Come funziona Archivarix?
Il sistema Archivarix è progettato per scaricare e ripristinare siti non più accessibili da Web Archive e quelli attualmente online. Questa è la differenza principale rispetto al resto dei "downloader" e dei "parser del sito". L'obiettivo di Archivarix non è solo quello di scaricare, ma anche di ripristinare il sito Web in una forma che sarà accessibile sul tuo server.
Cominciamo con il modulo che scarica i siti Web da Web Archive. Questi sono server virtuali situati in California. La loro posizione è stata scelta in modo tale da ottenere la massima velocità di connessione possibile con il Web Archive stesso, poiché i suoi server si trovano a San Francisco. Dopo aver inserito i dati nell'apposito campo nella pagina del modulo https://it.archivarix.com/restore/, prende uno screenshot del sito Web archiviato e si rivolge all'API Web Archive per richiedere un elenco di file contenuti nella data di recupero specificata .
Dopo aver ricevuto una risposta alla richiesta, il sistema genera un messaggio con l'analisi dei dati ricevuti. L'utente deve solo premere il pulsante di conferma nel messaggio ricevuto per iniziare a scaricare il sito Web.
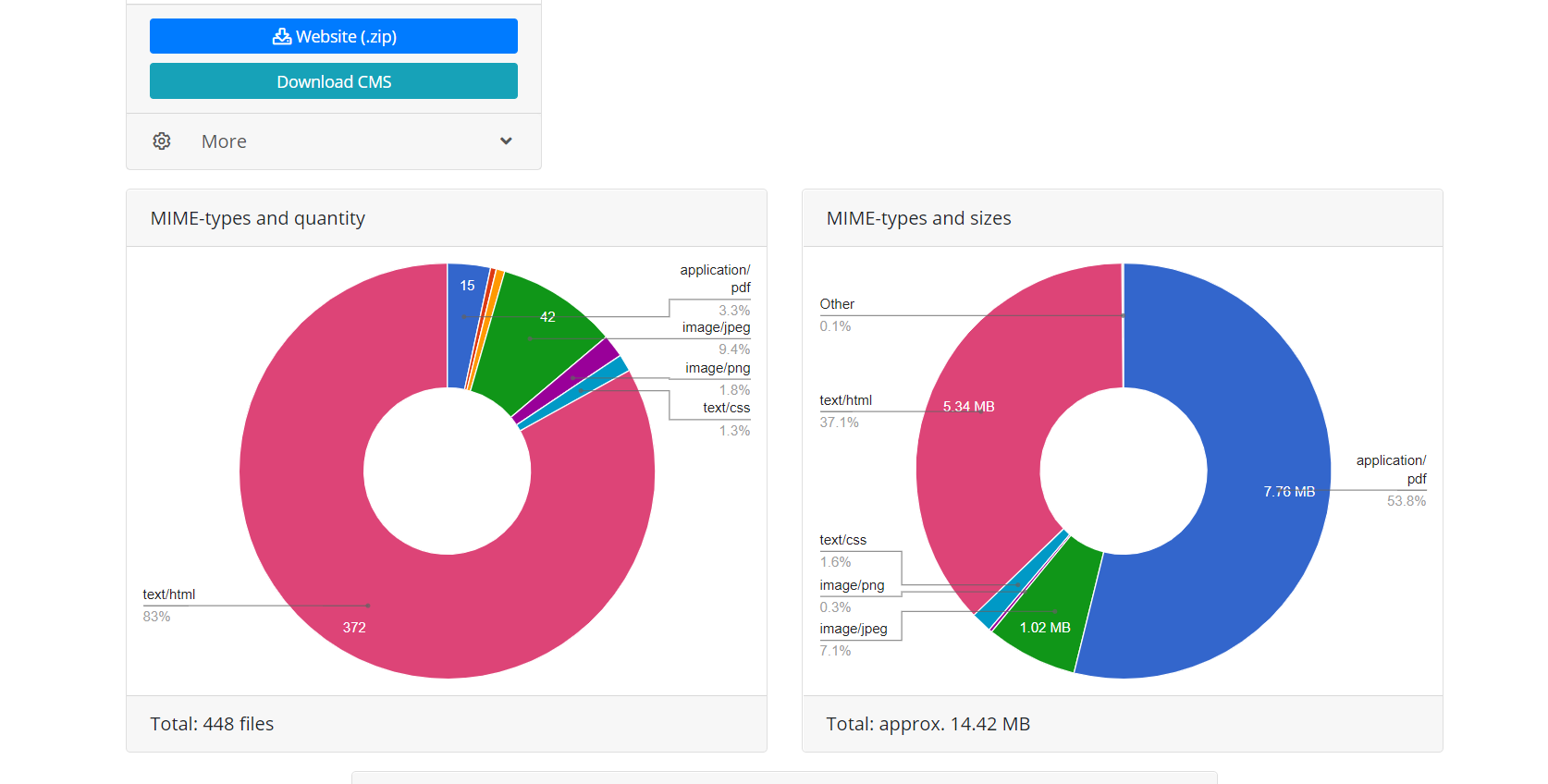
L'uso dell'API Web Archive offre due vantaggi rispetto al download diretto quando lo script segue semplicemente i collegamenti del sito Web. Innanzitutto, tutti i file di questo recupero sono immediatamente noti, è possibile stimare il volume del sito Web e il tempo necessario per scaricarlo. A causa della natura dell'operazione Web Archive, a volte funziona in modo molto instabile, quindi sono possibili interruzioni della connessione o download incompleto dei file, pertanto l'algoritmo del modulo verifica costantemente l'integrità dei file ricevuti e in tali casi tenta di scaricare il contenuto ricollegandosi a il server Web Archive. In secondo luogo, a causa delle peculiarità dell'indicizzazione del sito Web tramite Web Archive, non tutti i file del sito Web possono avere collegamenti diretti, il che significa che quando si tenta di scaricare un sito Web semplicemente seguendo i collegamenti, questi non saranno disponibili. Pertanto, il ripristino tramite l'API Web Archive utilizzata da Archivarix consente di ripristinare la massima quantità possibile di contenuto del sito Web archiviato per una data specifica.
Dopo aver completato l'operazione, il modulo di download dall'archivio Web trasferisce i dati al modulo di elaborazione. Forma un sito Web dai file ricevuti adatto per l'installazione su server Apache o Nginx. Il funzionamento del sito Web si basa sul database SQLite, quindi per iniziare è sufficiente caricarlo sul server e non è necessaria l'installazione di moduli aggiuntivi, database MySQL e la creazione dell'utente. Il modulo di elaborazione ottimizza il sito Web creato; include l'ottimizzazione delle immagini, nonché la compressione CSS e JS. Potrebbe aumentare significativamente la velocità di download del sito Web ripristinato, se confrontato con il sito Web originale. La velocità di download di alcuni siti Wordpress non ottimizzati con un sacco di plugin e file multimediali non compressi può essere notevolmente aumentata dopo l'elaborazione da questo modulo. È ovvio che se il sito Web è stato inizialmente ottimizzato, ciò non aumenterà notevolmente la velocità di download.
Il modulo di elaborazione rimuove la pubblicità, i contatori e le analisi controllando i file ricevuti rispetto a un ampio database di fornitori di pubblicità e analisi. La rimozione di collegamenti esterni e contatti cliccabili avviene semplicemente tramite il codice di checksum. In generale, questo algoritmo esegue una pulizia abbastanza efficiente del sito Web delle "tracce del precedente proprietario", sebbene a volte ciò non escluda la necessità di correggere manualmente qualcosa. Ad esempio, l'algoritmo non eliminerà uno script Java auto-scritto che reindirizza l'utente del sito Web a un determinato sito Web di monetizzazione. A volte è necessario aggiungere immagini mancanti o rimuovere residui non necessari, come libro degli ospiti spammato. Pertanto, è necessario assumere un editor del sito Web risultante. Ed esiste già. Si chiama Archivarix CMS.
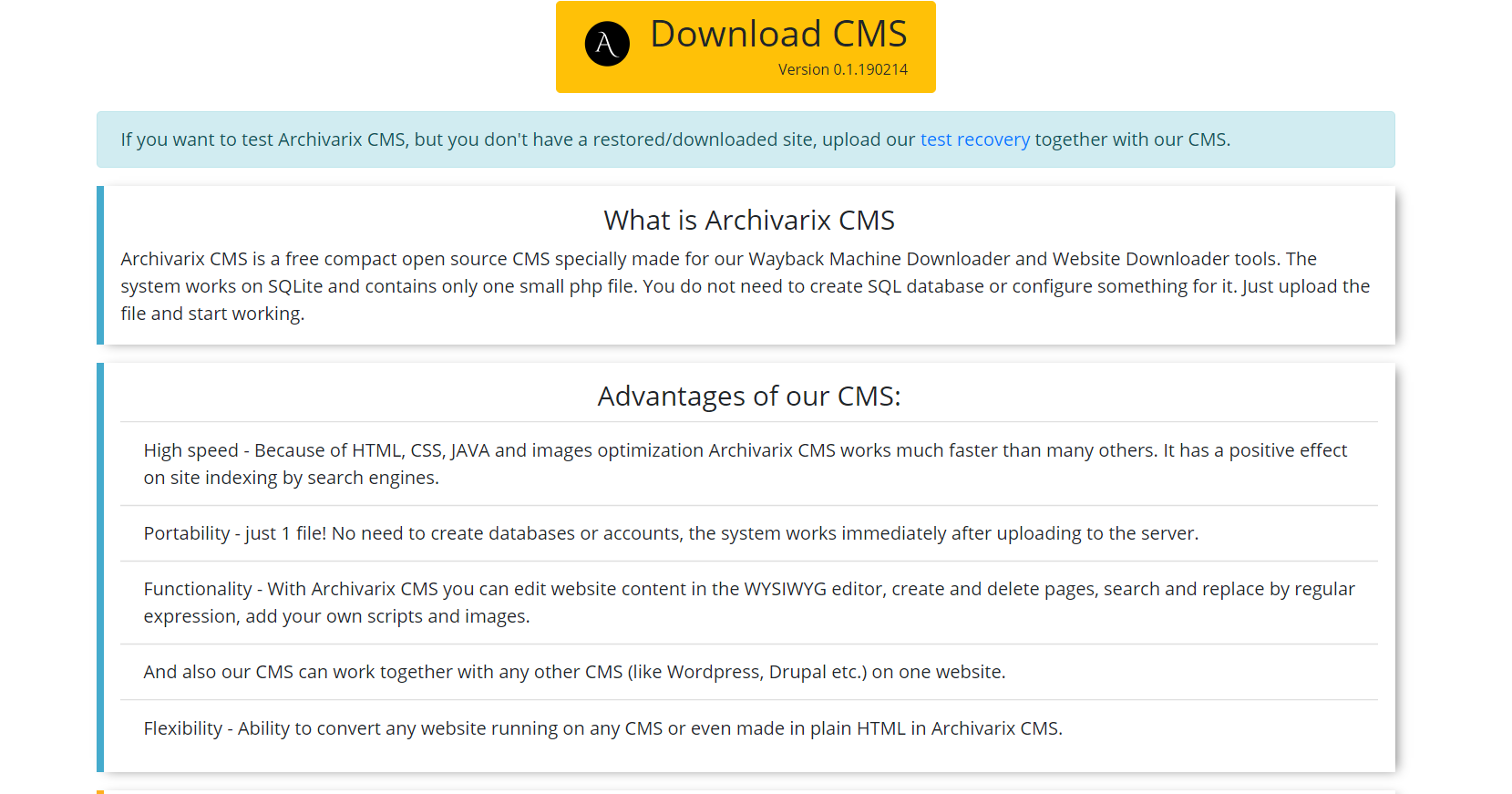
Questo è un CMS semplice e compatto progettato per la modifica di siti Web creati dal sistema Archivarix. Permette di cercare e sostituire il codice in tutto il sito Web usando espressioni regolari, modificando il contenuto nell'editor WYSIWYG, aggiungendo nuove pagine e file. Archivarix CMS può essere utilizzato insieme a qualsiasi altro CMS su un sito Web.
Parliamo ora di altri moduli utilizzati per il download di siti Web esistenti. A differenza del modulo per il download di siti Web dall'archivio Web, è impossibile prevedere quanti e quali file è necessario scaricare, quindi i server del modulo funzionano in un modo completamente diverso. Server spider segue semplicemente tutti i collegamenti presenti su un sito Web che si intende scaricare. Affinché lo script non rientri nel ciclo infinito di download di qualsiasi pagina generata automaticamente, la profondità massima del collegamento è limitata a dieci clic. E il numero massimo di file che è possibile scaricare dal sito Web deve essere specificato in anticipo.
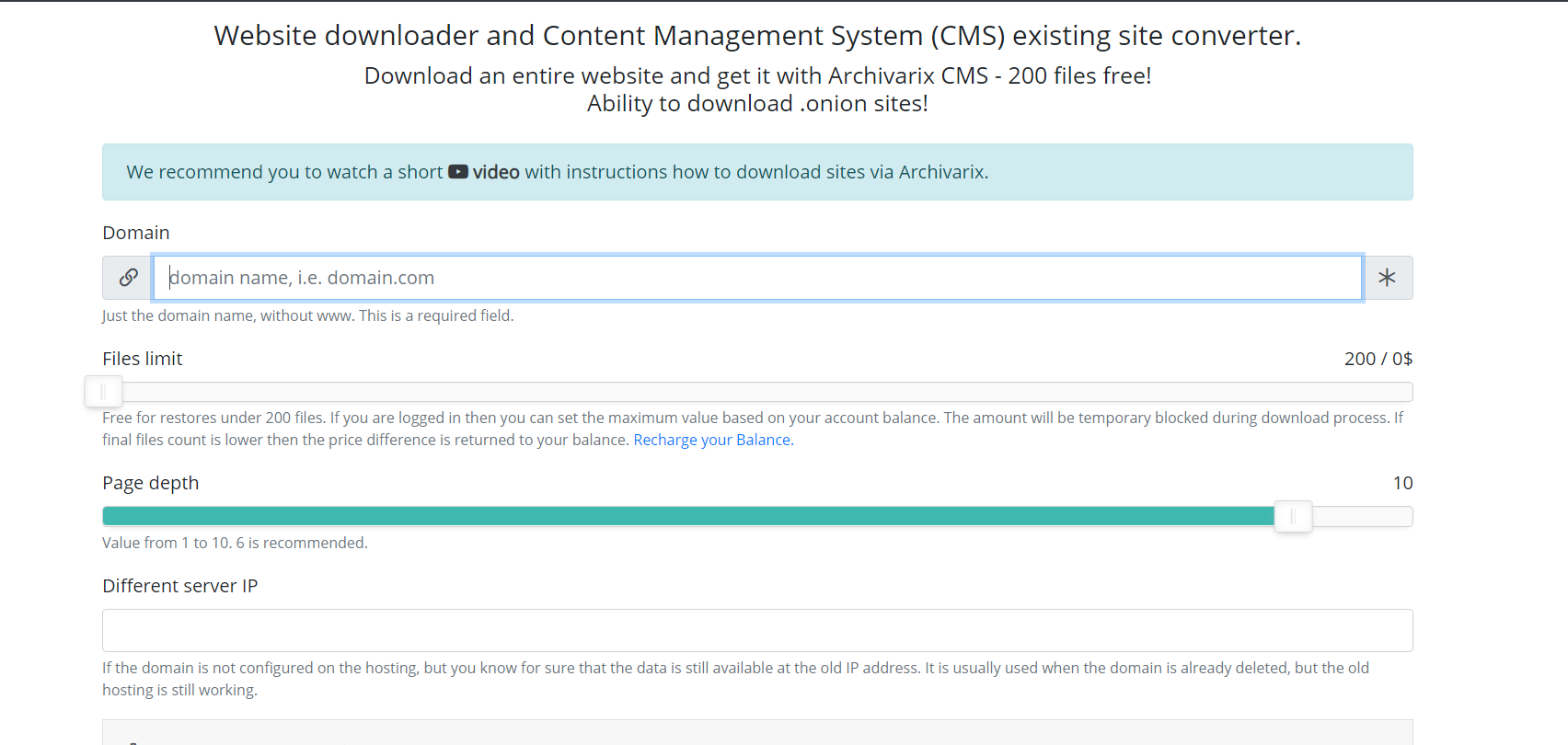
Per il download più completo del contenuto di cui hai bisogno, ci sono diverse funzionalità che sono state inventate in questo modulo. Puoi selezionare un altro spider del servizio User-Agent, ad esempio Chrome Desktop o Googlebot. Referrer per il cloaking bypass: se devi scaricare esattamente ciò che l'utente vede quando ha effettuato l'accesso dalla ricerca, puoi installare un referrer di Google, Yandex o di altri siti web. Al fine di proteggere dal divieto tramite IP, è possibile scegliere di scaricare il sito Web utilizzando la rete Tor, mentre l'IP del servizio spider cambia casualmente all'interno di questa rete. Altri parametri, come l'ottimizzazione delle immagini, la rimozione degli annunci e l'analisi sono simili ai parametri del modulo di download dal Web Archive.
Al termine del download, il contenuto viene trasferito al modulo di elaborazione. I suoi principi di funzionamento sono completamente simili all'operazione con il sito Web scaricato dall'Archivio Web sopra descritto.
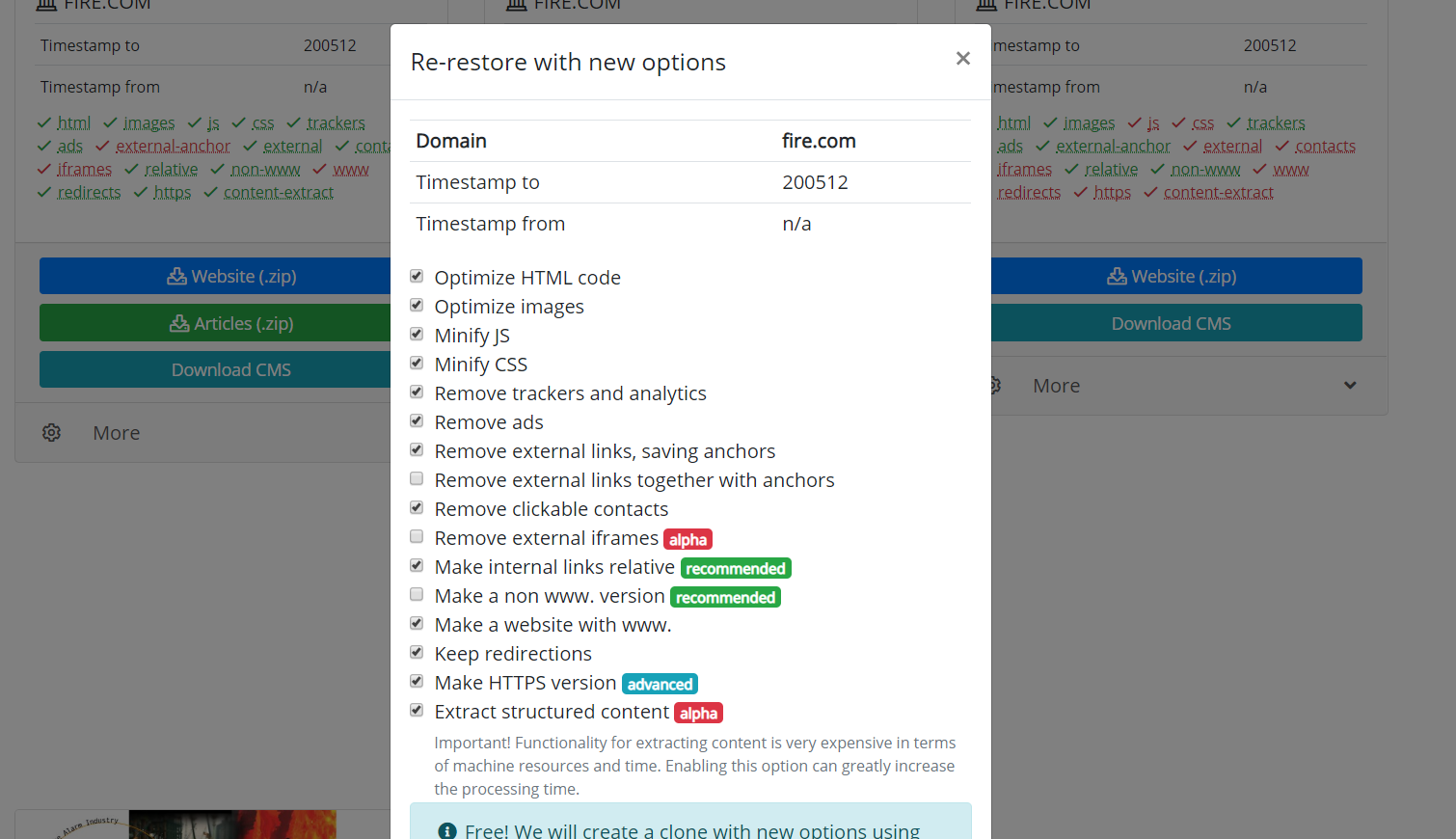
Vale anche la pena menzionare la possibilità di clonare siti Web ripristinati o scaricati. A volte capita che durante il recupero, si siano scelti altri parametri rispetto a quelli che si sono rivelati necessari alla fine. Ad esempio, la rimozione di collegamenti esterni non era necessaria e alcuni collegamenti esterni necessari, quindi non è necessario ricominciare a scaricare. Hai solo bisogno di impostare nuovi parametri nella pagina di recupero e iniziare a ricreare il sito.
L'uso del materiale dell'articolo è consentito solo se la fonte è pubblicata: https://archivarix.com/it/blog/how-does-it-works/

Il sistema Archivarix è progettato per scaricare e ripristinare siti non più accessibili da Web Archive e quelli attualmente online. Questa è la differenza principale rispetto al resto dei "downloader…
Utilizzando l'opzione "Estrai contenuto strutturato" puoi facilmente creare un blog Wordpress sia dal sito trovato nell'Archivio Web che da qualsiasi altro sito. Per fare ciò, trova prima il sito di o…
Per semplificare la modifica dei siti Web ripristinati nel nostro sistema, abbiamo sviluppato un semplice file CMS Flat File costituito da un solo piccolo file php. Nonostante le sue dimensioni, quest…
Questo articolo descrive le espressioni regolari utilizzate per cercare e sostituire i contenuti nei siti Web ripristinati utilizzando il sistema Archivarix. Non sono univoci per questo sistema. Se co…