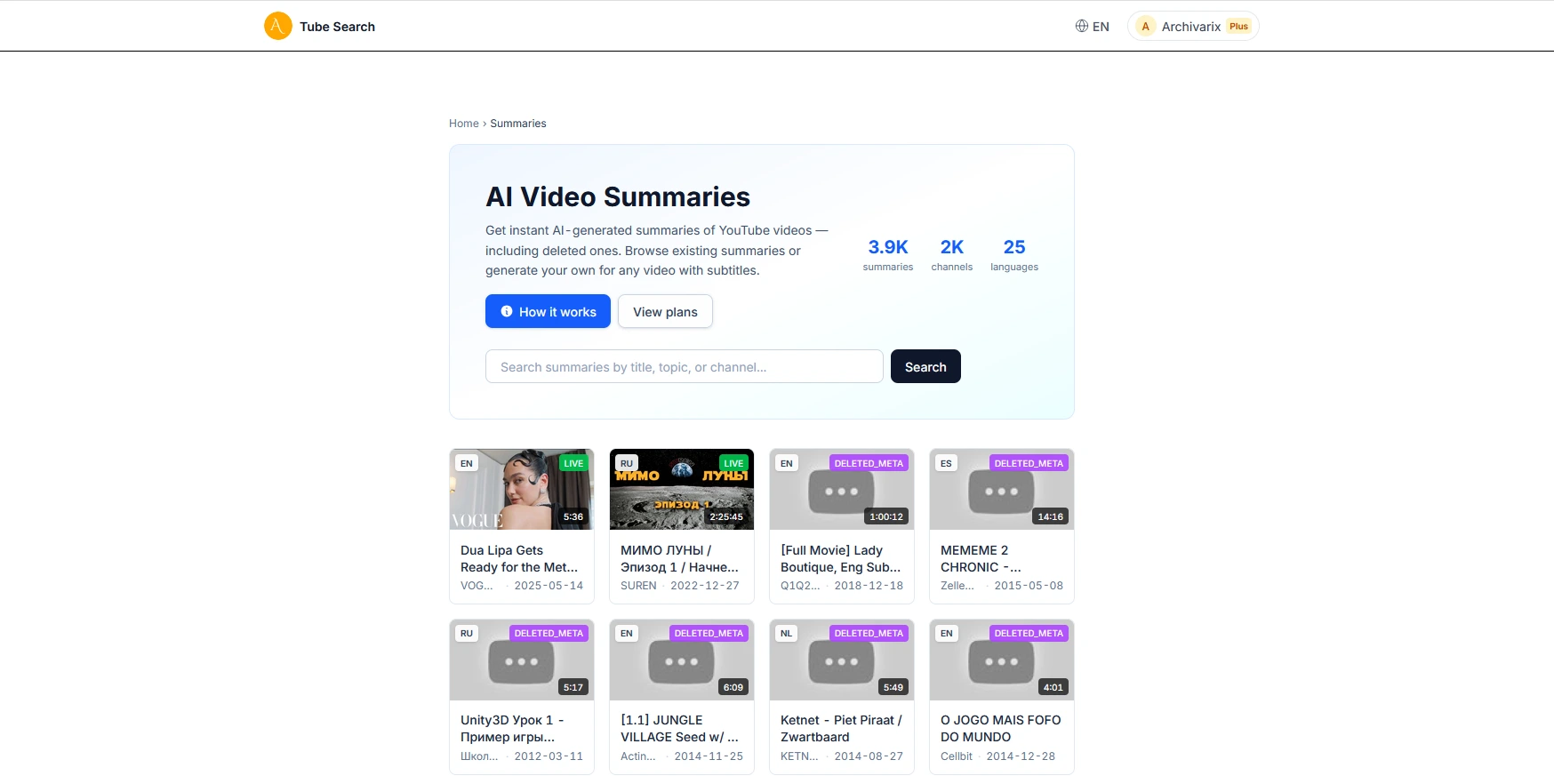
AI-саммари видео в Archivarix Tube Search
Когда вы находите удалённое видео YouTube через Tube Search, вы обычно получаете метаданные: название, описание, дату загрузки и иногда субтитры. Это уже полезно. Но чтение необработанных субтитров, чтобы понять, о чём было видео, требует времени, особенно для длинных записей.
Мы добавили в Tube Search AI-саммари видео. Если у видео есть архивные субтитры, система может за считанные секунды сгенерировать структурированное изложение его содержания.
Читать дальше…
Мы добавили в Tube Search AI-саммари видео. Если у видео есть архивные субтитры, система может за считанные секунды сгенерировать структурированное изложение его содержания.

Archivarix Tube Search - Поисковая система по удаленным видео YouTube
Tube Search - это поисковый движок по архивным данным YouTube. Сервис агрегирует информацию из нескольких публичных источников: Wayback Machine (Internet Archive), Common Crawl и различных собранных датасетов метаданных YouTube. Когда видео удаляется с YouTube, его страница перестает существовать. Но если до удаления эту страницу успел проиндексировать один из веб-архивов, метаданные видео сохраняются: название, описание, дата загрузки, количество просмотров, превью-изображения, субтитры.
Читать дальше…