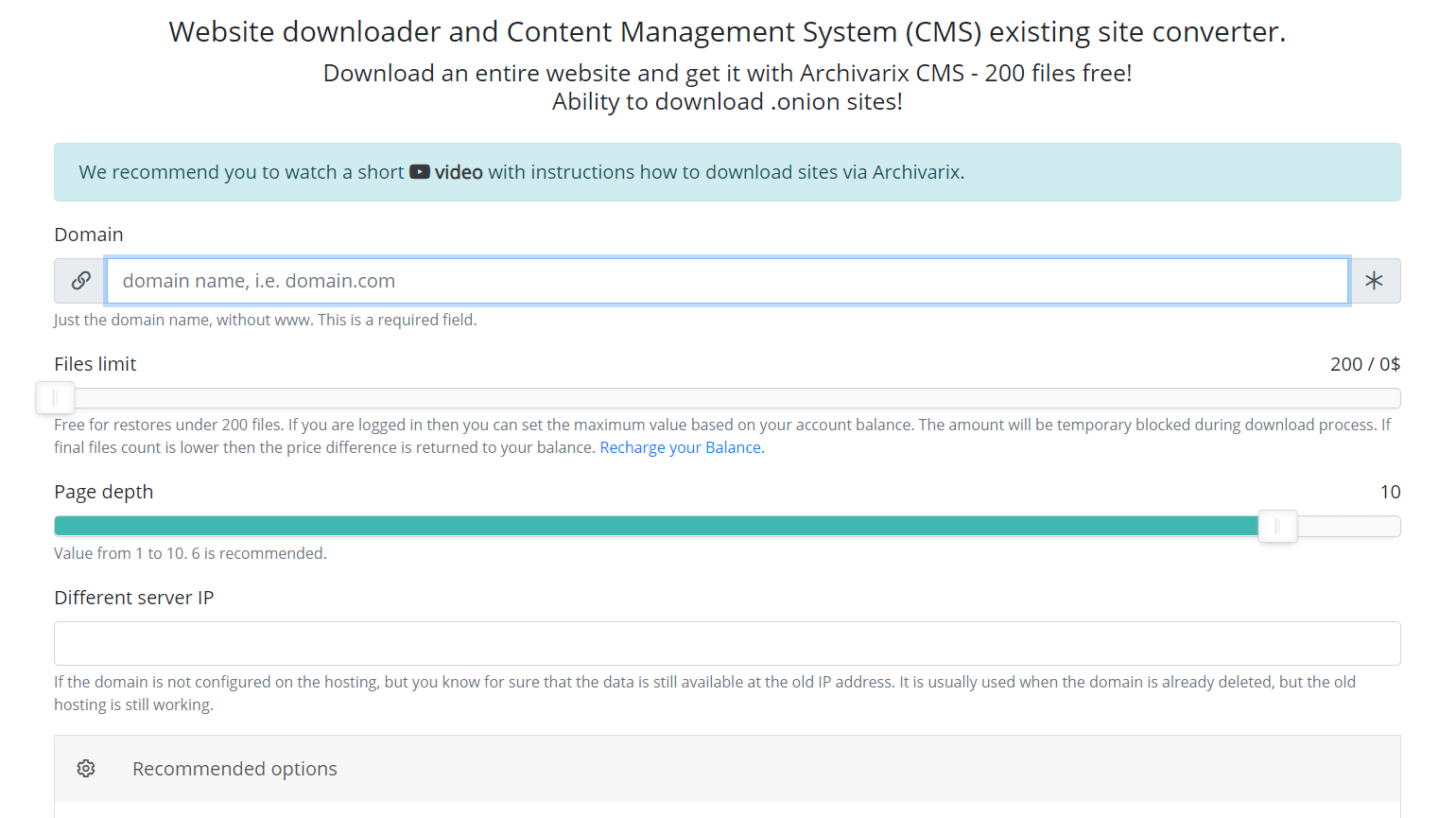
Website downloader. How to choose the files limit?
Our Website downloader system allows you to download up to 200 files from a website for free. If there are more files on the site and you need all of them, then you can pay for this service. Download cost depends on the number of files. How to find out how many files are really on the website and how much it will cost to download them?
First, you need to point out that the number of site files is almost always greater than the number of site pages . It will be the same only when all the pages of the site are pure html files, without pictures, CSS, scripts and so on. This can only be seen on the very first Internet site, which was created in 1991 - http://info.cern.ch/ . If your website does not look like an artifact from the early web, then it will have much more files. But how to count them?
Only the administrator can know exactly how many files are on the website. If you do not have full access to the website, then you can count the files only approximately. The easiest way to calculate how many files on it is to check what was indexed by Archive.org by using our recovering sites from The Web Archive system. Fill the "Domain" field, and left empty "To timestamp" and "From timestamp". Click the "Restore" button and wait for a screenshot of the site with file counting? it will come to your e-mail. It should know that this number shows only how many files were indexed by the Web Archive, not how many actually are on it now. They can be either more or less.
The next way is to calculate the number of pages in sitemap.xml. This file is usually located at yourwebsite.com/sitemap.xml or its position can be specified in robots.txt. From the obtained number of pages, you can roughly estimate how many files are on the site. On average, a website has 2 times more files than pages. But if the site contains a lot of graphics, then the files / pages ratio can be much higher.
If there is there is no Sitemap on the site, you can find out the number of pages in Google using a simple request https://www.google.com/search?q=site: yourwebsite.com. But it will show only the number of indexed pages, not how many pages are actually on the site.
Important notice! We do not recommend to download sites with automatically generated content or sites with automatically generated internal links. Such websites contain an "infinite" number of files.
The use of article materials is allowed only if the link to the source is posted: https://archivarix.com/en/blog/website-downloader/

The Archivarix system is designed to download and restore sites that are no longer accessible from Web Archive, and those that are currently online. This is the main difference from the rest of “downl…
By using the “Extract structured content” option you can easily make a Wordpress blog both from the site found on the Web Archive and from any other website. To do this, firstly find the source websit…
In order to make it convenient for you to edit the websites restored in our system, we have developed a simple Flat File CMS consisting of just one small php file. Despite its size, this CMS is a powe…
This article describes regular expressions used to search and replace content in websites restored using the Archivarix System. They are not unique to this system. If you know the regular expressions …
Our Website downloader system allows you to download up to 200 files from a website for free. If there are more files on the site and you need all of them, then you can pay for this service. Download …