从网页档案中恢复站点在线服务
恢复您网站的全功能副本!
如果您不知道从 Web 存档中的哪个网站上检查我们的系统,请下载测试恢复。
要在不托管的情况下在本地查看恢复,我们建议您在计算机上安装XAMPP 服务器。在安装过程中,您只需要选择Apache和PHP。
要在不托管的情况下在本地查看恢复,我们建议您在计算机上安装XAMPP 服务器。在安装过程中,您只需要选择Apache和PHP。
恢复价格
该网站包含
最多200个文件
- 包含最多 200 个文件的网站仅需 0.25 美元。
该网站包含
201-1200个文件
- 我们的用户恢复的大多数网站,包含有高达1000文件而费用不到4美元。
该网站包含
超多1200个文件
- 如果您需要的站点包含超过 1200 个文件,那么每增加 1000 个文件只需花费 1 美元。
下载现有网站并移植到 CMS 的在线服务。
下载该网站的全功能副本!
能够下载.onion网站!
如果您不知道从 Web 存档中的哪个网站上检查我们的系统,请下载测试恢复。
要在不托管的情况下在本地查看恢复,我们建议您在计算机上安装XAMPP 服务器。在安装过程中,您只需要选择Apache和PHP。
要在不托管的情况下在本地查看恢复,我们建议您在计算机上安装XAMPP 服务器。在安装过程中,您只需要选择Apache和PHP。
下载价格
该网站包含
最多200个文件
- 包含最多 200 个文件的网站仅需 0.25 美元。
该网站包含
201-1200个文件
- 我们的用户下载的大多数网站包含多达1000个文件, 成本低于4美元。
该网站包含
超多1200个文件
- 如果您需要的站点包含超过 1200 个文件,那么每增加 1000 个文件只需花费 1 美元。
最新博客文章:
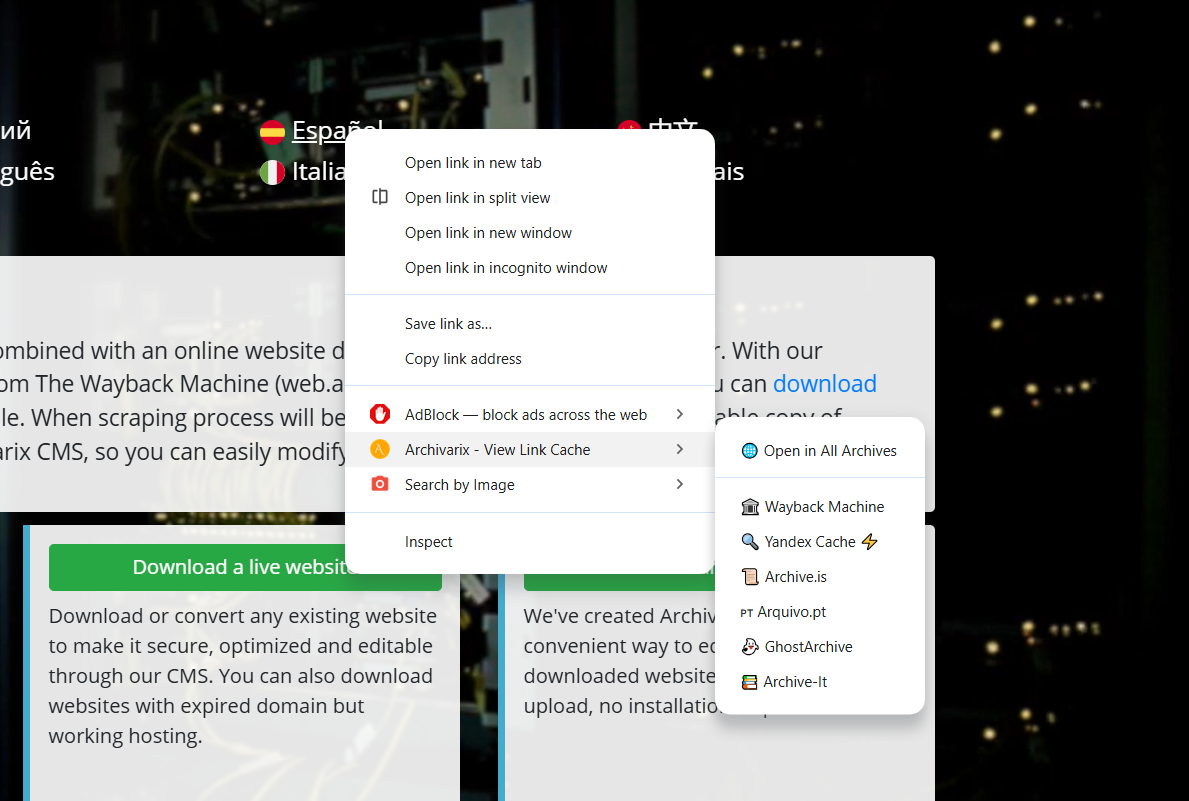
Archivarix Cache Viewer 浏览器扩展 - 支持 Chrome 和 Firefox
我们发布了一个名为 Archivarix Cache Viewer 的浏览器扩展。它同时支持 Chrome 和 Firefox。扩展完全免费,没有任何广告。
原理很简单:直接从浏览器的右键菜单快速访问任何网页的缓存和存档版本。不用再手动复制URL、打开 Wayback Machine 然后粘贴地址了。右键点击,选择你需要的存档,搞定。
阅读更多…
原理很简单:直接从浏览器的右键菜单快速访问任何网页的缓存和存档版本。不用再手动复制URL、打开 Wayback Machine 然后粘贴地址了。右键点击,选择你需要的存档,搞定。
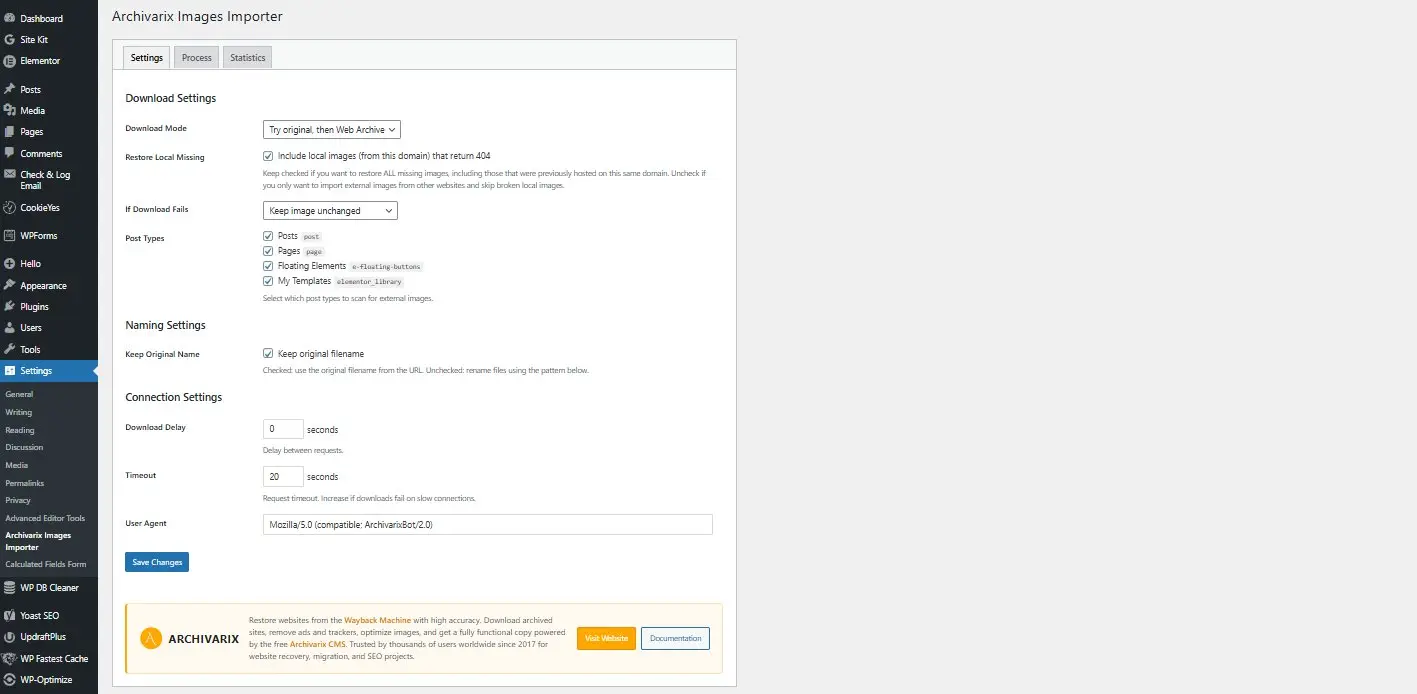
Archivarix External Images Importer 2.0 — WordPress 插件新版本
我们很高兴推出 WordPress 外部图片导入插件 2.0 版本。这不仅仅是一次更新——该插件已根据现代需求和用户反馈从头完全重写。
阅读更多…

Archivarix CMS中使用的正则表达式
本文介绍了用于搜索和替换使用Archivarix System还原的网站中的内容的正则表达式。 它们不是该系统独有的。 如果您知道PHP,Perl,Java或其他编程语言的正则表达式,那么您已经知道如何使用我们的搜索和替换。 如果没有,我们希望本文对您有所帮助。
阅读更多…
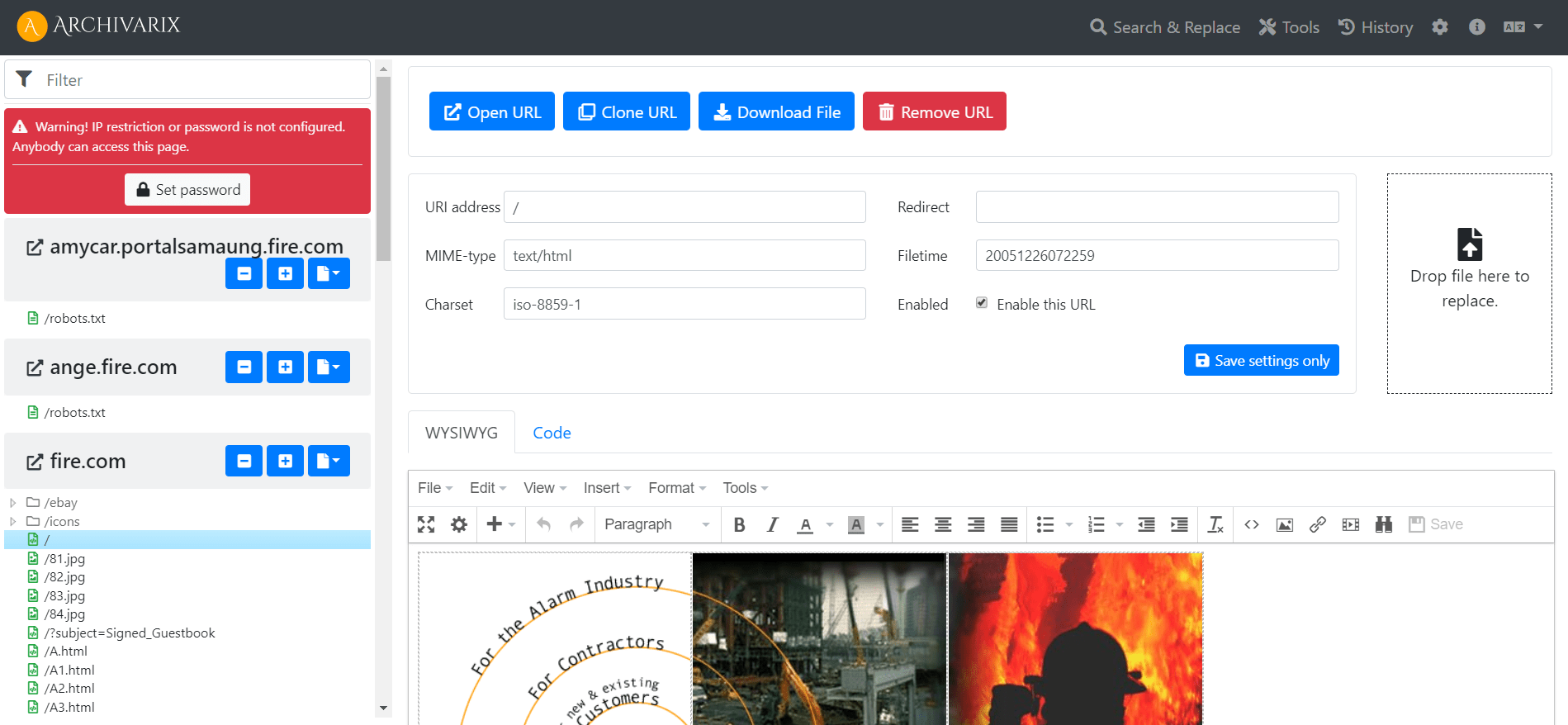
简单紧凑的Archivarix CMS。 用于下载网站的平面文件CMS。
为了方便您编辑在我们系统中还原的网站,我们开发了一个仅包含一个小php文件的简单平面文件CMS。 尽管尺寸庞大,但此CMS是用于处理您的网站的功能强大且用途广泛的工具。 它提供了任何CMS的所有基本功能,以及网站管理员根据从Web存档还原的内容创建PBN的特殊功能。
阅读更多…
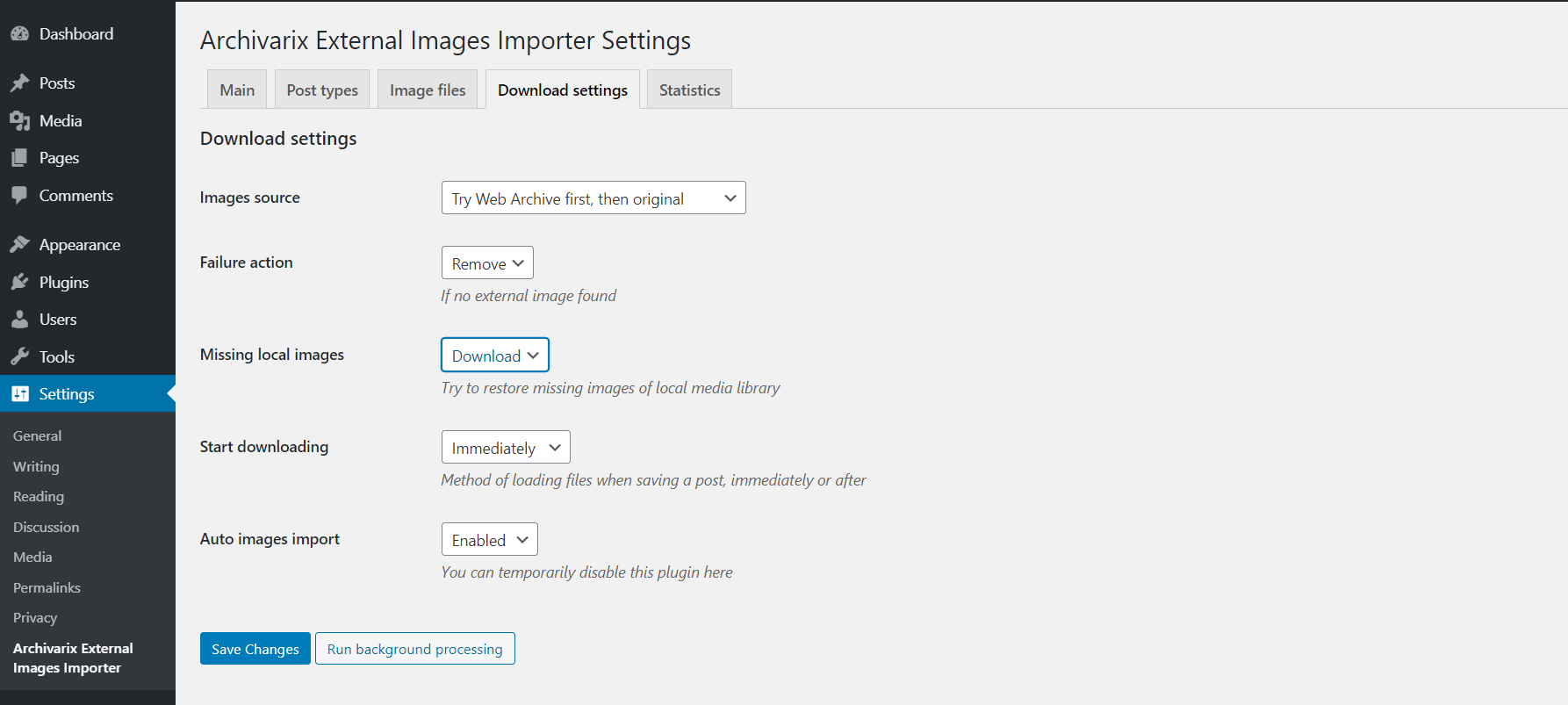
如何将内容从Wayback Machine(archive.org)传输到Wordpress?
通过使用“提取结构化内容”选项,您可以轻松地从Web存档上的站点和任何其他站点创建Wordpress博客。为此,首先找到源站点,然后在“还原网站”或“下载网站”工具中选中“提取结构化内容”选项。输入您的选项(电子邮件,时间戳等),然后开始下载。
阅读更多…