
Archivarix is 8 years old!
Dear friends!
Today we celebrate Archivarix's 8th anniversary, and it's the perfect occasion to say a huge thank you!
We are truly grateful that you chose our service for website recovery from web archives. Many of you use Archivarix on a regular basis, and this inspires us to keep improving.
Read more…
Today we celebrate Archivarix's 8th anniversary, and it's the perfect occasion to say a huge thank you!
We are truly grateful that you chose our service for website recovery from web archives. Many of you use Archivarix on a regular basis, and this inspires us to keep improving.

7 Years of Archivarix
Today is a special day — Archivarix is celebrating its 7th anniversary! We want to thank you for your trust, ideas, and feedback, which have helped us become the best service for restoring websites from the Wayback Machine.
Read more…

To everyone who has been waiting for top-up discounts!
Dear Archivarix users, Congratulations on the upcoming holidays and thank you for choosing our service to archive and restore your websites!
Read more…

6 Years of Archivarix
It's that special time when we take a moment to reflect not just on our achievements, but also on the incredible journey we've shared with you. This year, Archivarix celebrates its 6th anniversary, and foremost, we want to extend our heartfelt gratitude to you, our dedicated users.
Read more…

4 years of Archivarix!
It has been four years since we made the Archivarix service public on September 29, 2017. Users make thousands of restorations every day. The number of servers that distribute downloads and processing among themselves consistently exceeds 40, and the system automatically adds new machines under load.
Read more…
What can be recovered from the Web Archive?
Sometimes our users ask why the website was not fully restored? Why the website doesn't it work the way I would like it to? Known issues when restoring sites from archive.org.
Read more…
Happy 3rd birthday to Archivarix
Three years ago, on September 29, 2017, our archive.org downloader service was launched. All these 3 years we have been continuously developing, we have created our own CMS, a Wordpress plugin, a system for downloading live sites, significantly improved and accelerated the recovery algorithm and much more.
Read more…
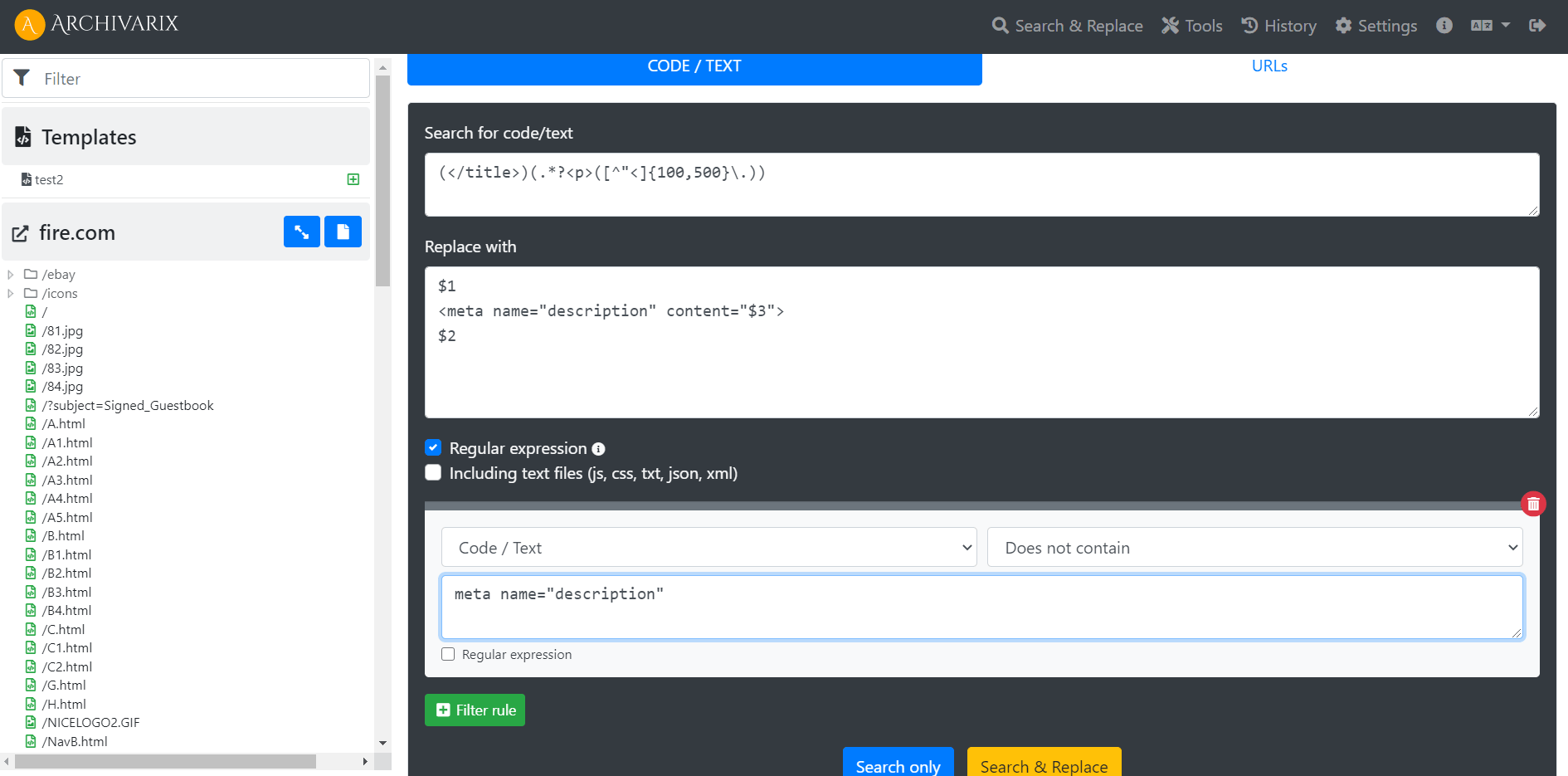
Examples of using regular expressions in Archivarix CMS
How to generate meta name="description" on all pages of a website? How to make the site work not from the root, but from a subdirectory?
Read more…
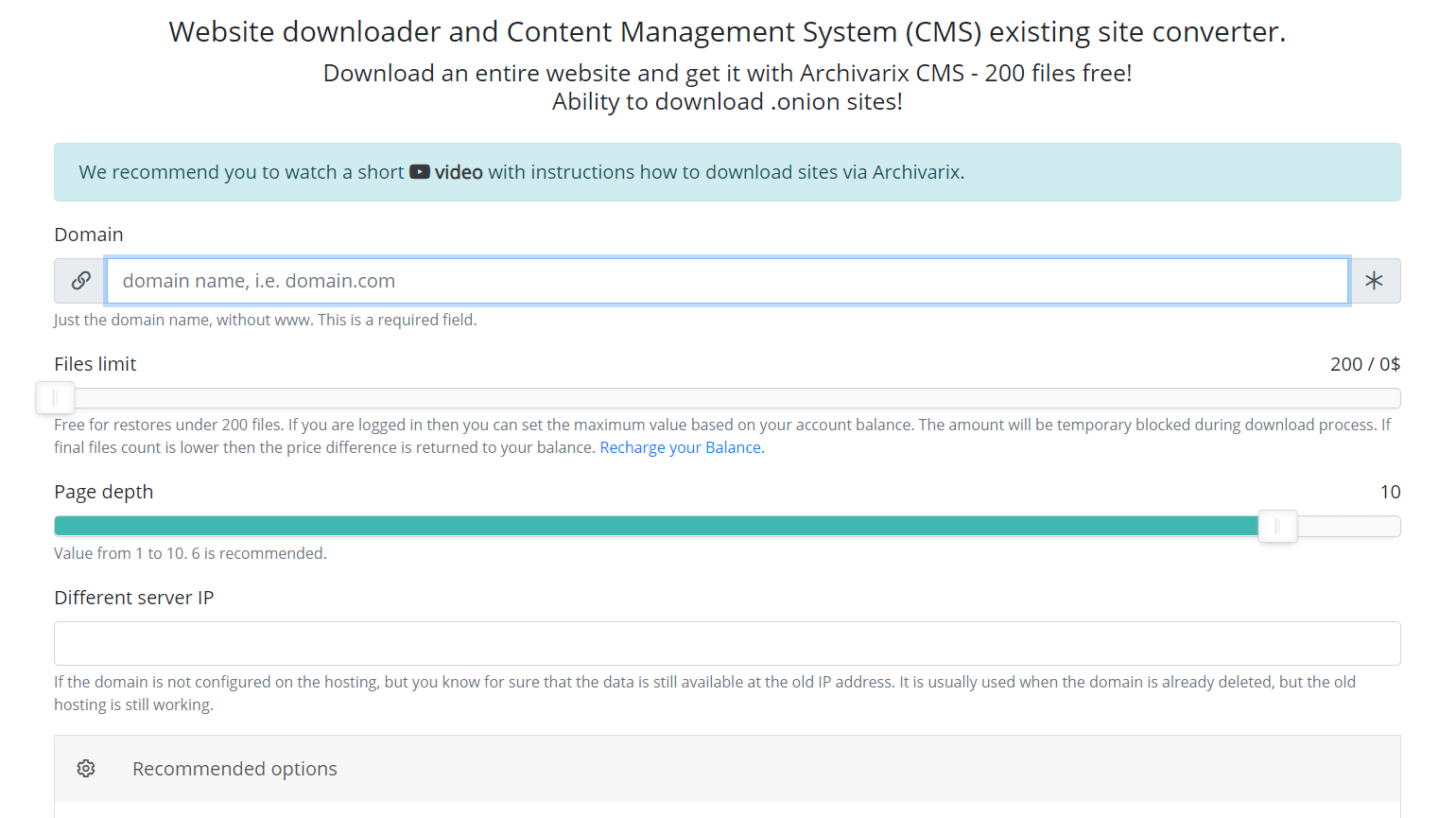
Website downloader. How to choose the files limit?
Our Website downloader system allows you to download up to 200 files from a website for free. If there are more files on the site and you need all of them, then you can pay for this service. Download cost depends on the number of files. How to find out how many files are really on the website and how much it will cost to download them?
Read more…
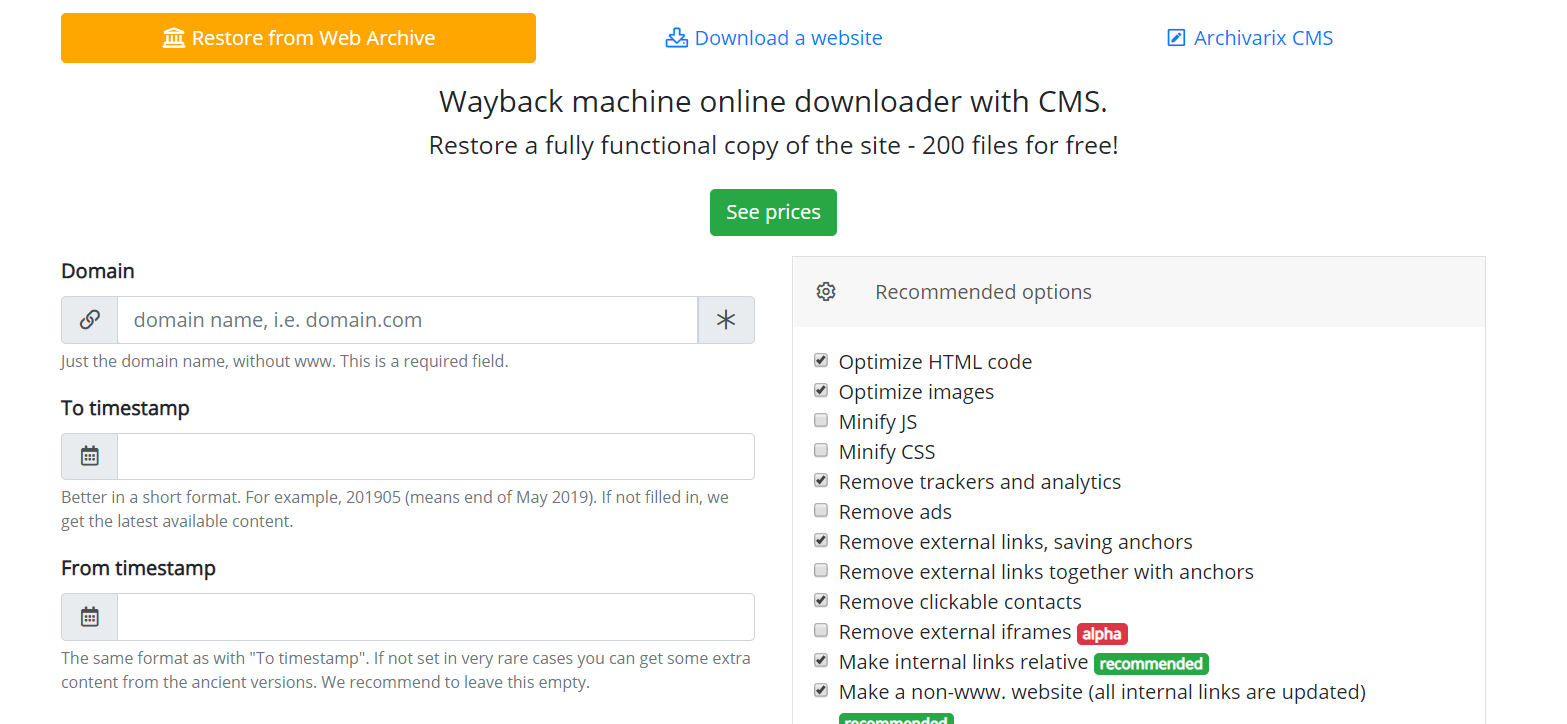
How does Archivarix work?
The Archivarix system is designed to download and restore sites that are no longer accessible from Web Archive, and those that are currently online. This is the main difference from the rest of “downloaders” and “site parsers”. Archivarix goal is not only to download, but also to restore the website in a form that it will be accessible on your server.
Let's start with the module that downloads websites from Web Archive. These are virtual servers located in California. Their location was chosen in such a way as to obtain the maximum possible connection speed with the Web Archive itself, because its servers are located in San Francisco. After entering data in the appropriate field on the module’s page https://en.archivarix.com/restore/, it takes a screenshot of the archived website and addresses the Web Archive API to request a list of files contained on the specified recovery date
Read more…
Let's start with the module that downloads websites from Web Archive. These are virtual servers located in California. Their location was chosen in such a way as to obtain the maximum possible connection speed with the Web Archive itself, because its servers are located in San Francisco. After entering data in the appropriate field on the module’s page https://en.archivarix.com/restore/, it takes a screenshot of the archived website and addresses the Web Archive API to request a list of files contained on the specified recovery date
