Как восстанавливать сайты из Веб Архива - archive.org. Часть 1
Интерфейс веб-архива: инструкция к инструментам Summary, Explore и Site map.
В этой статье мы расскажем о самом web.archive и о том, как он работает.
Для справки: веб-архив был создан Брюстером Кейлом в 1996 году примерно в то же время, когда он основал компанию Alexa Internet, занимающуюся сбором статистики о посещаемости веб-сайтов. В октябре того же года организация начала архивировать и хранить копии веб-страниц. Но в текущем виде ― WAYBACKMACHINE ― в котором мы можем его использовать, он запустился только в 2001 году, хотя данные сохраняются с 1996 года. Преимущество веб-архива для любого сайта в том, что он сохраняет не только html-код страниц, но и другие типы файлов: doc, zip, avi, jpg, pdf, css. Комплекс html-кодов всех элементов страниц позволяет восстановить сайт в его первоначальном виде (на конкретную дату индексирования, когда паук веб-архива посещал страницы сайта).
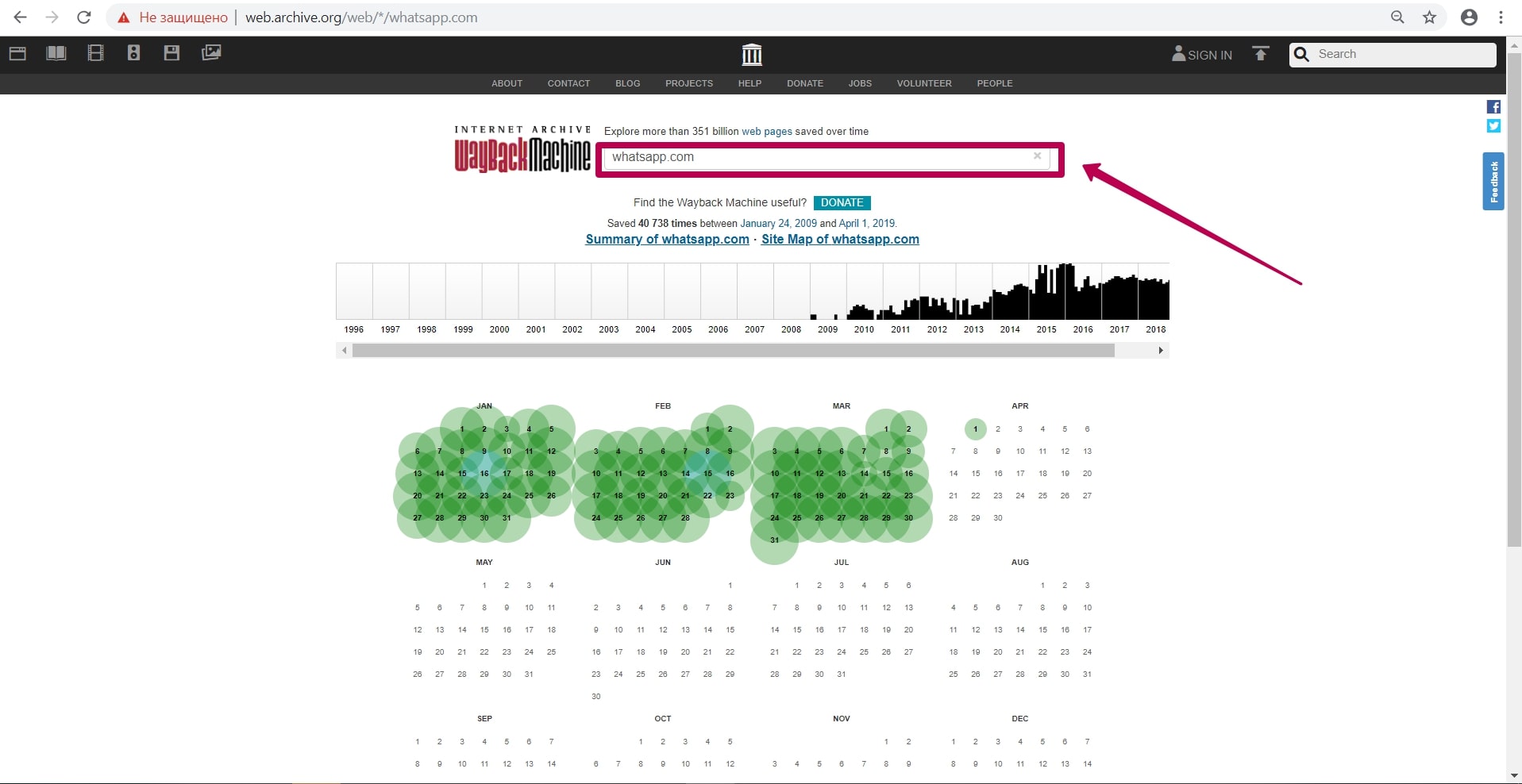
Итак, архив находится по адресу http://web.archive.org/. Рассмотрим возможности веб-архива на примере крупного всем известного сайта, как WhatsApp.
На главной странице в поле поиска вводим домен интересующего нас сайта, в данном случае ― whatsapp.com
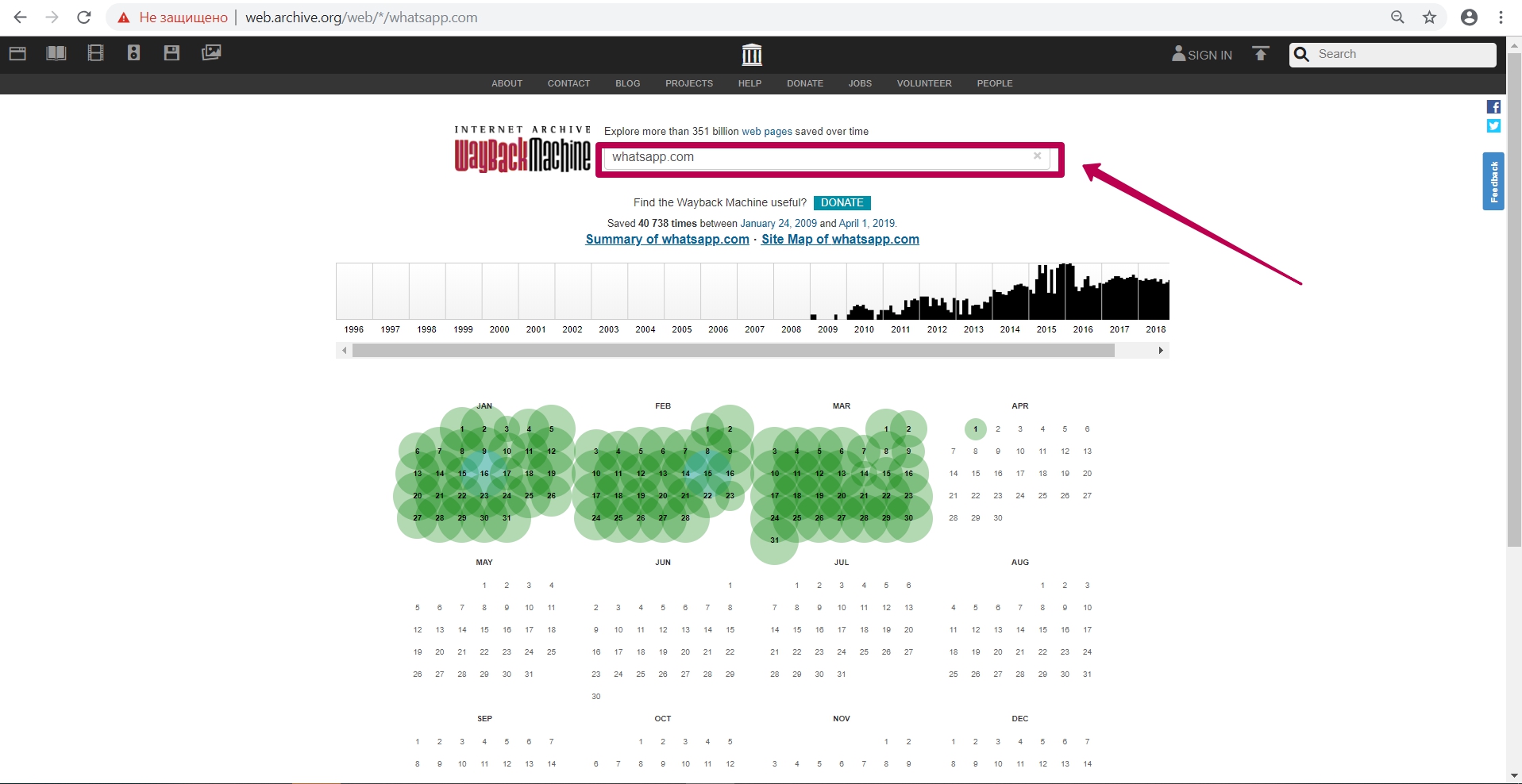
После ввода ссылки на сайт мы видим календарь сохранения кода html страницы. На этом календаре на датах сохранения мы видим пометки различными цветами:
Синий ― сервер отдавал валидный правильный код 200 (отсутствие ошибок от сервера);
Красный (желтый, оранжевый, в зависимости от браузера и операционной системы ПК) ― ошибка 404 или 403, то, что не интересно при восстановлении;
Зеленый ― redirect-страницы (301 и 302).
Цвета в календаре не дают 100% гарантию соответствия: на синей дате также может быть redirect (не на уровне заголовка, а к примеру, в html-коде самой страницы ― в мета-тегах refresh (тегах обновления экрана) или в JavaScript).
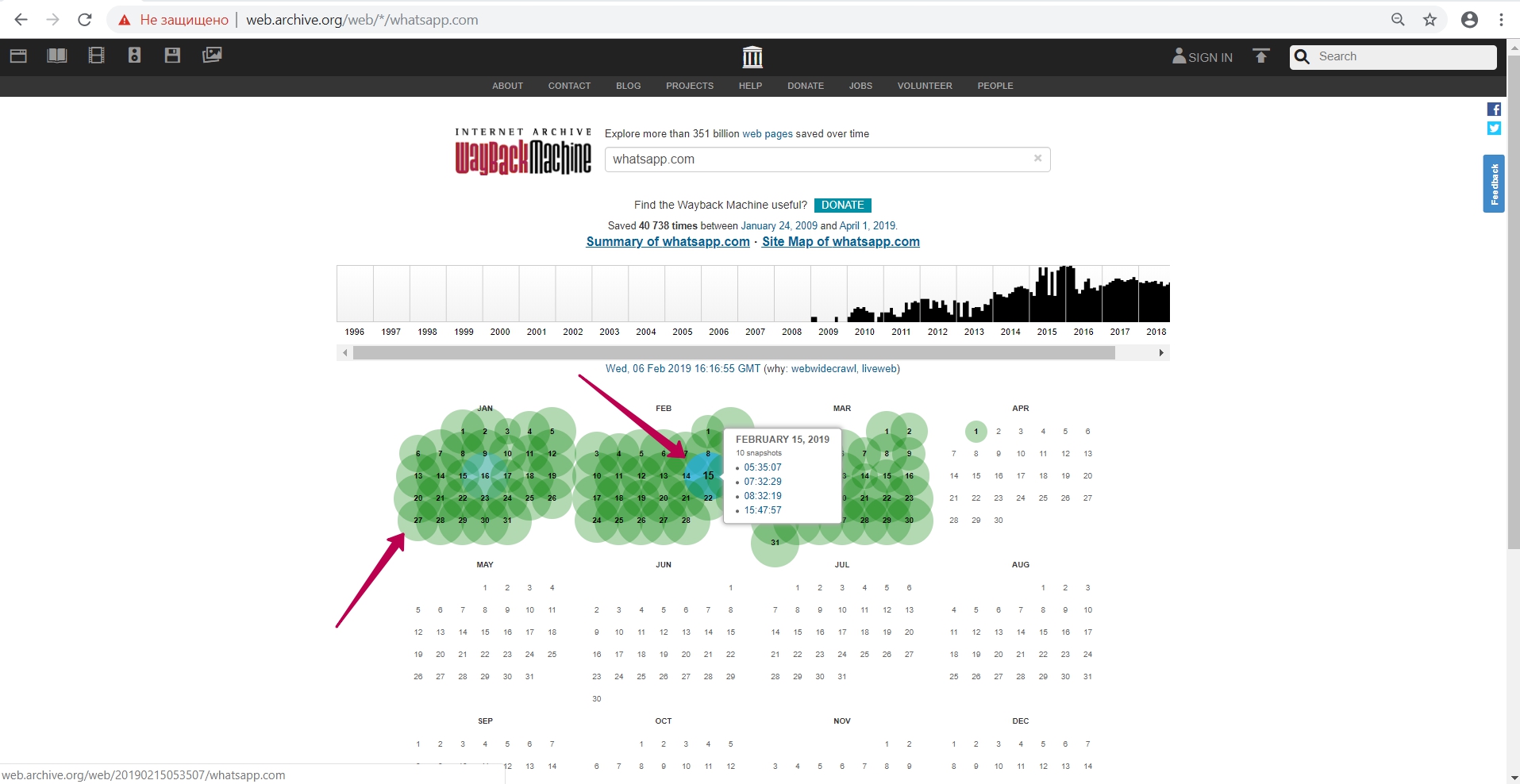
Переходим на 2009 год, в самое начало индексирования (сохранения) сайта в веб-архиве.
Видим версию от 24 января и открываем ее в новой вкладке (в случае ошибок при работе, лучше открыть инструмент веб-архива в режиме инкогнито или в другом браузере).
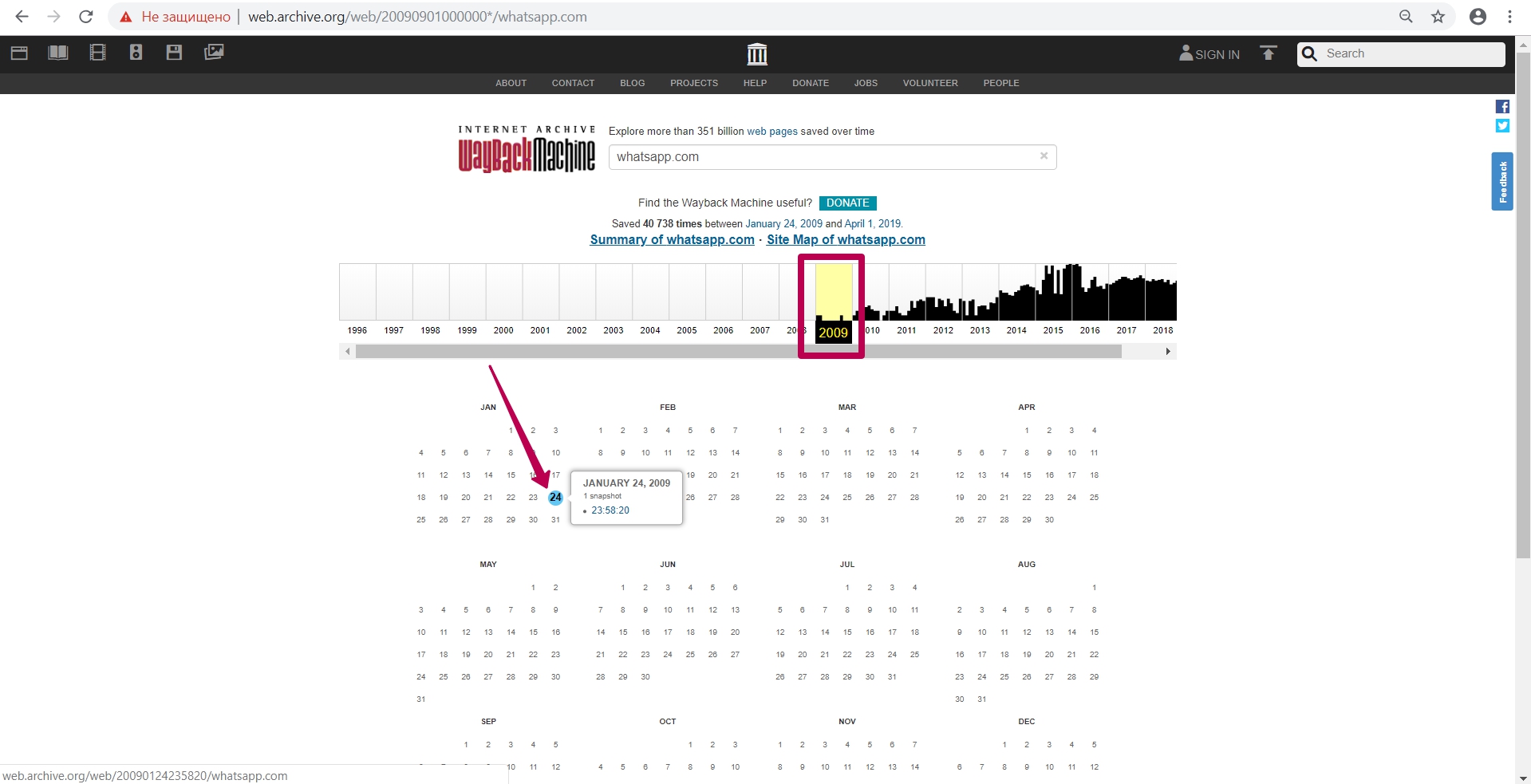
Итак, мы видим версию страницы WhatsApp за 2009 год. В url страницы мы видим цифры ― timestamp (временную метку) ― т.е. год, месяц, день, час, минута, секунда, когда было сохранение именно этого url. Формат timestamp (YYYYMMDDhhmmss).
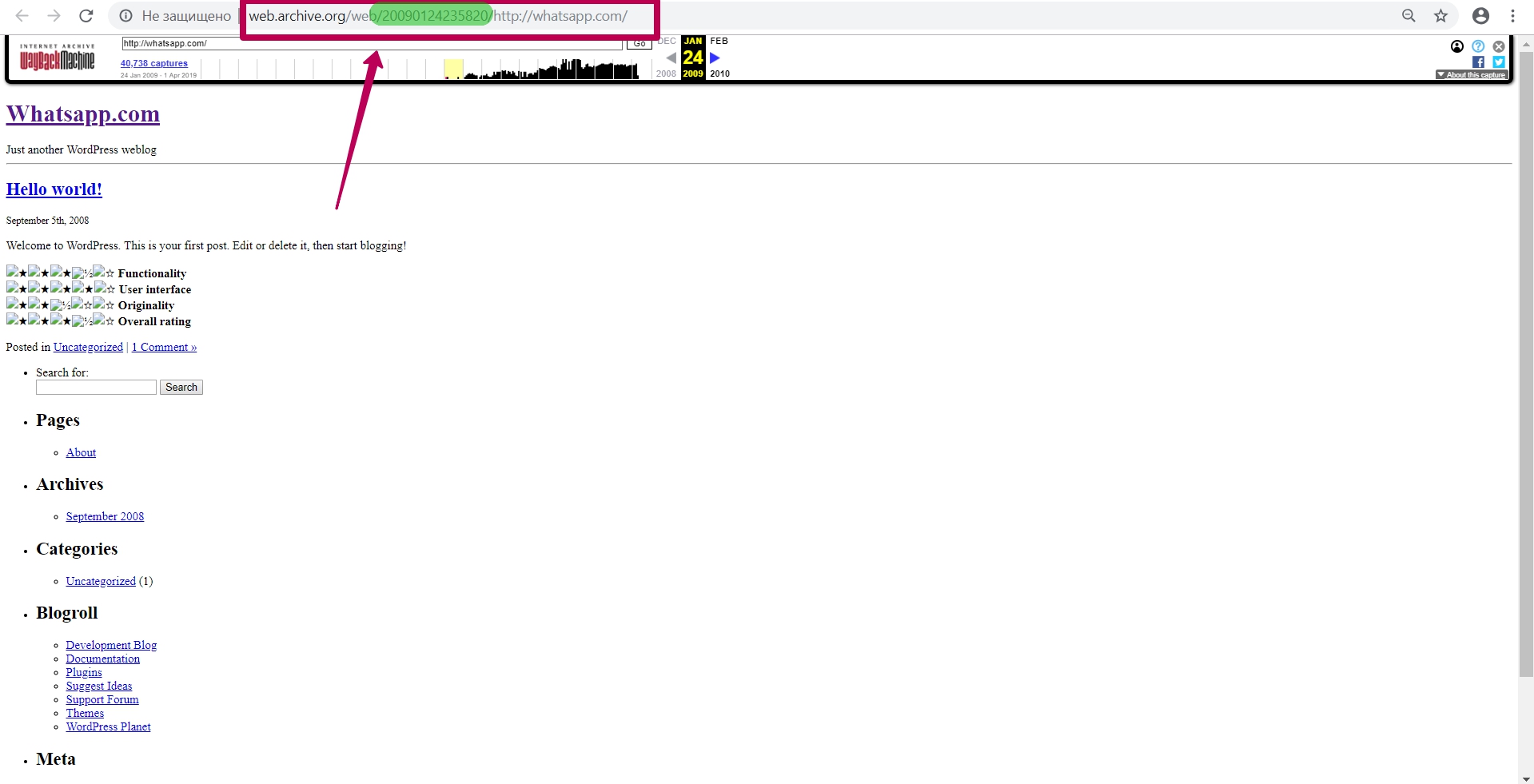
Timestamp ― это не время сохранения копии сайта и не время сохранения страницы, это именно время сохранения конкретного файла. Это важно знать для восстановления контента из веб архива. Все элементы сайта - картинки, стили, скрипты, html и так далее имеют свой timestamp, то есть дату архивации.
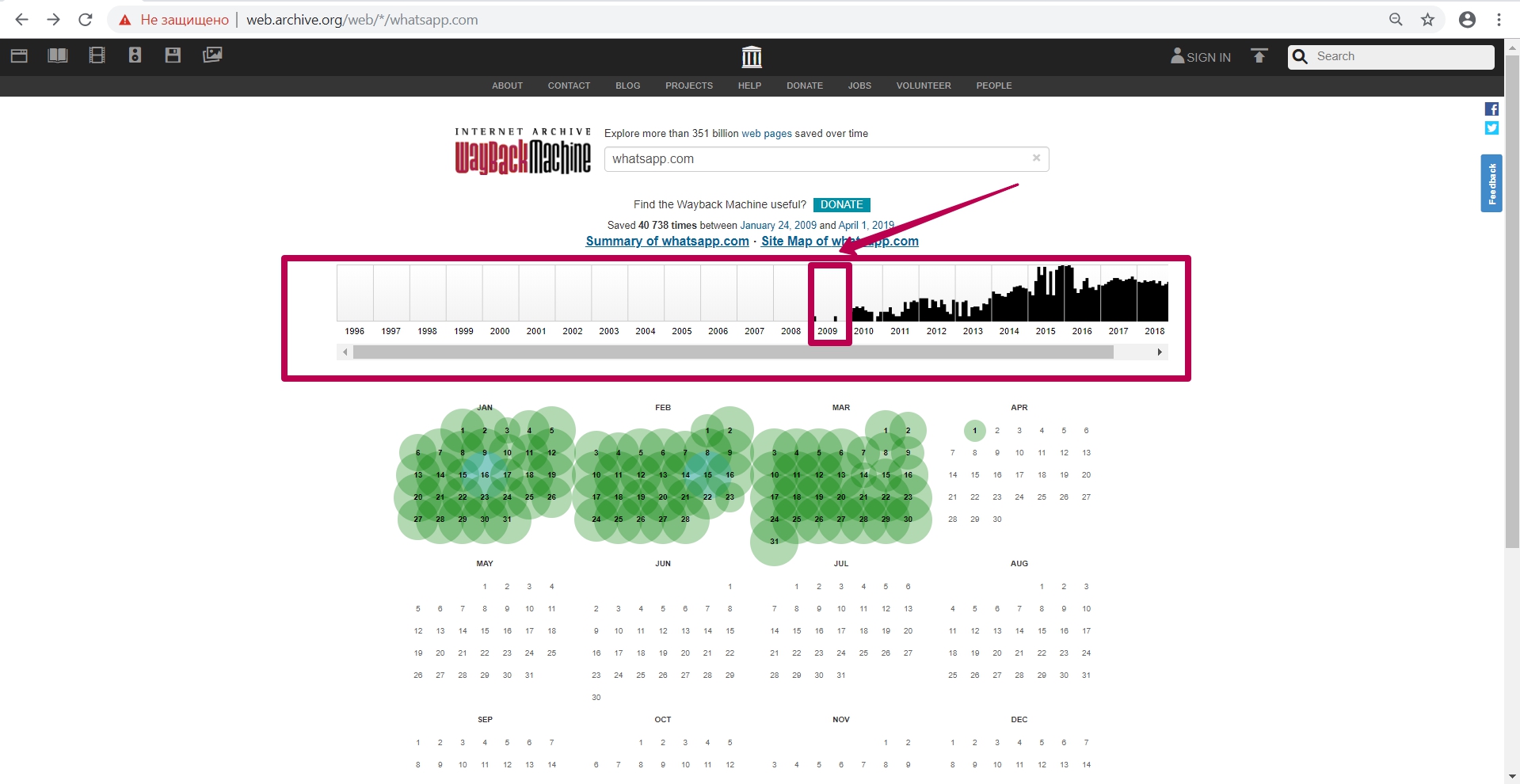
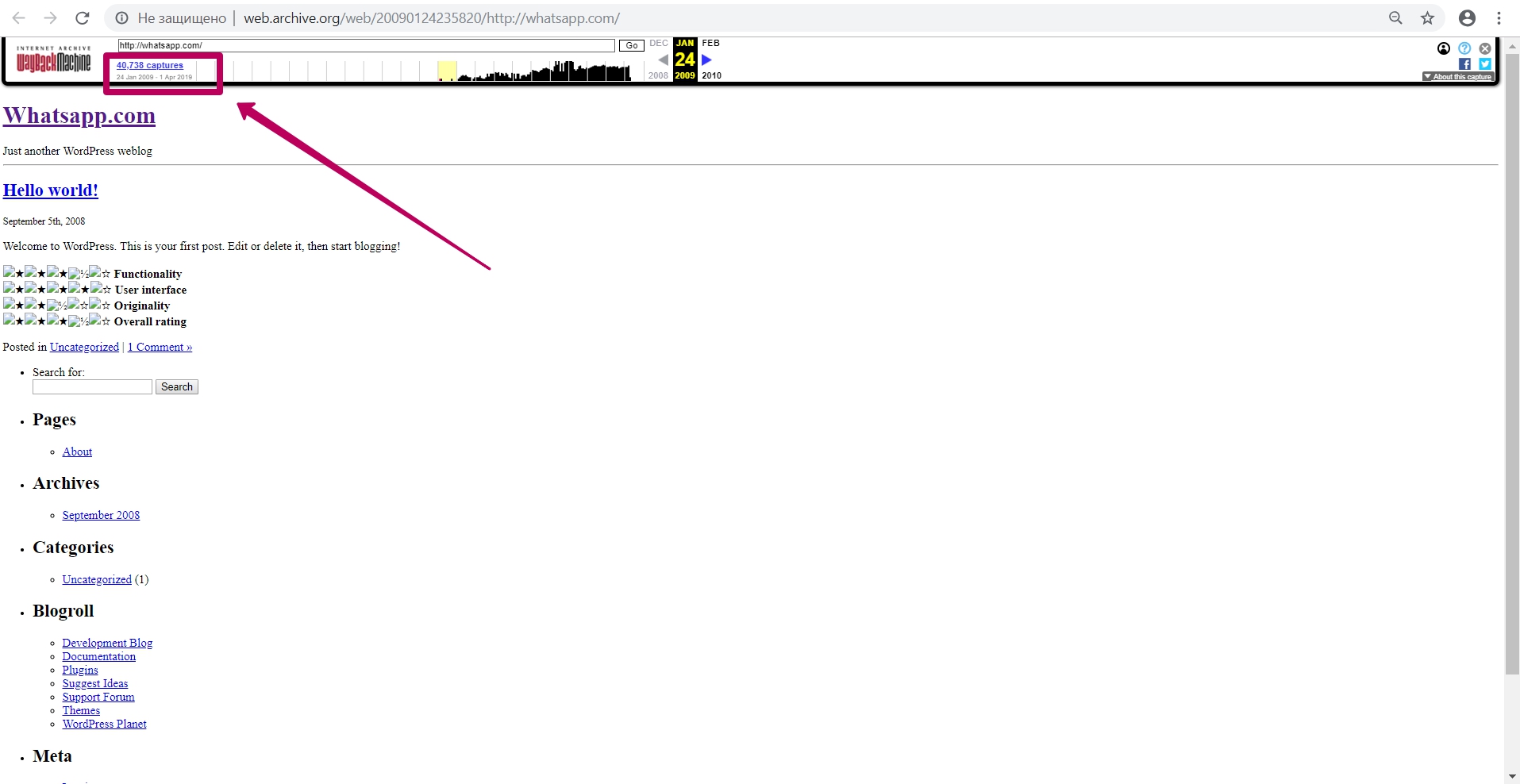
Для возвращения со страницы сайта обратно на календарь, нажимаем на ссылку с числом captures (захватов страницы).
Инструмент Summary
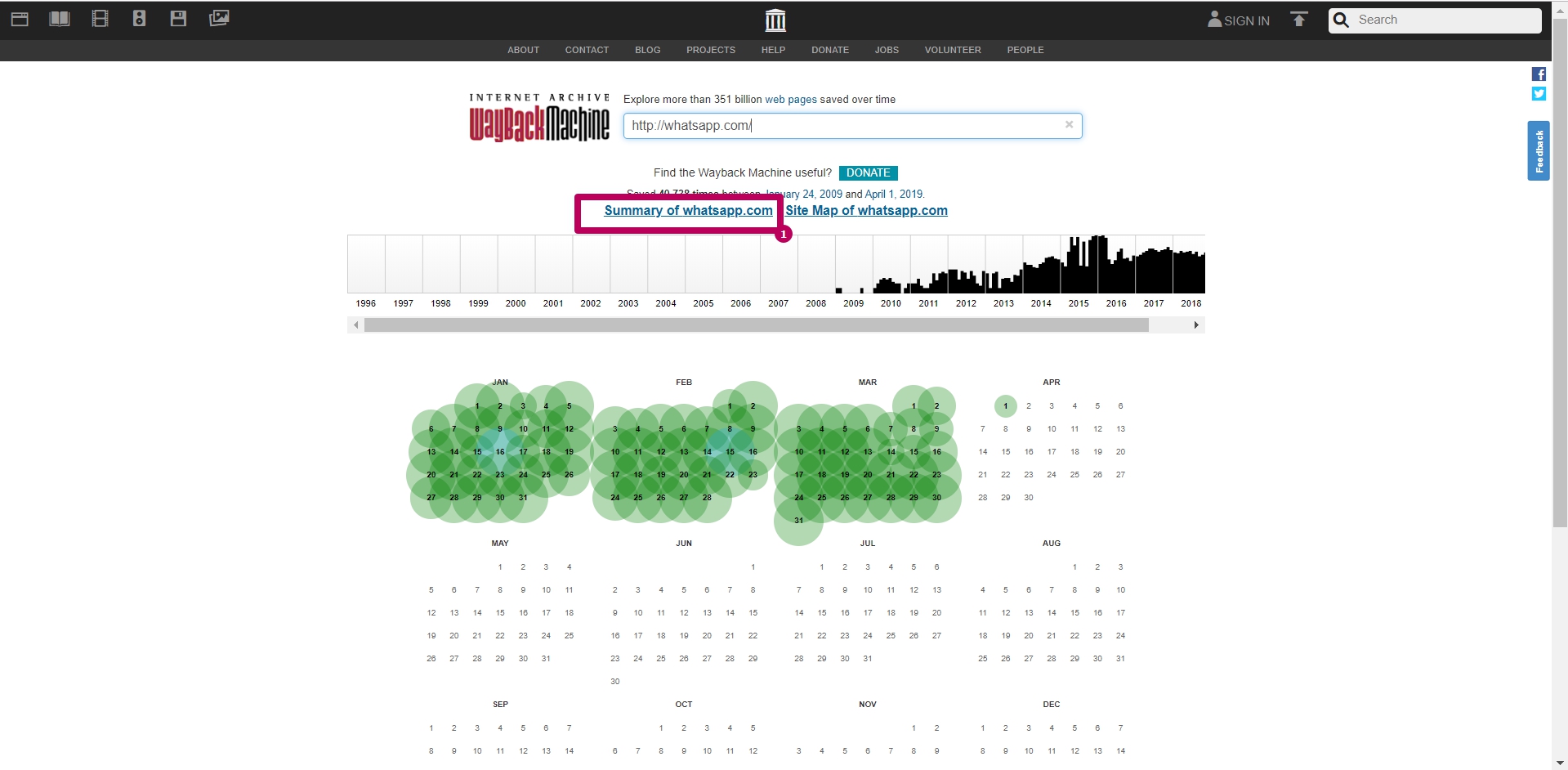
На главной странице веб-архива выбираем инструмент Summary. Это графики и диаграммы сохранения сайта. Все графики и таблички можно посмотреть по годам.
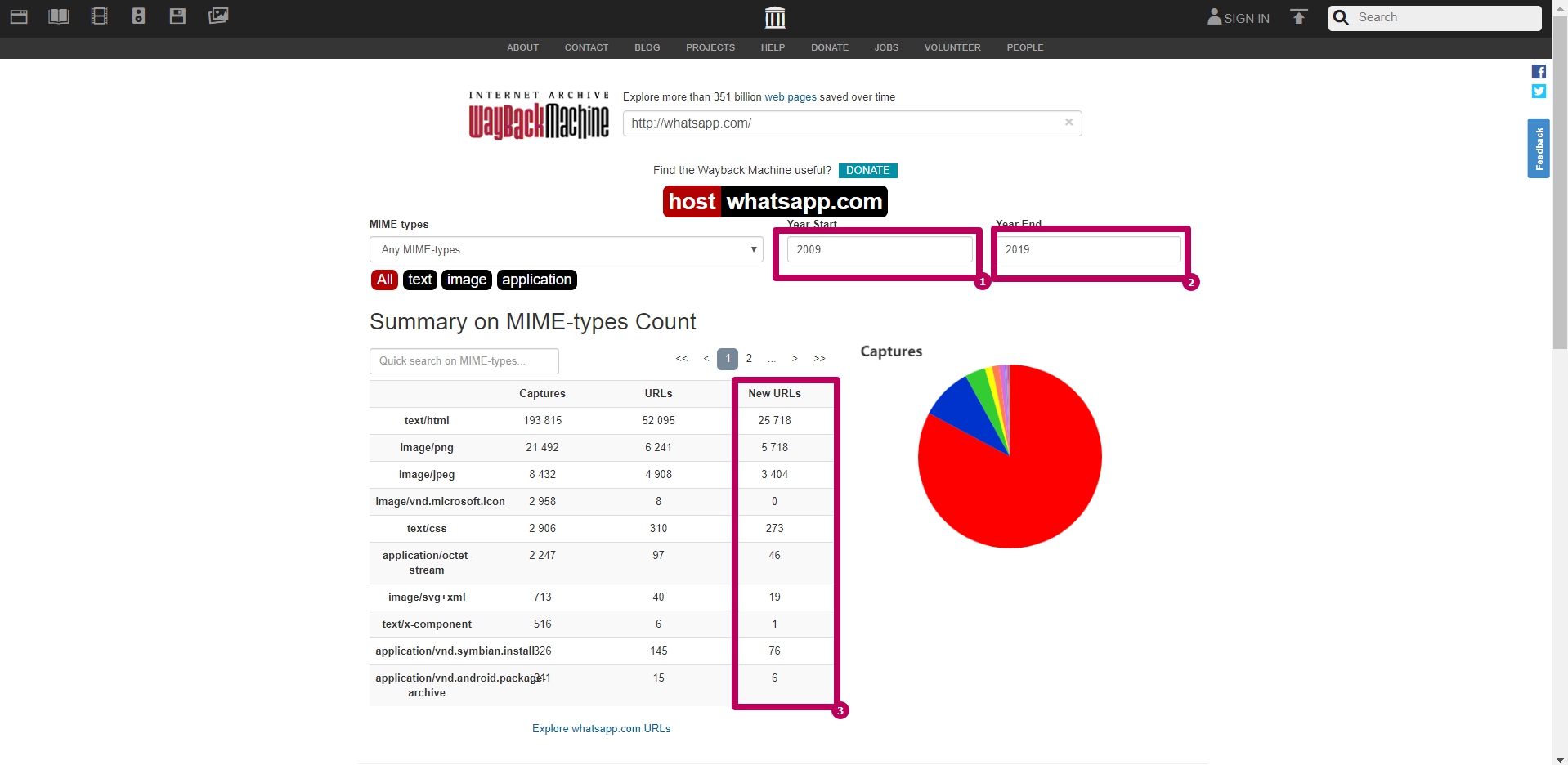
Наиболее полезная информация на странице ― сумма столбика New URLs. Эта сумма показывает нам количество уникальных файлов содержащееся в веб-архиве.
Цифра будет установлена приблизительна, по той причине, что сам веб-архив мог заиндексировать страницу с www или без. Т.е. одна и та же страница и ее элементы могут располагаться по разным адресам.
Инструмент Explore
![]()
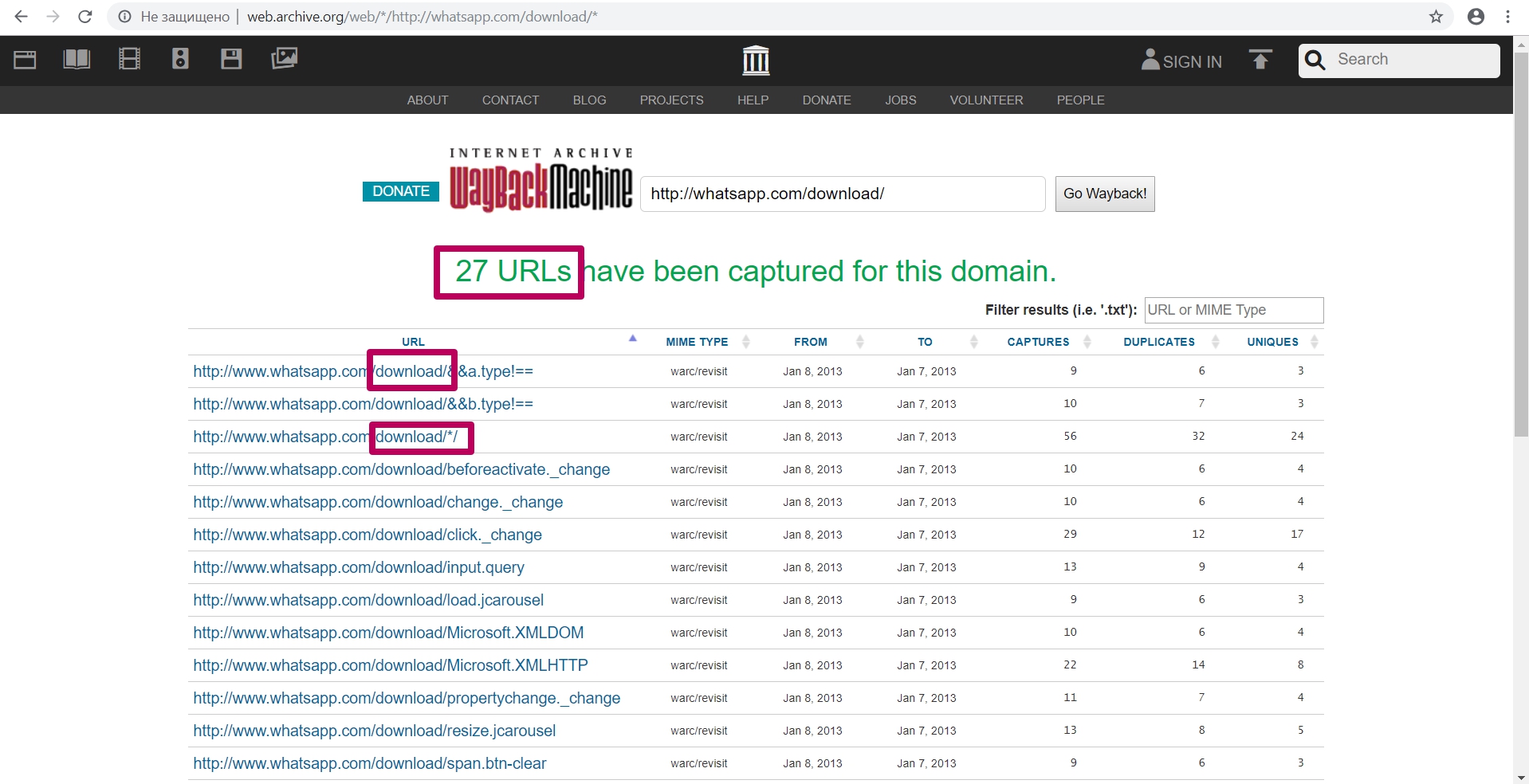
Он загружает в таблицу все url, что ранее были заиндексированы пауком веб-архива.
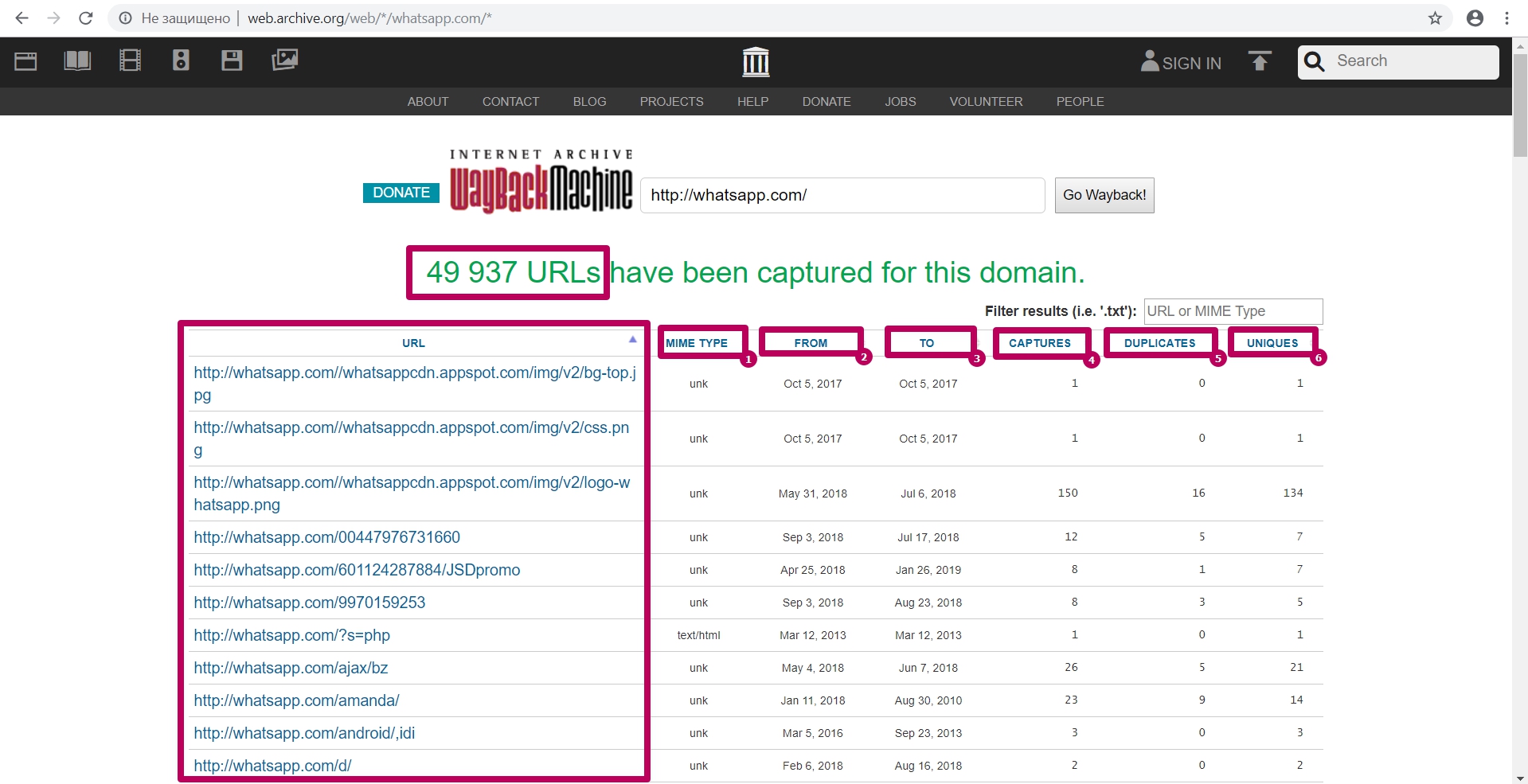
Тут можно увидеть:
- MIME Тип элемента;
- Первичную дату индексирования элемента;
- Последнюю дату сохранения элемента;
- Общее число захватов (сохранений) элемента;
- Число дубликатов;
- Число сохранений уникального контента по url.
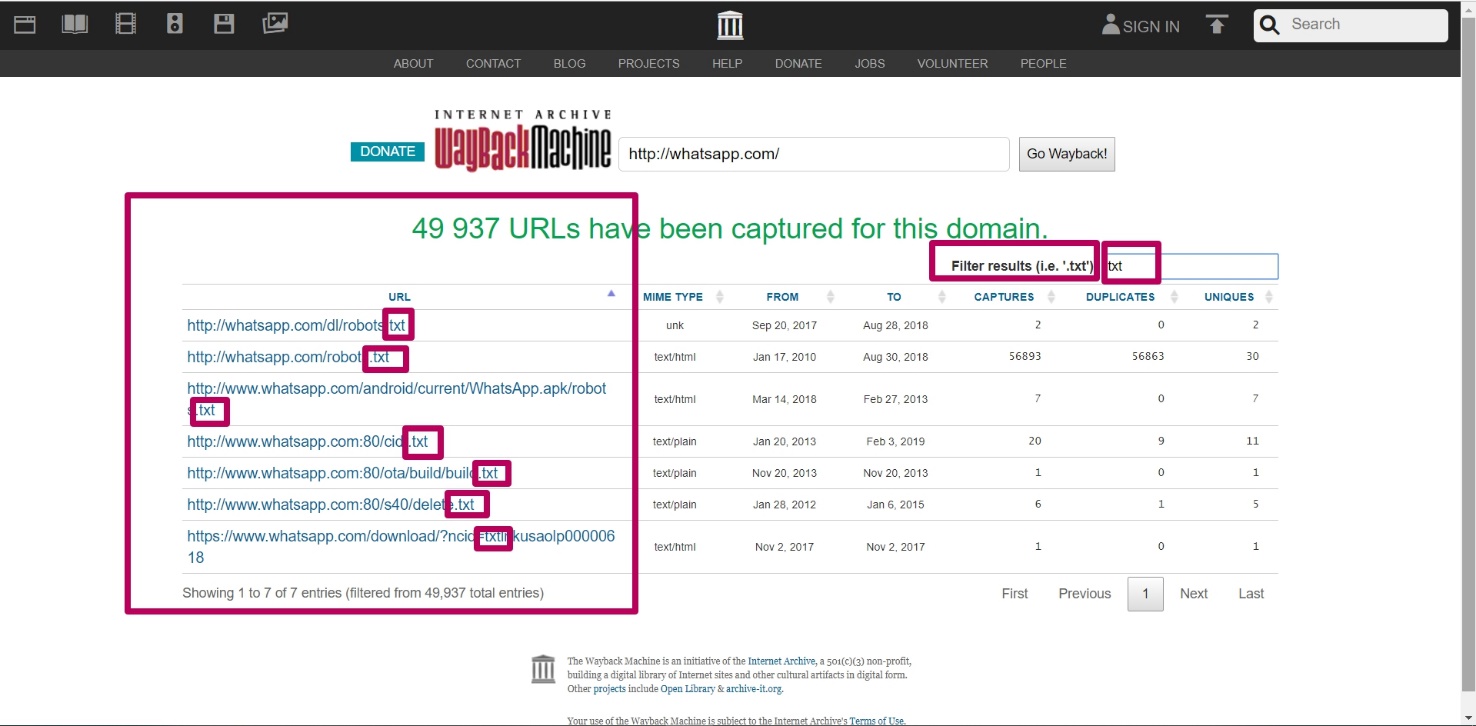
В поле фильтра возможно задать любую часть искомого элемента: для поиска содержимого сайта, которое трудно обнаружить в большом количестве ссылок.
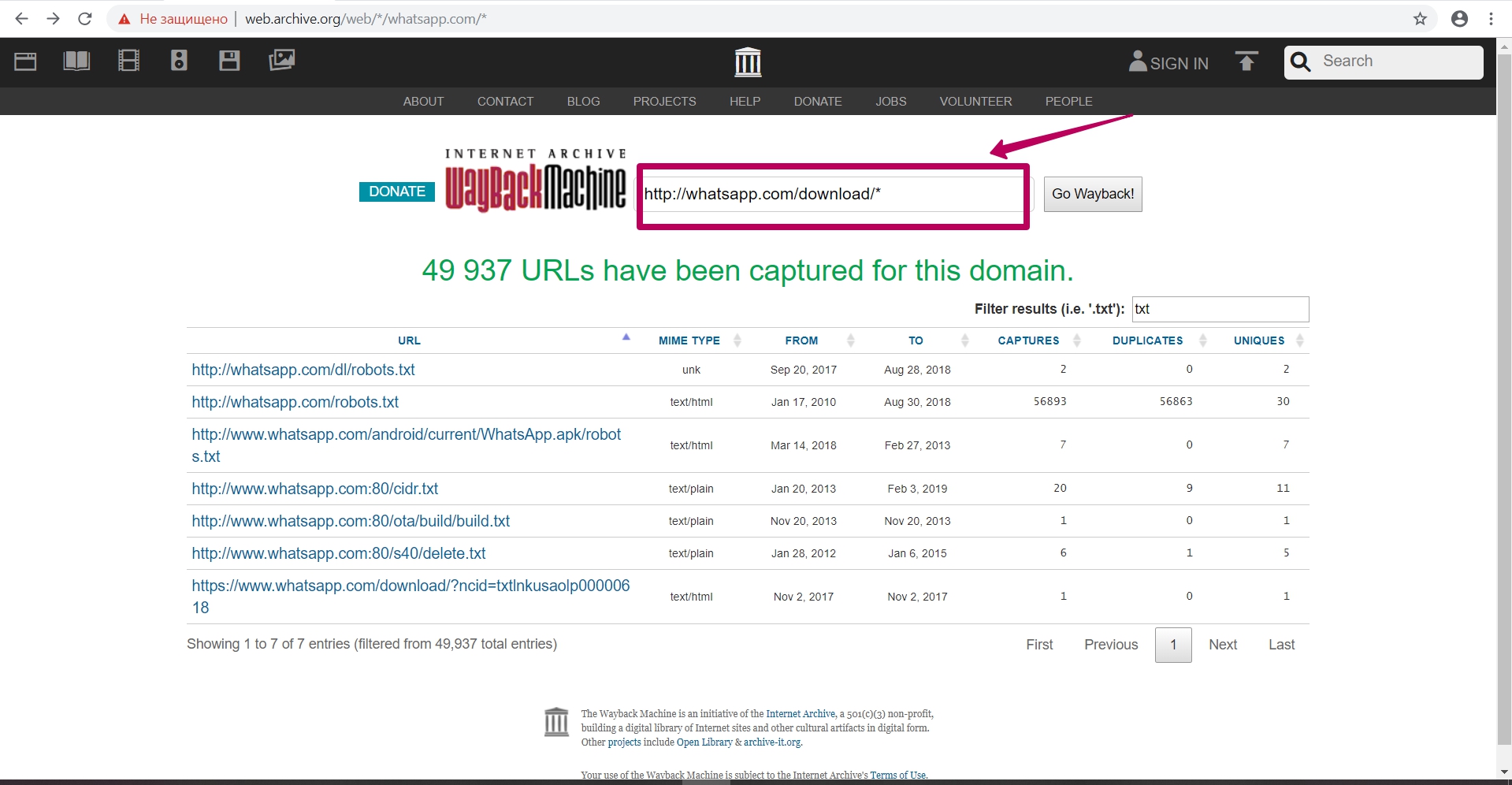
Также возможно в поиске ввести часть пути, к примеру, путь в папку (обязательно со звездочкой), можно увидеть все url по заданному пути (все файлы со страницы или с папки) для анализа индексации этого контента.
Инструмент Site Map
На главной странице сайта нажимаем соответствующую ссылку Site Map.
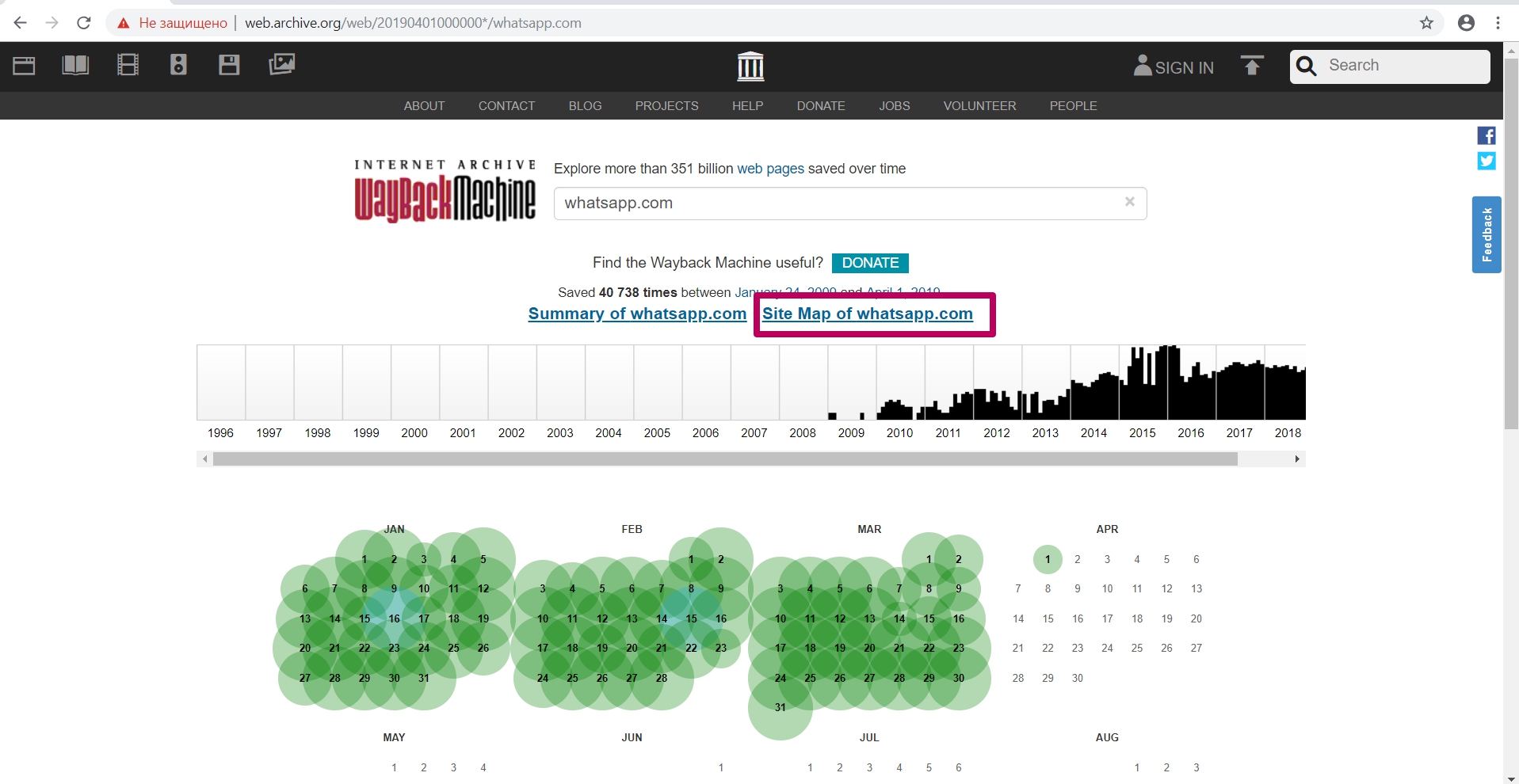
Это кольцевая диаграмма с разделением по годам для анализа элементов, которые сохранял веб-архив (какие страницы) в разрезе от главного url к url вторго и n-ного уровня. Этот инструмент позволяет определить, в какой год веб-архив перестал сохранять новый контент на сайт или копии определенных url (появление любого кода, кроме кода 200).
В центре главная страница, а далее по структуре пути на втором-третьем этапе видим внутренние страницы сайта. Здесь нет других видов файлов, только сохраненные url. Т.е. мы можем понять, где архив смог проиндексировать или не проиндексировать страницы.
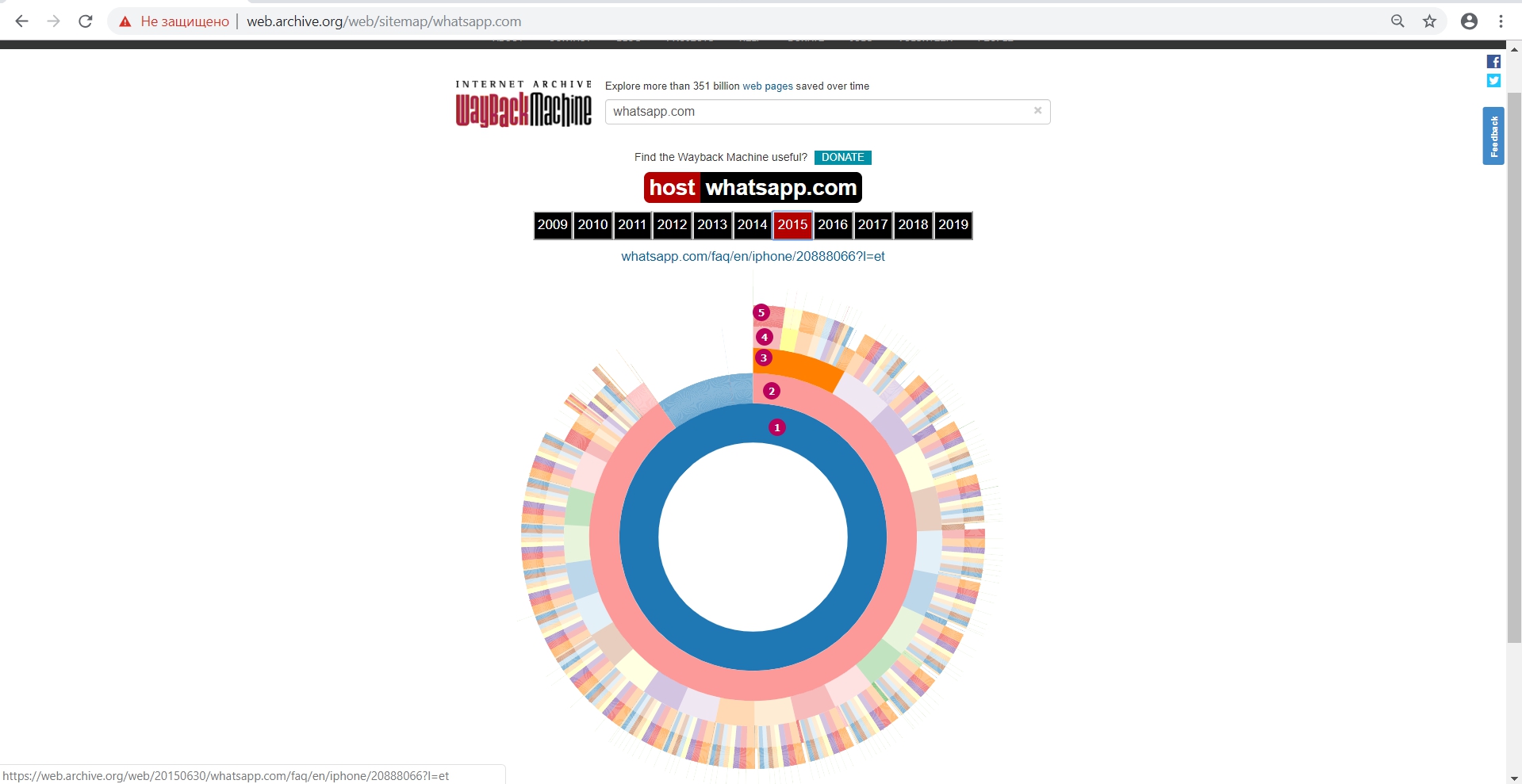
На схеме показаны:
1. Главная страница
2 - 5. Уровни вложенности страниц сайта
Также с помощью данного инструмента мы можем увидеть внутренние страницы по структуре и открыть их отдельно в новой вкладке.
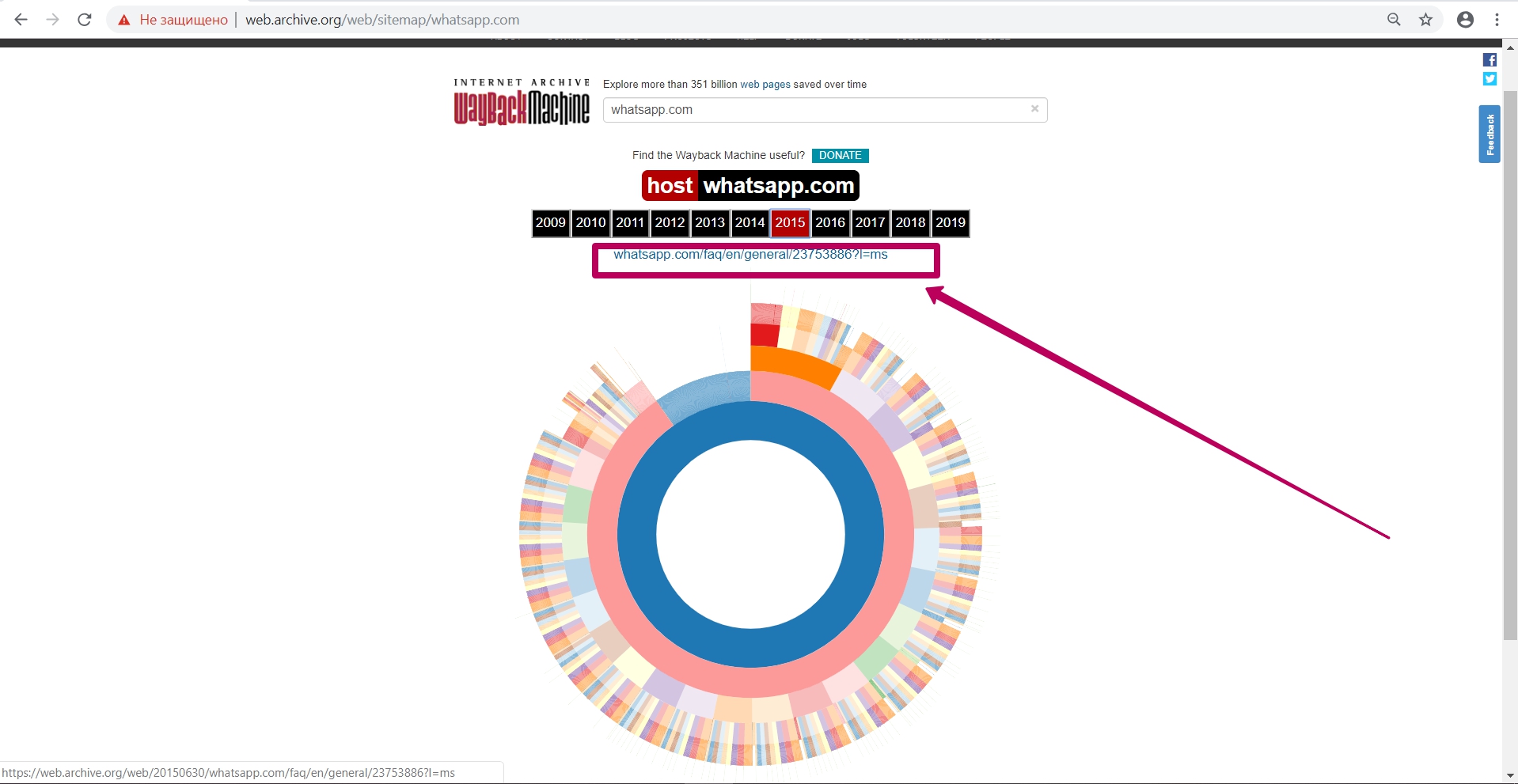
Таким образом, отобрав ссылки на страницы и элементы с необходимой датой сохранения в веб-архиве и построив требуемую нам структуру, мы можем приступать к следующему этапу ― подготовке домена к восстановлению. Но об этом мы расскажем в следующем гайде.
Этот видео гайд есть на Youtube:
Как восстанавливать сайты из Веб Архива - archive.org. Часть 2
Как восстанавливать сайты из Веб Архива - archive.org. Часть 3
Использование материалов статьи разрешается только при условии размещения ссылки на источник: https://archivarix.com/ru/blog/1-how-does-it-works-archiveorg/

В этой статье мы расскажем о самом web.archive и о том, как он работает. Интерфейс веб-архива: инструкция к инструментам Summary, Explore и Site map. В этой статье мы расскажем о самом web.archive и…
Подготовка домена к восстановлению. Создание robots.txt
В прошлой статье мы рассмотрели работу сервиса archive.org, а в этой статье речь пойдет об очень важном этапе восстановления сайта из веб-архи…
Выбор ограничения ДО при восстановлении сайтов из веб-архива. Когда домен заканчивается, на сайте может появится заглушка домен-провайдера или хостера. Перейдя на такую страницу, веб-архив будет ее со…