Как восстанавливать сайты из Веб Архива - archive.org. Часть 3
Выбор огранияения ДО при восстановлении сайтов из веб-архива
В прошлый раз мы рассказали вам, как подготовить домен к восстановлению и о том, как открыть индексацию через robots.txt. Сегодня вы узнаете, как выбрать дату полностью работоспособной версии старого сайта из веб-архива.
Когда домен заканчивается, на сайте может появится заглушка домен-провайдера или хостера. Перейдя на такую страницу, веб-архив будет ее сохранять, как полностью рабочую, отображая соответственную информацию в календаре. Если по такой дате из календаря восстановить сайт, то, вместо нормальной страницы мы получим ту самую заглушку. Как этого избежать и узнать дату работоспособности всех страниц сайта, по которой его можно восстановить?
Инструкция по выбору даты на примере домена Trimastera.ru
На главной странице вводим домен и открываем календарь веб-архива.
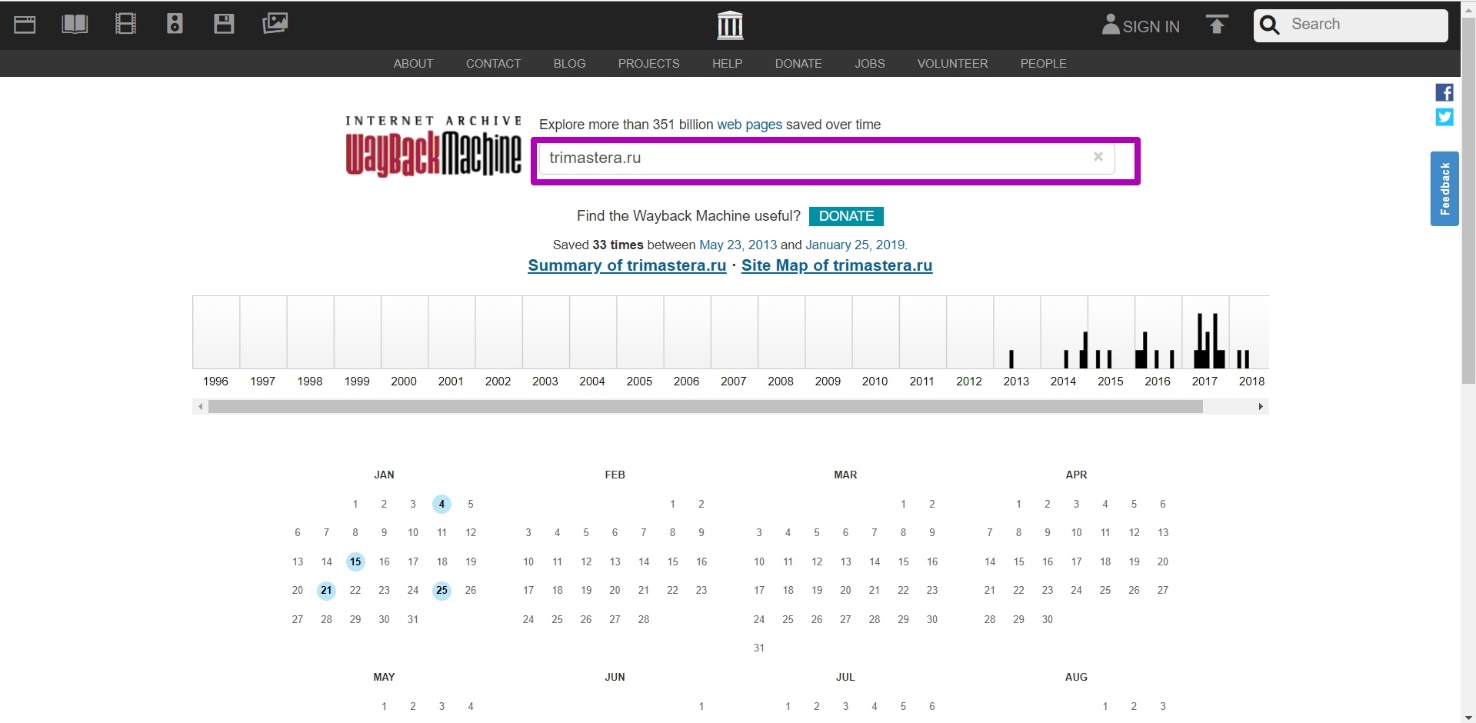
Ищем последнюю рабочую версию, которая будет помечена синим цветом. Открываем, и смотрим как она выглядит, если это парковка регистратора доменов, смотреим дальше. Находим время, когда контент был архивирован.
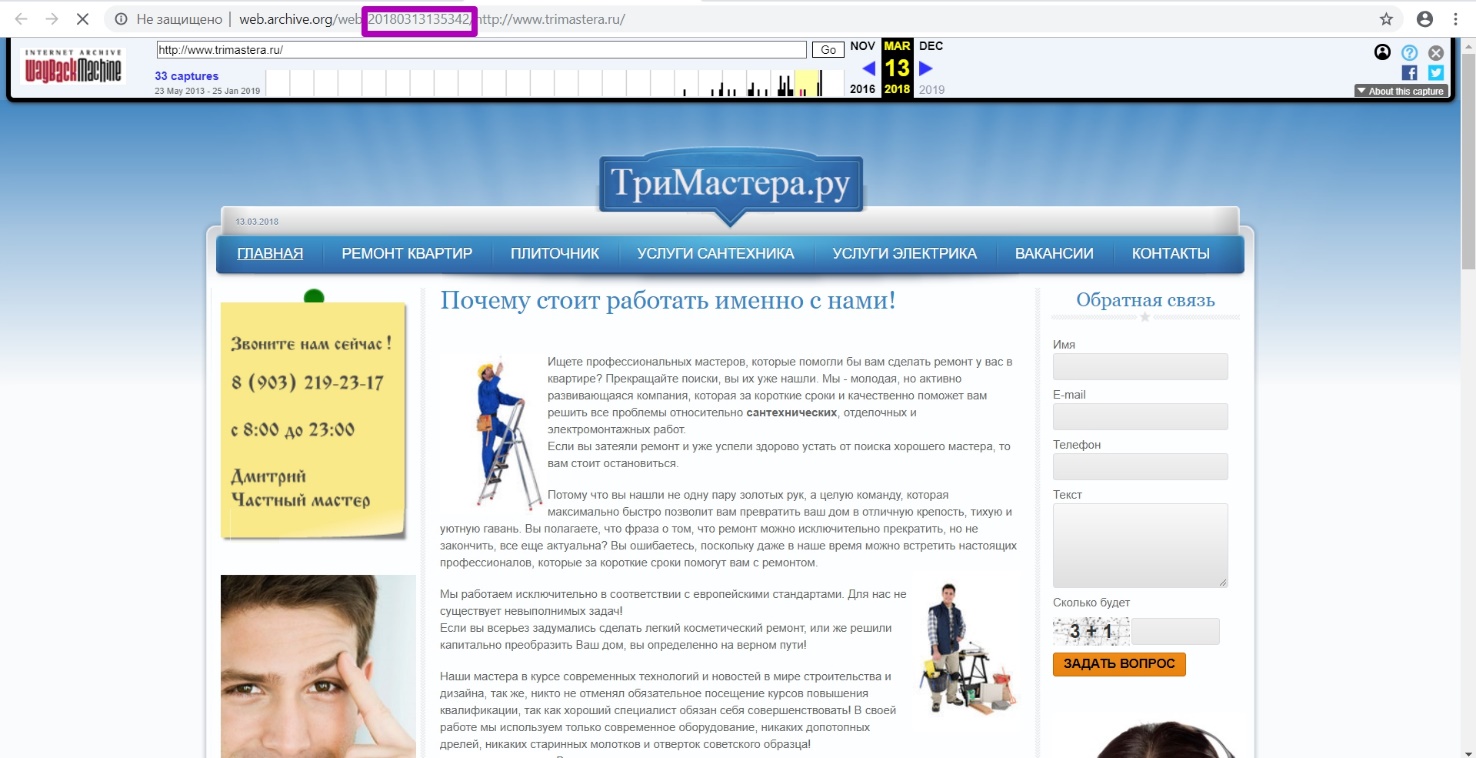
Внимание, timestamp который мы видим по ссылке ― это дата и время сохранения лишь html-кода этой страницы, но не CSS стилей на ней, ни картинок, ни скриптов. Все они имеют свои даты сохранения, порой значительно отличающиеся от даты html файла. Для того, чтобы веб-архив полностью сохранил страницу со всеми ее элементами, нужно время. Начиная с кода страницы, сохраняются все элементы с задержкой от нескольких секунд до нескольких дней, а иногда даже больше. Поэтому, если ввести именно этот timestamp как дату «to» домена, восстановится лишь часть страницы.
Переходим в инструмент DevTools для определения, откуда подгружаются все элементы сайта. Для этого нажимает одновременно клавиши ctrl+shift+i или F12 в вашем браузере. Видим инструмент анализа исходного кода.
Выбираем вкладку Network, убираем галочку persist logs. Нажимаем F5 или обновляем страницу.
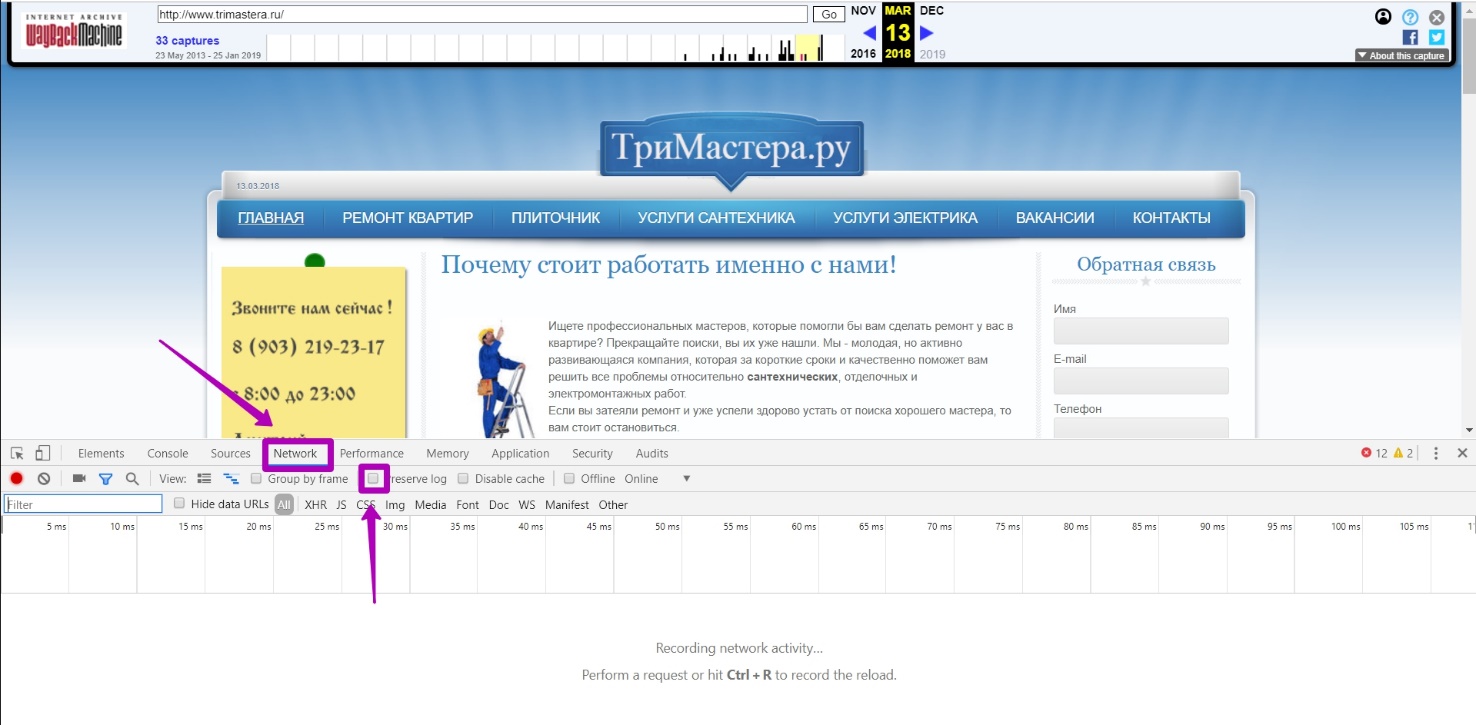
В поле фильтра вводим искомый домен Trimastera.ru. Для общего понимания, фильтр даже при частичном вводе имени домена отобразит информацию, и все, что будет прописано через пробел, определяется инструментом, как дополнительный фильтр к поиску.
Т.е. одновременно введя имя домена Trimastera и 201803 (как год и месяц последнего сохранения рабочей версии сайта исходя из верной «синей» даты на календаре) мы получим все ссылки (без внешних стилей, картинок и других внешних ресурсов).
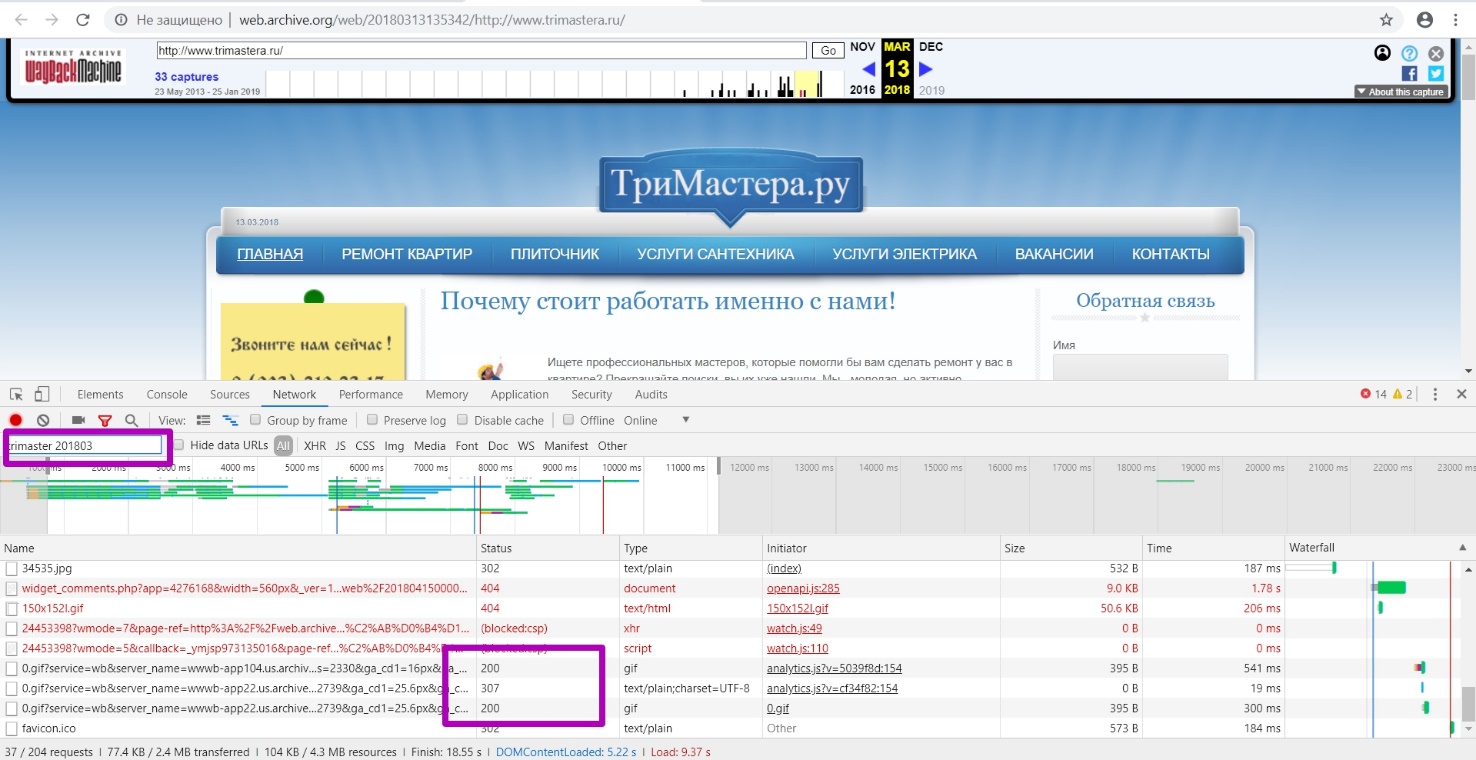
На примере данного домена мы видим много url c 302 кодом, так как веб-архив элементам, расположенным на странице, присваивал такой же timestamp, но при переходе на сам элемент, веб-архив делает редирект на timestamp уже оригинальный.
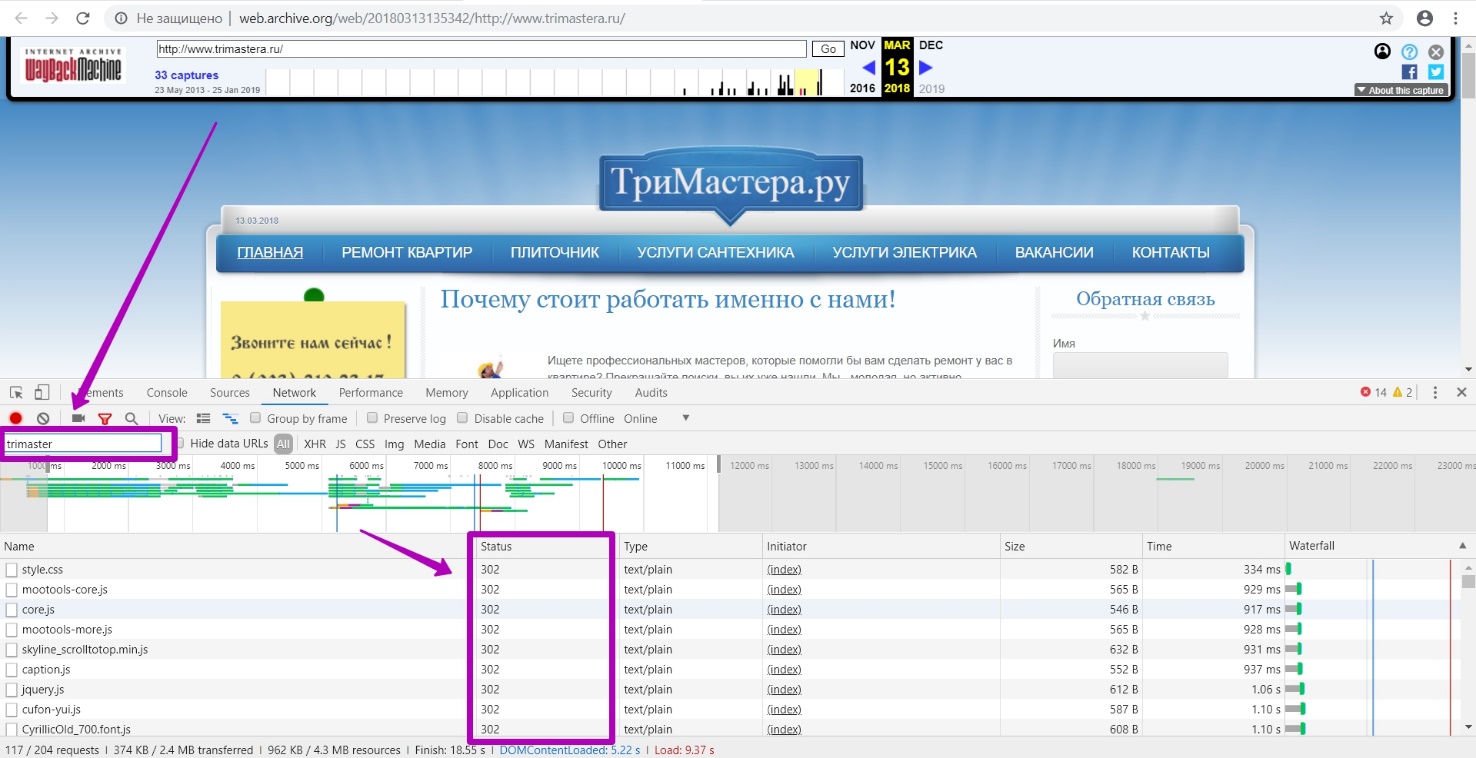
Рассмотрим на примере страницы со стилями style.css. Главный timestamp у нас отображается тот же, что и всей страницы сайта, но переходе на адрес размещения стиля (url непосредственно стиля) мы видим другой timestamp, именно этого элемента.
Поочередно в поиске меняем дату 201803, на большую или меньшую, чтобы определить, были ли в этот период работоспособные страницы, т.е. с кодом 200. Таким образом мы подтверждаем, что март 2018-го ― последний период рабочей индексации сайта.
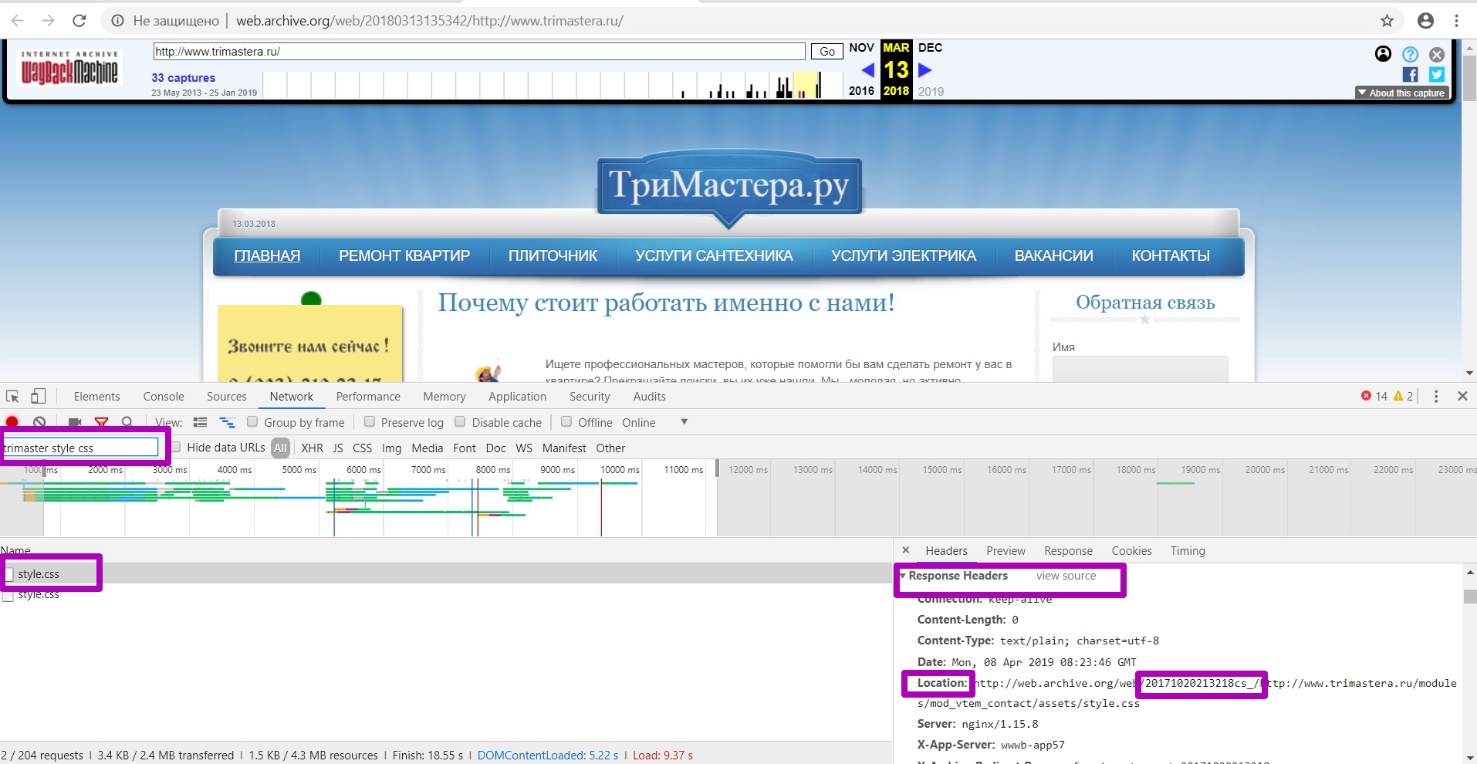
В поле фильтра можно задавать и более широкий промежуток времени, к примеру, только год. Но при постановке такой даты «to», веб-архив будет рассматривать версию за последнюю секунду 2018-го, а в тот момент, как мы видим, сайт не работал. Указание более точного периода, вплоть до секунд, может не захватить отдельные медиа или текстовые элементы, проиндексированные позже.
Открывает инструмент Site Map. Видим, что за 2019 год у нас нет внутренних страниц сайта.
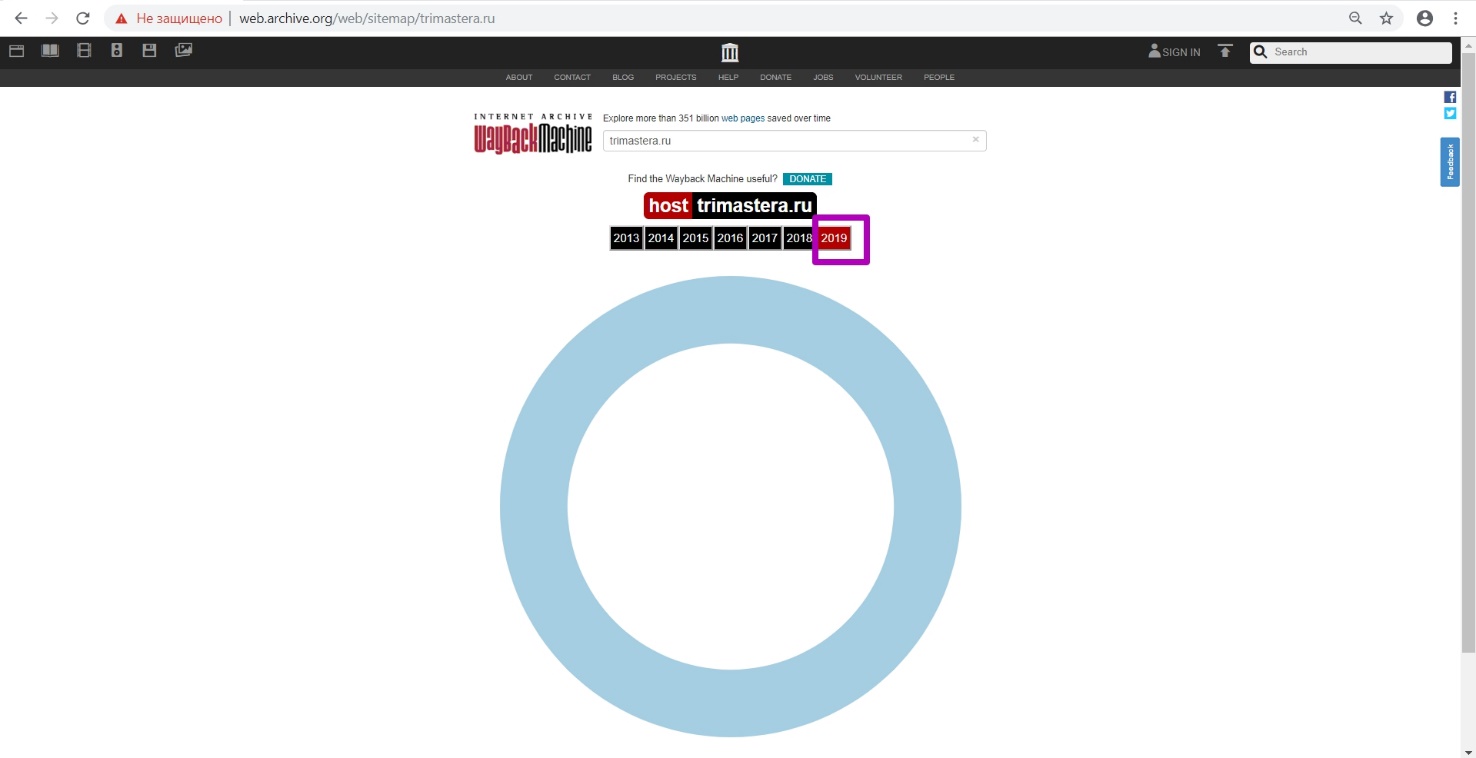
Открываем 2018-й, и видим, что структура сайта отображается, значит, сайт индексировался.
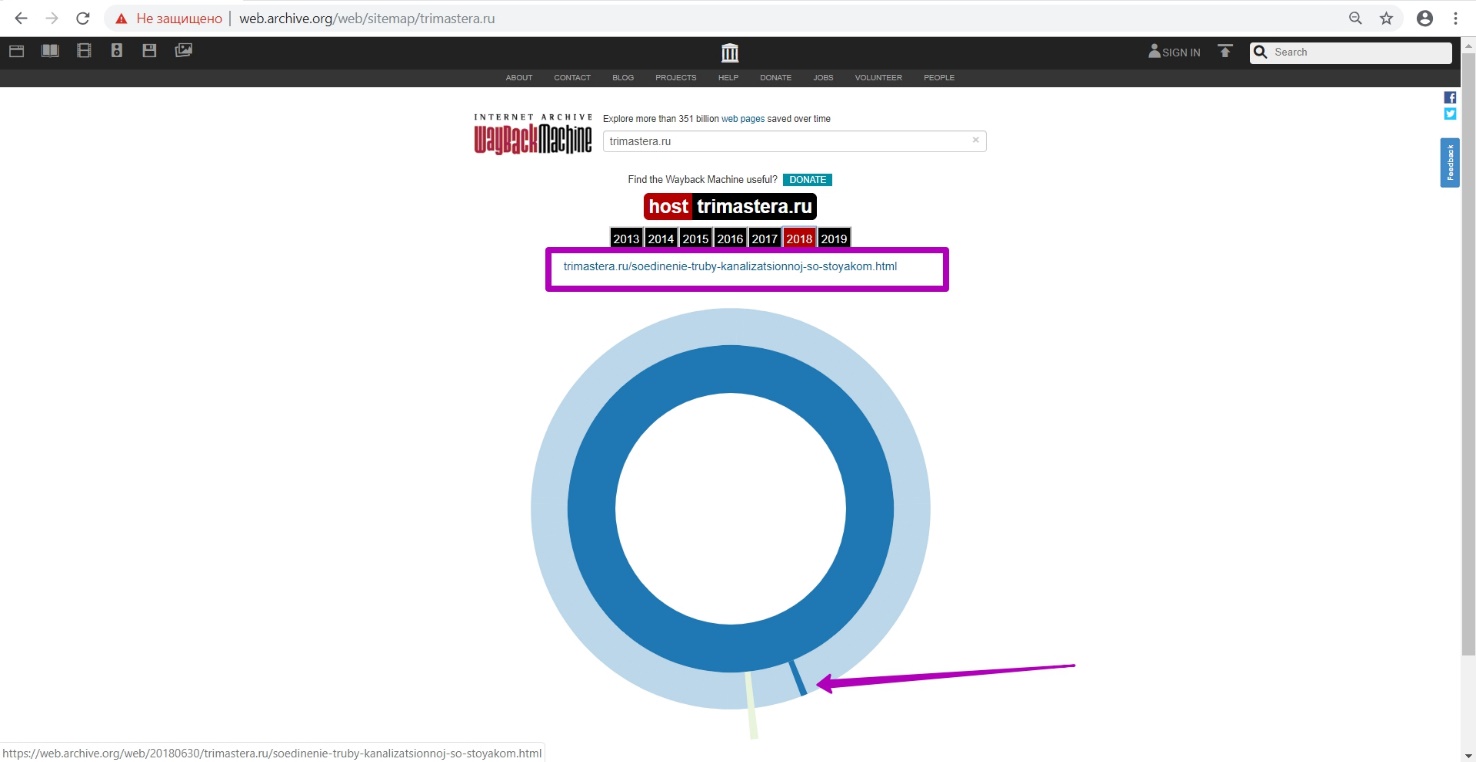
Просматриваем выборочно некоторые страницы в новых вкладках за 2018 год. Как мы видим, timestamp таких страниц зафиксирован 15 марта, хотя и в разное время. Этим самым мы проверяем утверждение про месяц последней работоспособности страниц.
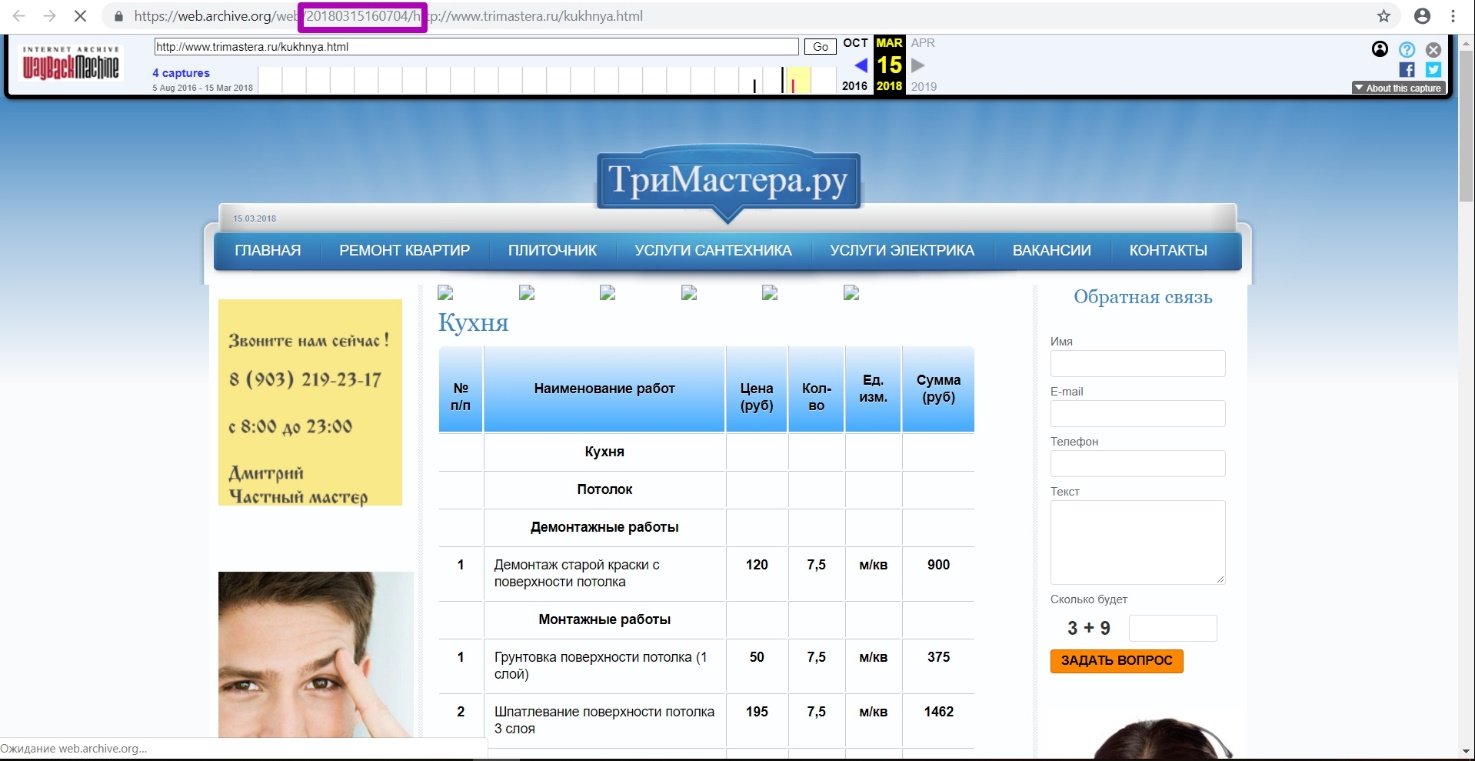
Открываем инструмент Summary за выбранный нами 2018 год. Проверяем в таблице столбик New URLs. За период 2018 года новых ссылок не индексировалось, значит, на момент восстановления мы будем выкачивать из архива последнюю версию сайта.
Открываем инструмент Explore. Анализируем выдачу url в таблице. Если до этого домен был подготовлен верно благодаря файлу robots.txt, мы увидим таблицу всех ссылок на этот год.
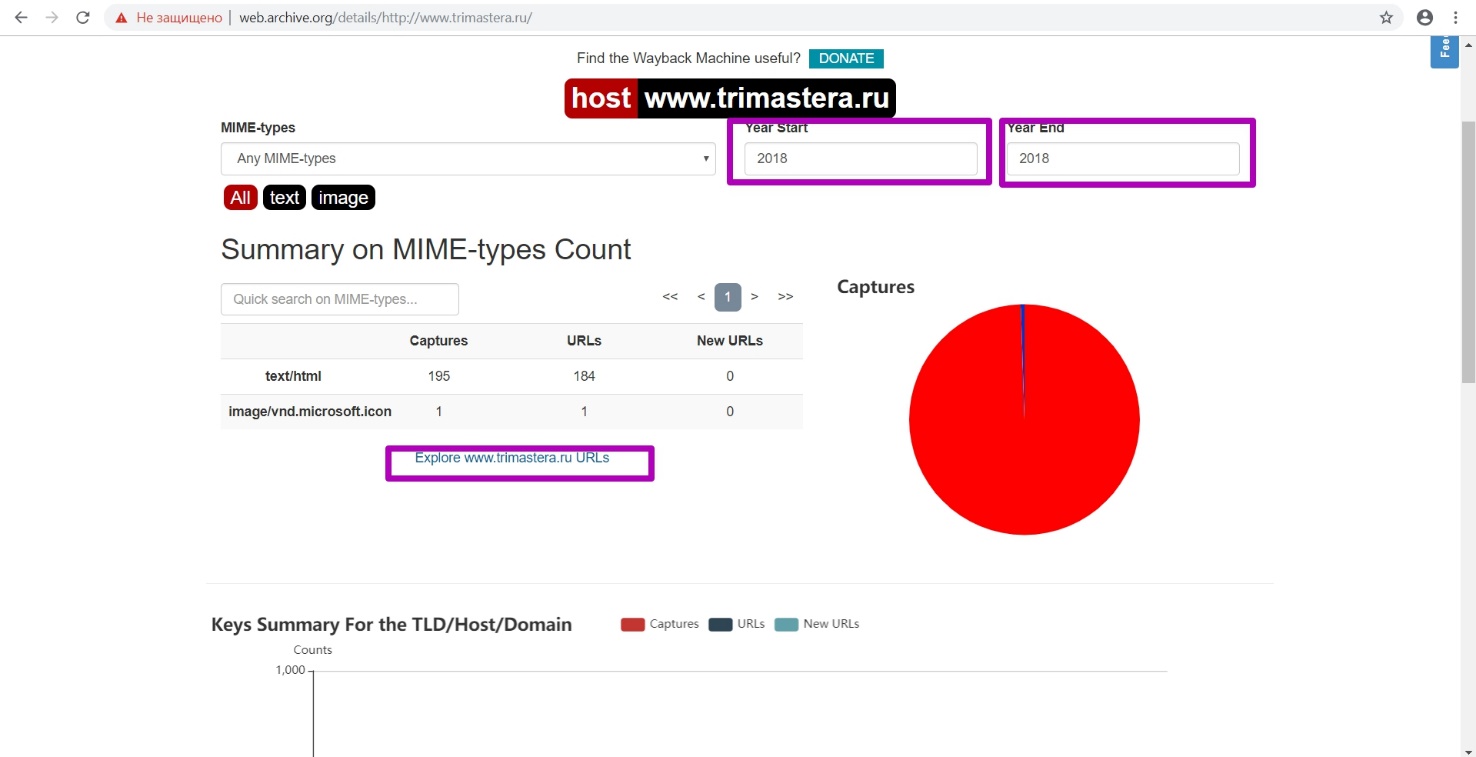
Проверим гипотезу о том, что файл robots.txt закрывает индексирование. Смотрим в календаре все версии документа robots.txt, и видим, что 13 июля 2018 года сайт был закрыт.
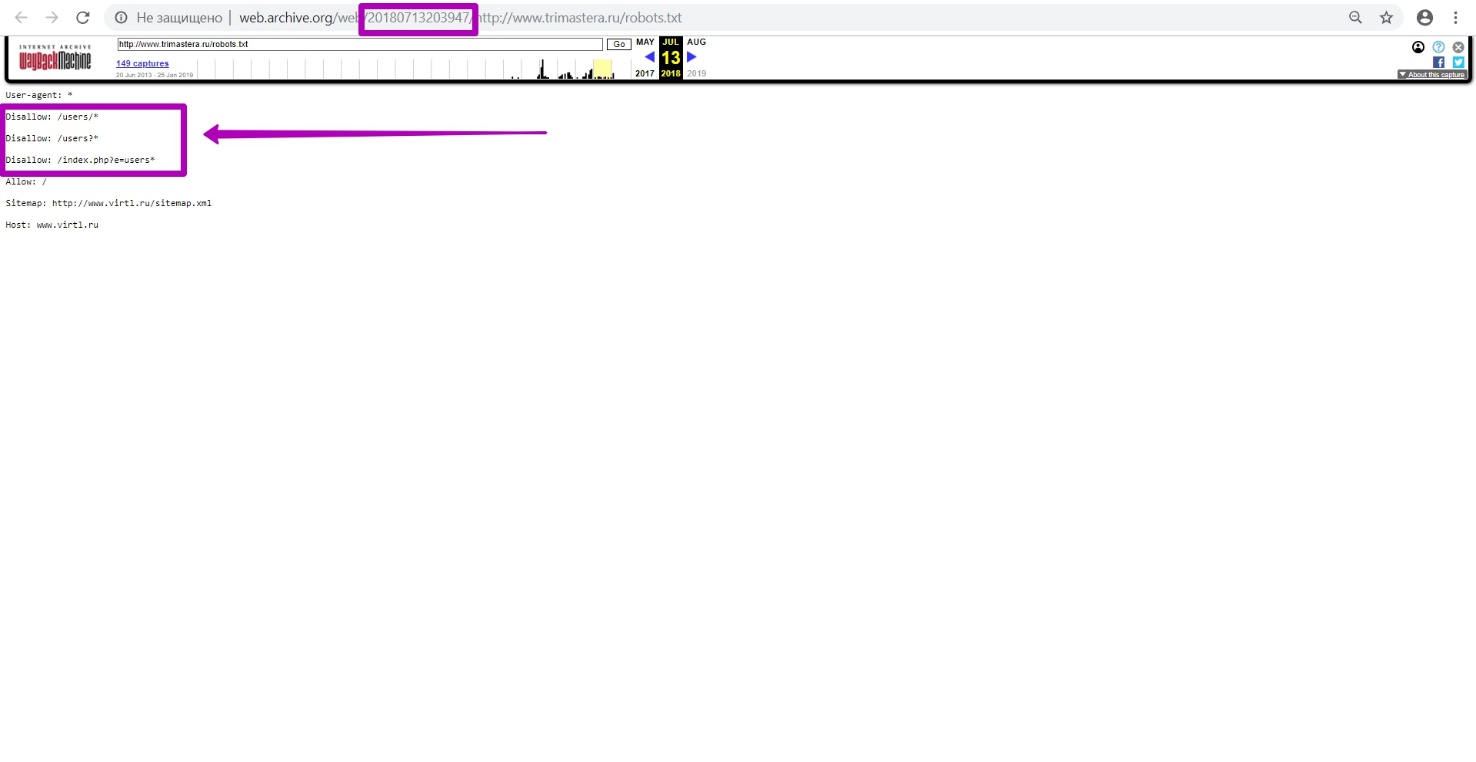
Если вы столкнулись с подобной ситуацией, нужно провести подготовку домена с помощью внедрения нового файла robots.txt, о чем мы рассказали в прошлом гайде.
После успешной подготовки robots.txt в инструменте Explore все ссылки, которые выдаются на интересующий год, сортируем по дате «to» таким образом, чтобы самые последние были вверху. Нас интересуют только те ссылки, которые не имеют редиректа, заглушек, или других внешних элементом (не касаемых содержимого сайта). Самая последняя дата последнего url и будет является крайней датой индексации (сохранения) актуальной версии материалов сайта.
Анализ инструментом Explore, как и в целом работа с датой «to» домена, должна проводится спустя 24-72 часа после загрузки нового файла robots.txt, как мы помним, для того чтобы веб-архив правильно проиндексировал все элементы сайта.
В нашем примере мы не можем отсортировать файлы в веб-архиве, так как до этого не было проведено шага с загрузкой файла robots.txt на новом домене и хостинге.
Сложности при поиске даты «to»
Пример: Сайт mastersila.ru
Проходим те же этапы, что и на прошлом примере:
На календаре сохранения сайта ищем «синюю» дату сохранения (в нашем случае, 4 декабря 2016-го) проверяем отсутствие редиректа и других ошибок. На сохраненной версии страницы переходим к инструменту DevTools (F12 и обновляем через F5). Точно также вводим в поле фильтра часть домена и дату, бОльшую от рассматриваемой (2017). Так как за отобранный период мы не видим ссылок с кодом 200, последняя работоспособность сайта была зафиксирована в 2016 году.
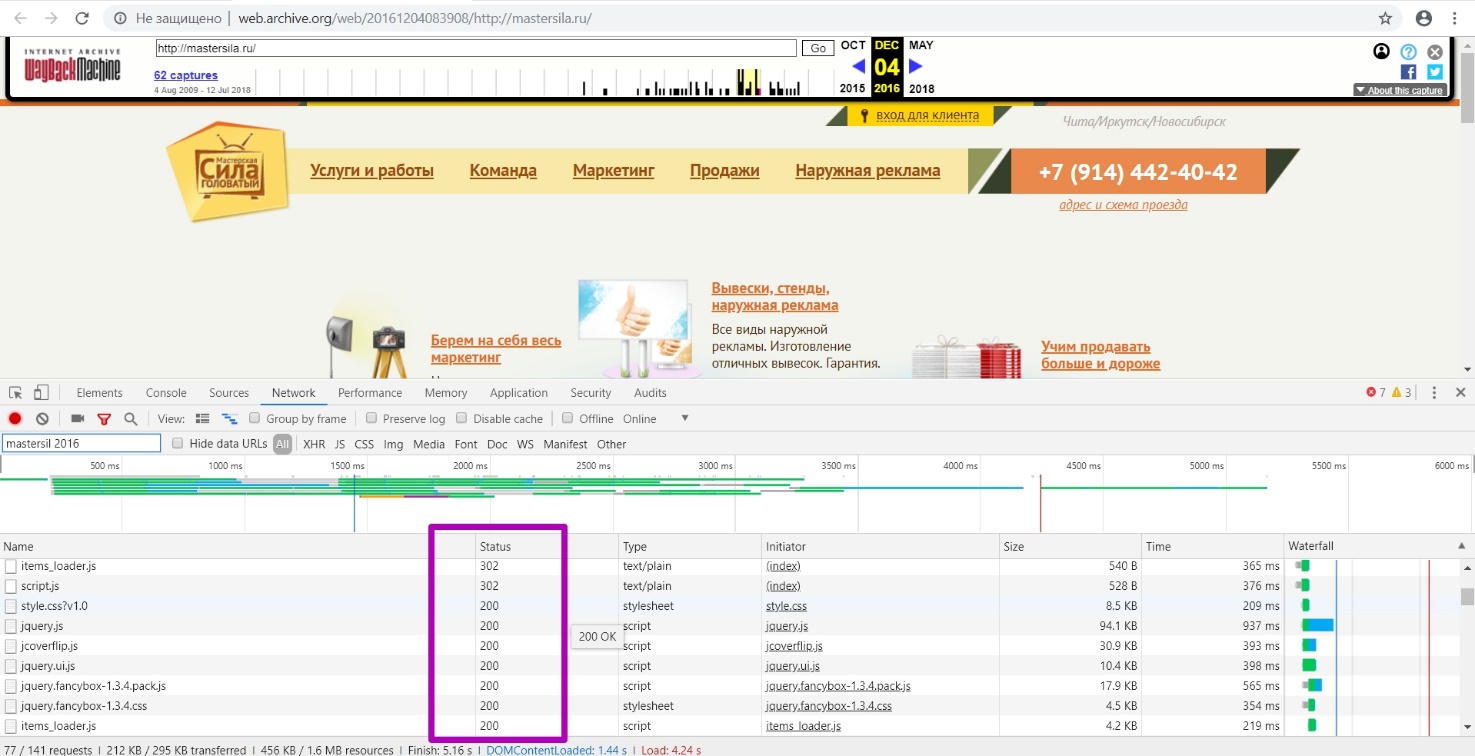
Открываем инструмент Site Map и проверяем гипотезу. В большинстве случаев, в инструменте Site Map последний год отображения структуры и будет последним годом работоспособности сайта.
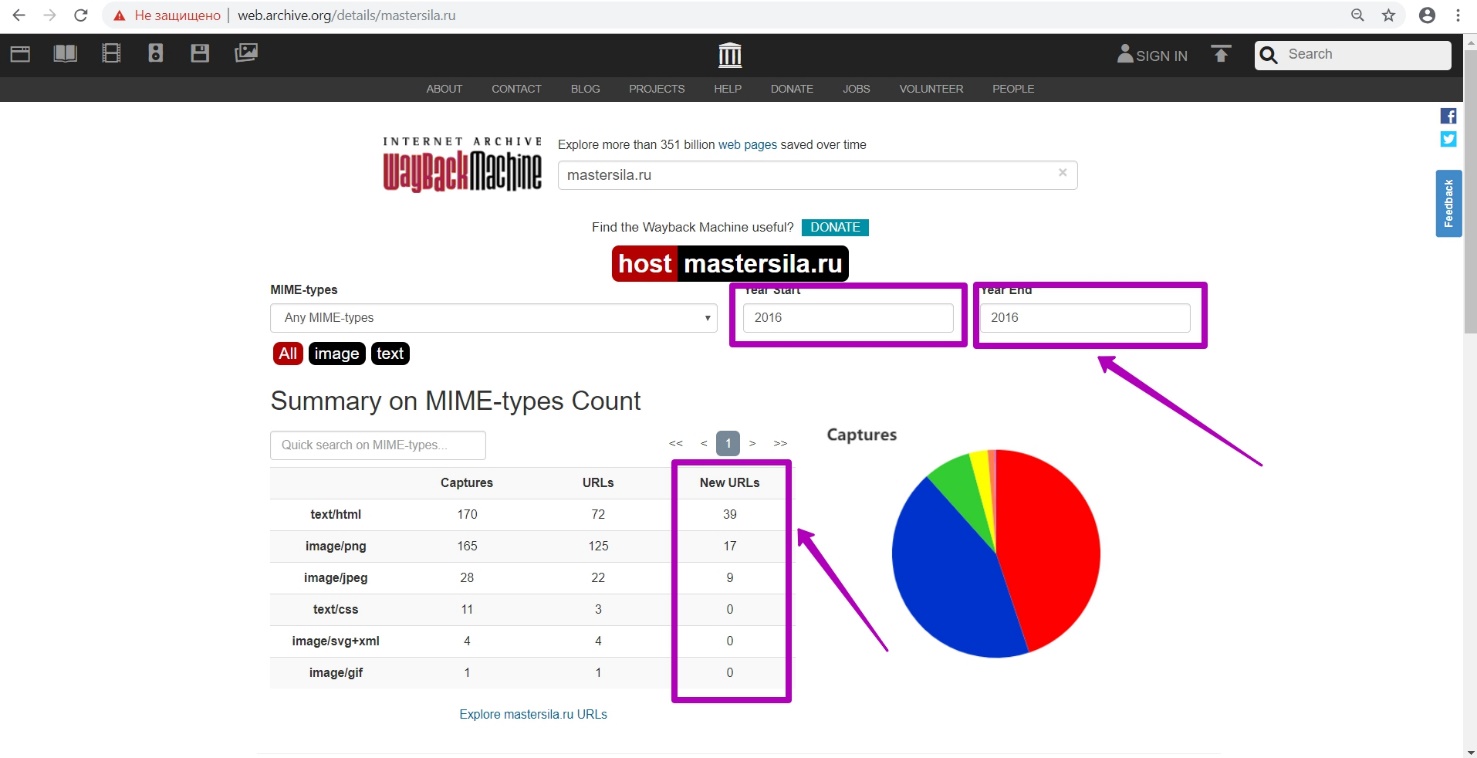
Как мы видим, последний год сохранения ― 2016, что подтверждает наше предположение. Именно в этот период у нас отображается рабочая структура, сохраненная веб-архивом. Переходим к инструменту Summary. Просматриваем результаты в разделе New URLs за период 2016 года. Как видим, в этот период новых уникальных ссылок сгенерировалось 39, значит, в этом году сайт был в последний раз работоспособный с актуальными версиями страниц.
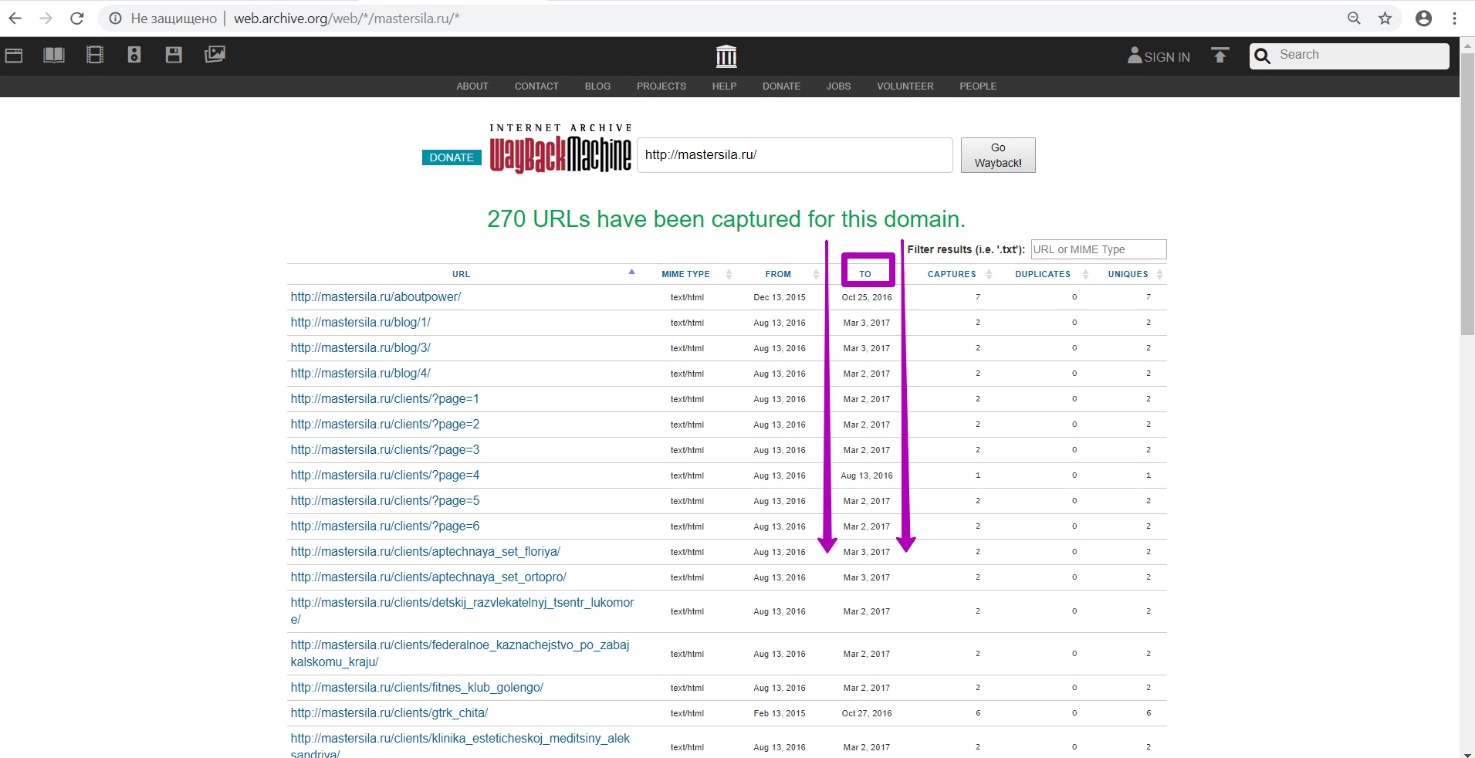
Открываем инструмент Explore. Так как у нас выводится таблица результатов, сайт открыт к индексированию, значит robots.txt на нем не закрывал доступ ботам. Сортируем результаты от последнего. Проверяем ссылки на работоспособность, исключая ссылки с редиректом и ошибками. За 2018 год все ссылки ― редирект. За 2017 отображаются новые материалы, проиндексированные 3 марта.
Проверяем ссылки, и видим, что это редирект-страницы. Значит, их не стоит рассматривать как рабочие страницы, необходимые к восстановлению.
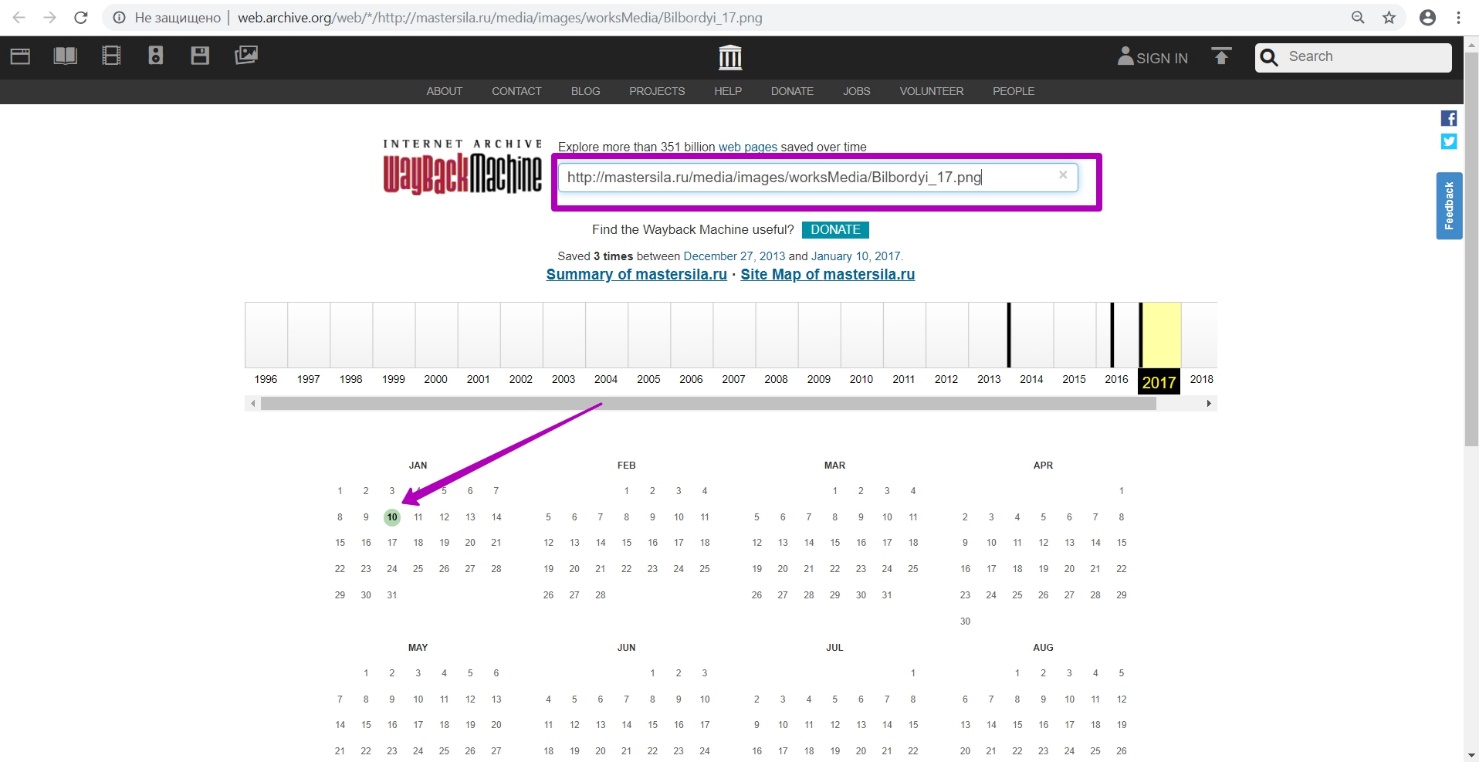
Проверяем ссылки за 2016 год. Подтверждаем гипотезу, что декабрь 2016-го ― наша дата «to» для домена, так как ссылки рабочие.
Пример : Сайт Gkvolga.ru
Как и в прошлых примерах, смотрим последнюю версию сайта за 2018 год. Определим, что в марте 2015-го сайт работал.
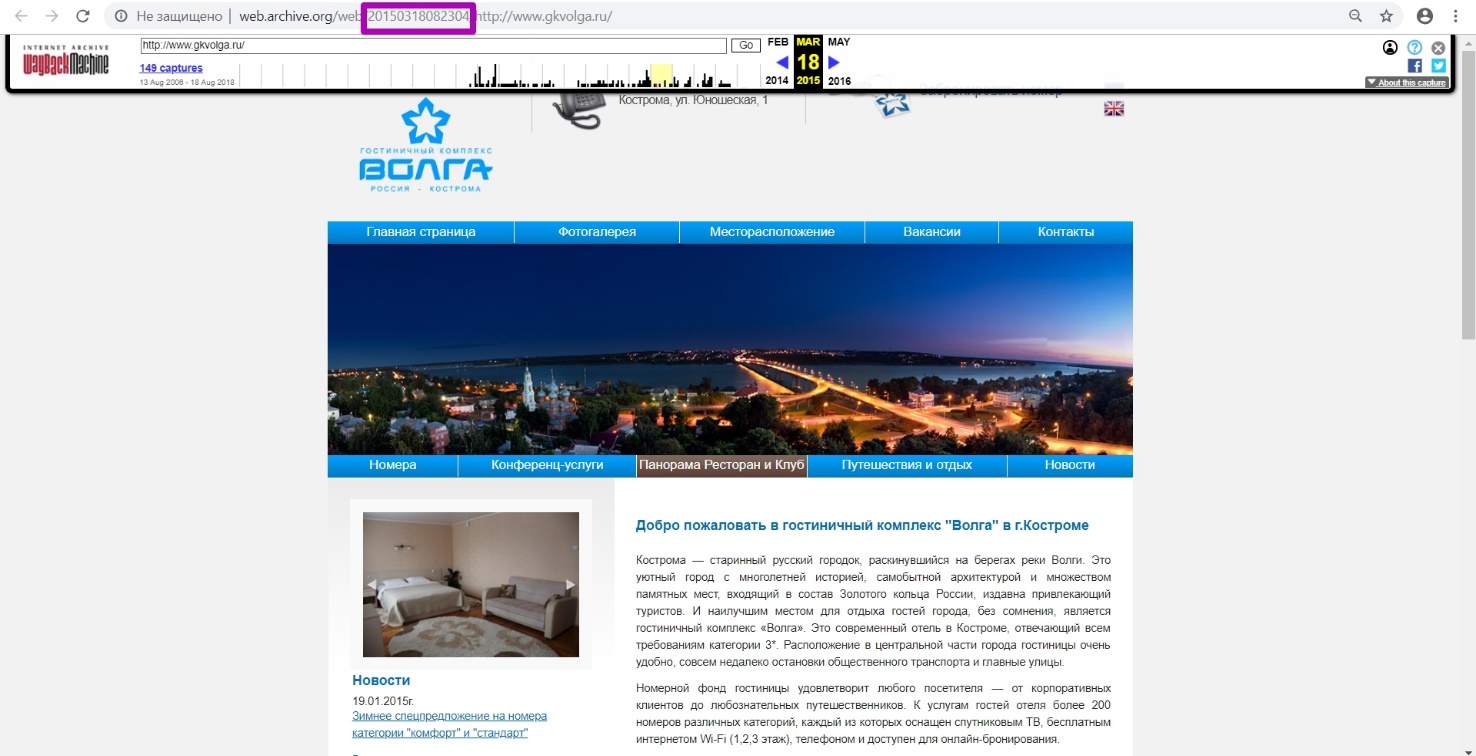
Снова выбираем инструмент DevTools через F12+F5 в выбранной нами версии за 18 марта 2015 года. Как и раньше, вводим название домена и методом подбора даты ищем период последней выгрузки кода 200 с сайта. Методом отбора по месяцам также подтверждаем, что март 2015-го ― последний период работоспособности сайта. Переходим на инструмент Summary. Открываем предполагаемый год ― 2015.
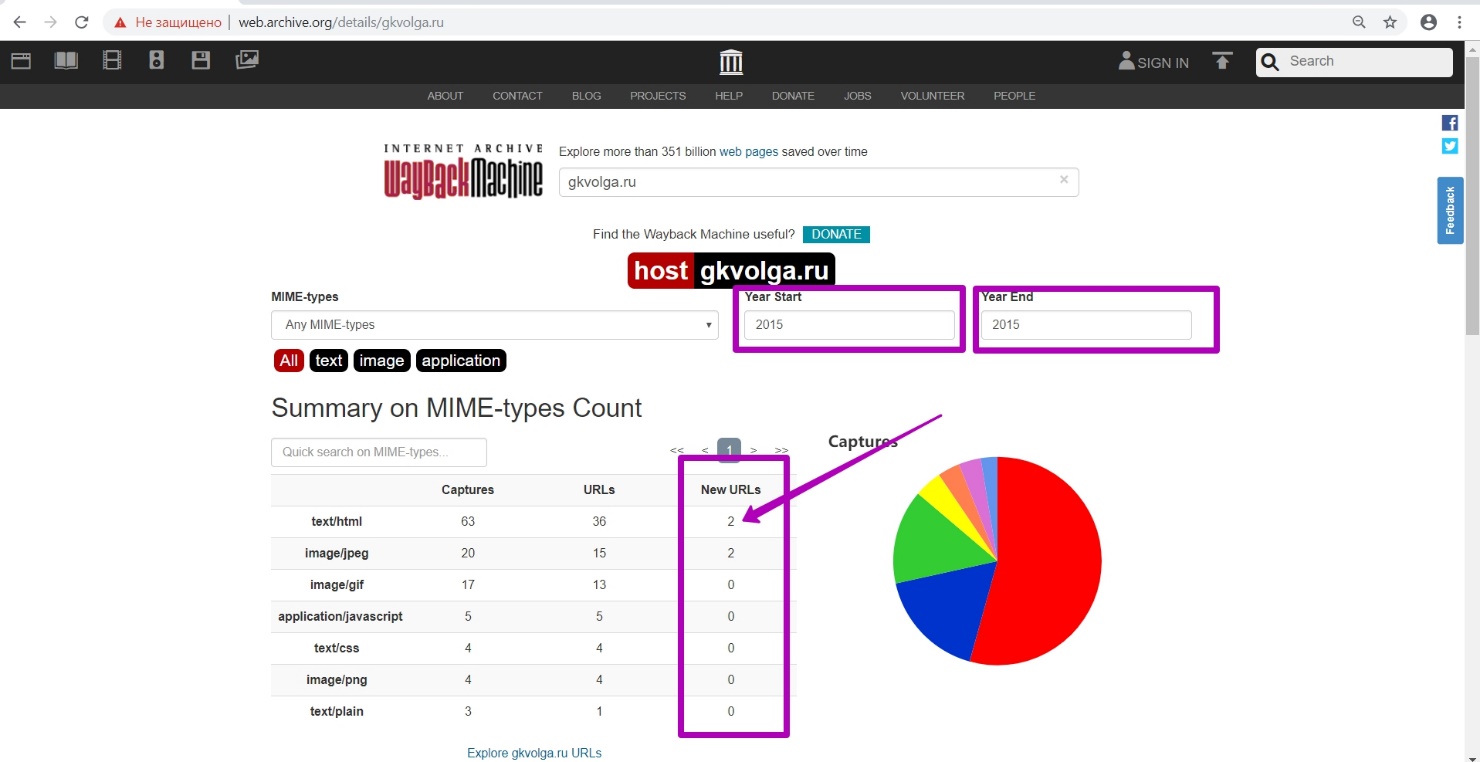
Видим, что в этот период было сгенерировано 2 новых файла. Если бы было создано много файлов, мы искали бы их в апреле, мае. Но 2 файла мы будем искать в указанный месяц - устанавливая дату «to» 201503.
Для подтверждения наших догадок открываем инструмент Explore (на 2015 год), и видим, что данные сайта уже не индексируются (нет выгрузки таблицы).
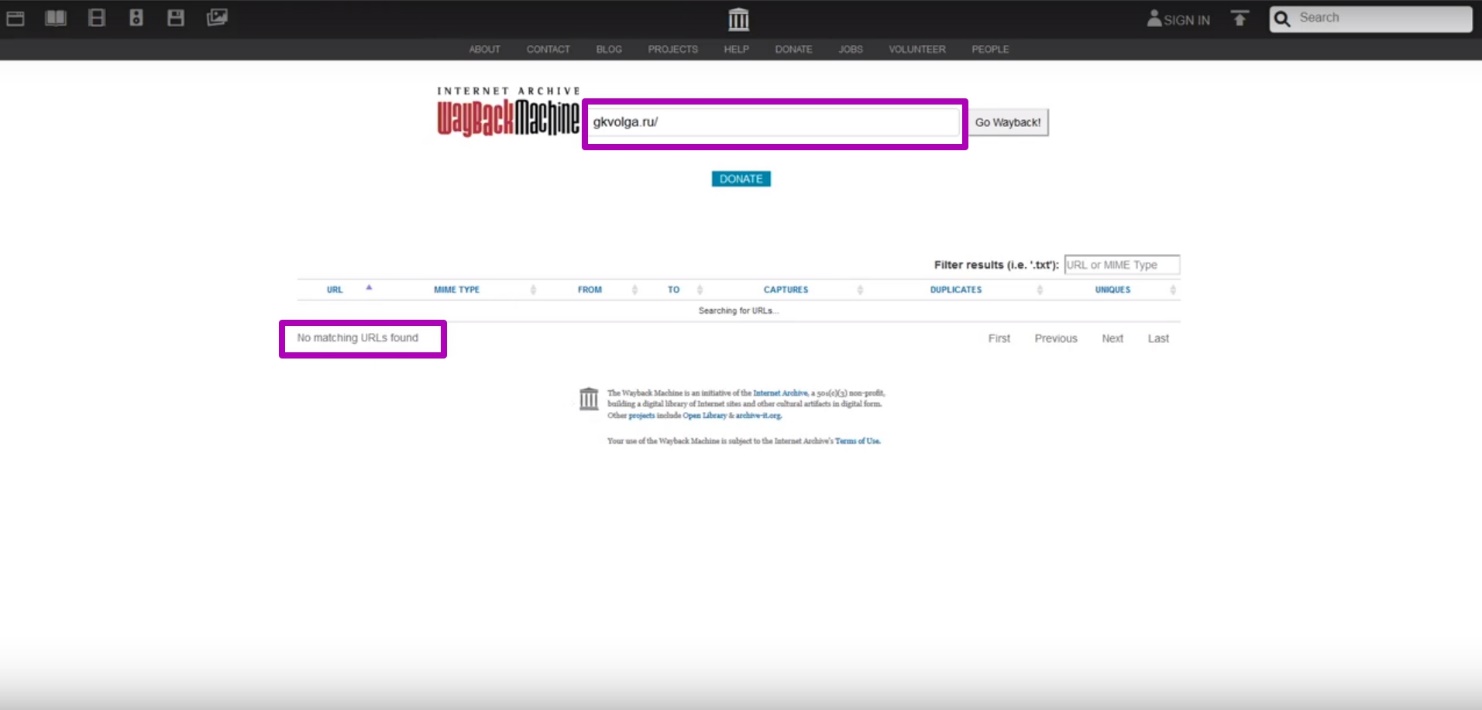
Т.е. на сайте установлены ограничения robots.txt. Делаем вывод, что определенная нами дата является последней, когда сайт был работоспособным.
Этот видео гайд есть на Youtube:
Как восстанавливать сайты из Веб Архива - archive.org. Часть 1
Как восстанавливать сайты из Веб Архива - archive.org. Часть 2
Использование материалов статьи разрешается только при условии размещения ссылки на источник: https://archivarix.com/ru/blog/3-how-does-it-works-archiveorg/

В этой статье мы расскажем о самом web.archive и о том, как он работает. Интерфейс веб-архива: инструкция к инструментам Summary, Explore и Site map. В этой статье мы расскажем о самом web.archive и…
Подготовка домена к восстановлению. Создание robots.txt
В прошлой статье мы рассмотрели работу сервиса archive.org, а в этой статье речь пойдет об очень важном этапе восстановления сайта из веб-архи…
Выбор ограничения ДО при восстановлении сайтов из веб-архива. Когда домен заканчивается, на сайте может появится заглушка домен-провайдера или хостера. Перейдя на такую страницу, веб-архив будет ее со…