Примеры использование регулярных выражений в Archivarix CMS
Как генерировать метатег description на всех страницах сайта? Как сделать, так чтобы сайт работал не из корня, а из директории?
Иногда бывает, что на некоторых страницах восстановленного сайта нет тега description. Его можно добавить вручную, но если он отсутствует на сотнях или тысячах страниц, то сделать это будет сложно. Чтобы долго не думать над составлением описаний страниц, можно просто ставить в этот тег первую фразу, встречающуюся в тексте на этой странице. Как правило она будет релевантной.
На помощь тут может придти возможность применять регулярные выражения для поиска и замены в Archivarix CMS. Просто скопируйте указанные ниже выражения в соответствующие поля инструмента Поиск и замена и запустите процесс.
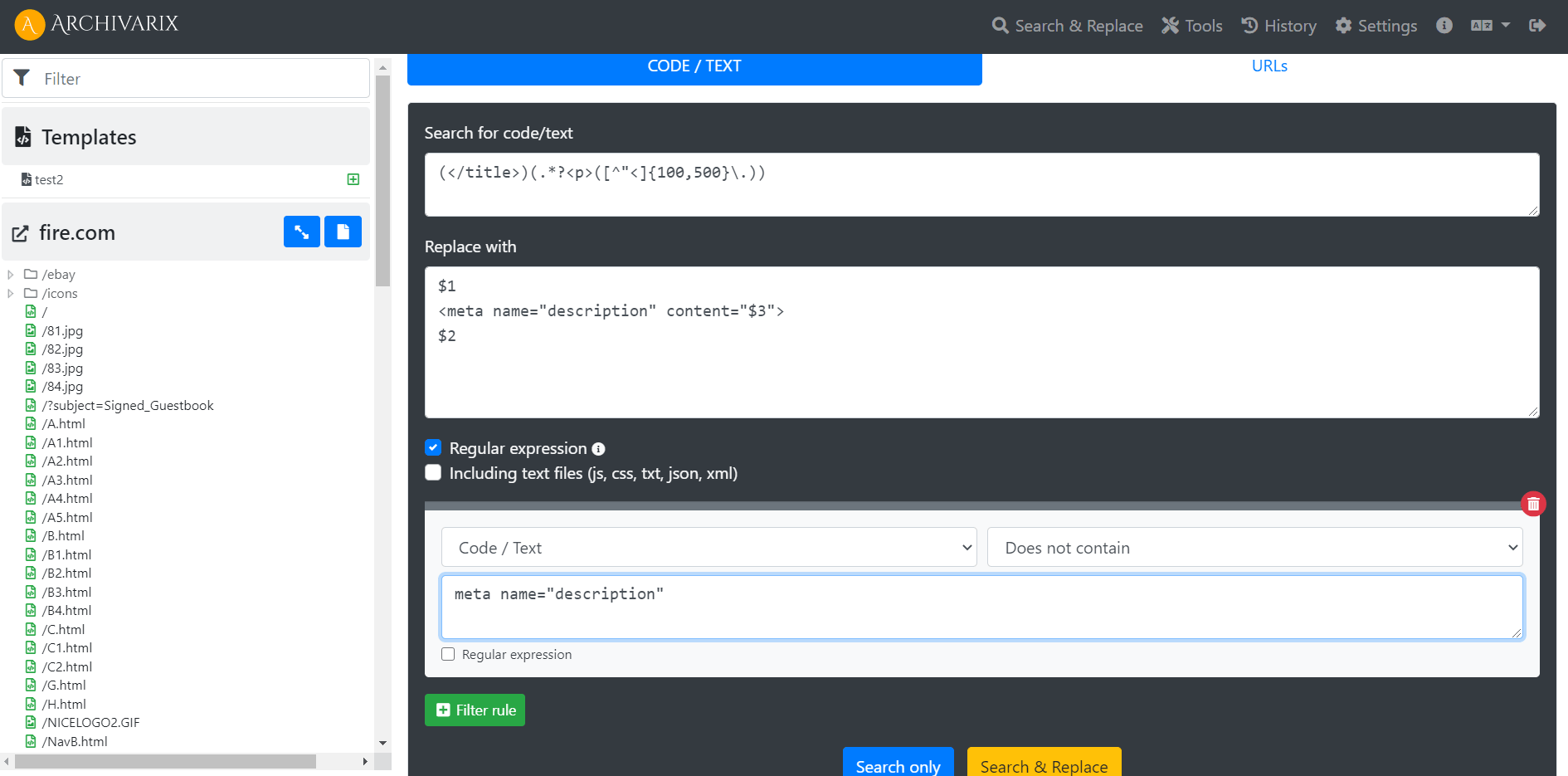
(</title>)(.*?<p>([^"<]{50,200}\.))
$1
<meta name="description" content="$3">
$2
meta name="description"
Это выражение создает тег <meta name="description" content= сразу после закрывающего тега </title> и добавляет туда текст со страницы, начинающийся с тега абзаца <p> и имеющий минимально 20 символов, а максимально 200 символов и закрывает тег точкой . . Поле фильтра делает замены только на тех страницах, где нет meta name="description" , если он есть замена не производится.
Еще один пример: Восстановленный сайт можно переделать так, что он сможет работать из директории, а ни из корня. Это может понадобиться, если вам надо разместить несколько восстановленных сайтов на одном домене.
Для начала поменяем все пути в структуре сайта. Это делается в инструменте Поиск и замена URL.
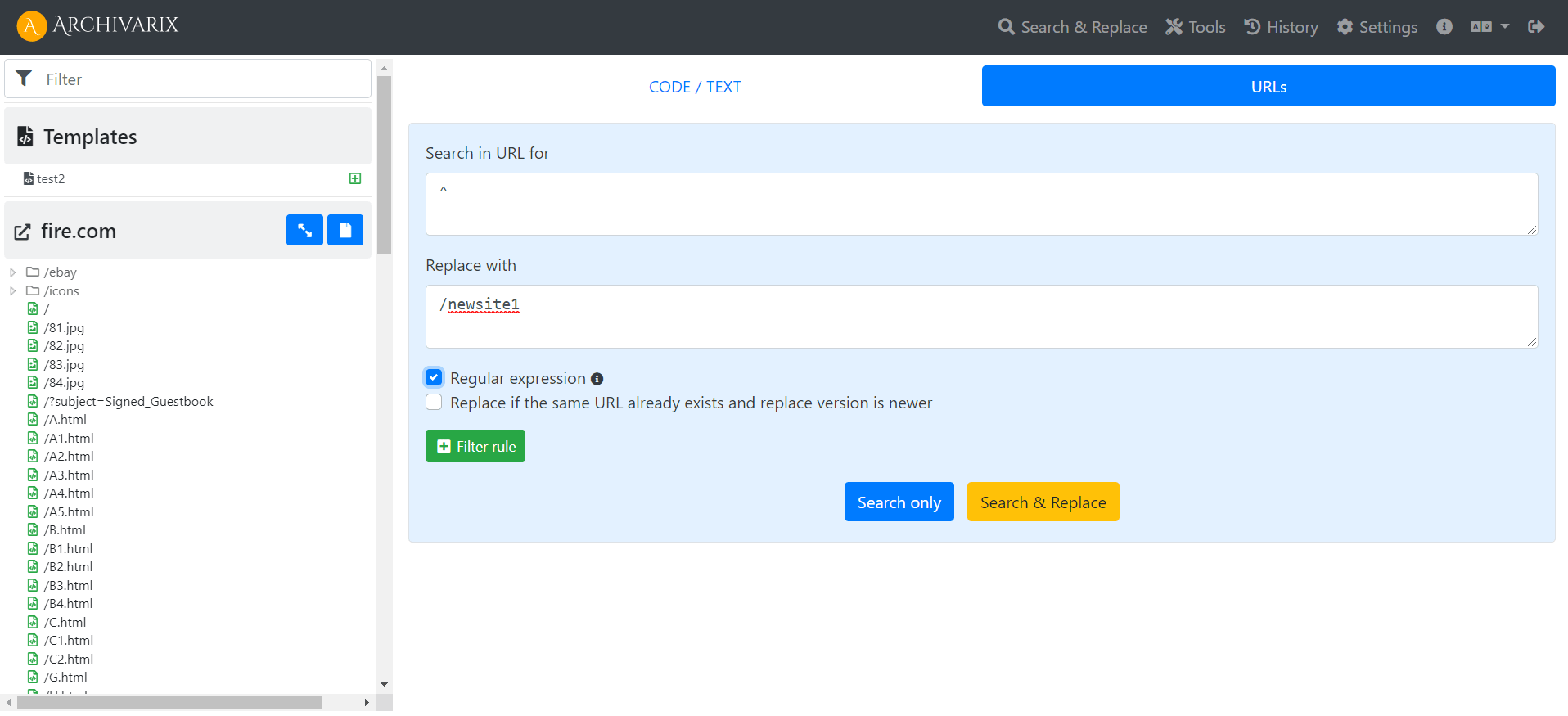
Ко всем URL с начала ^ мы добавляем новый путь /newsite1
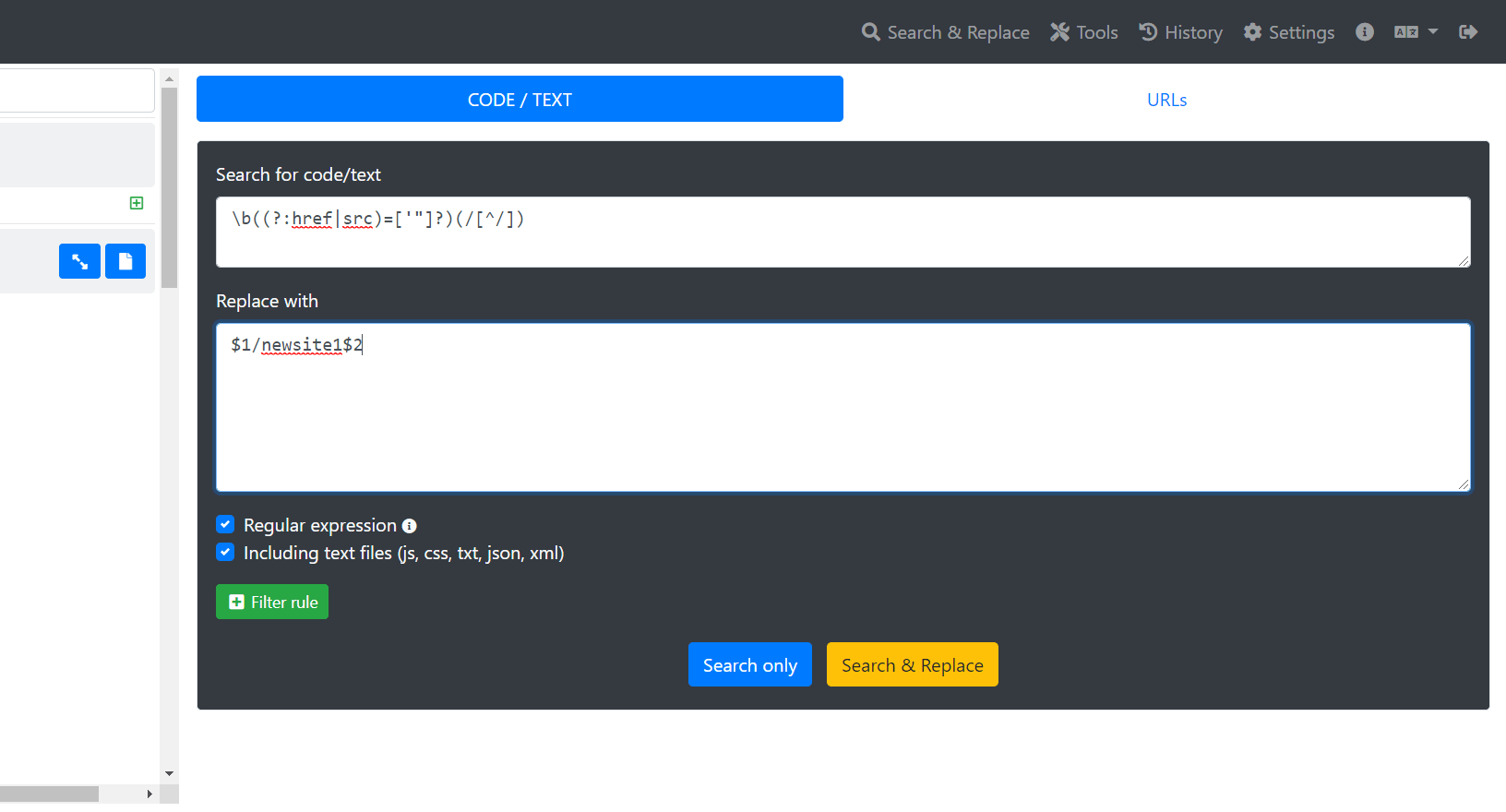
Далее заменяем все адреса внутри страниц используя регулярные выражения, обязательно галочкой включите в запрос все файлы (js, css, txt, json, xml):
\b((?:href|src)=['"]?)(/[^/])
$1/newsite1$2
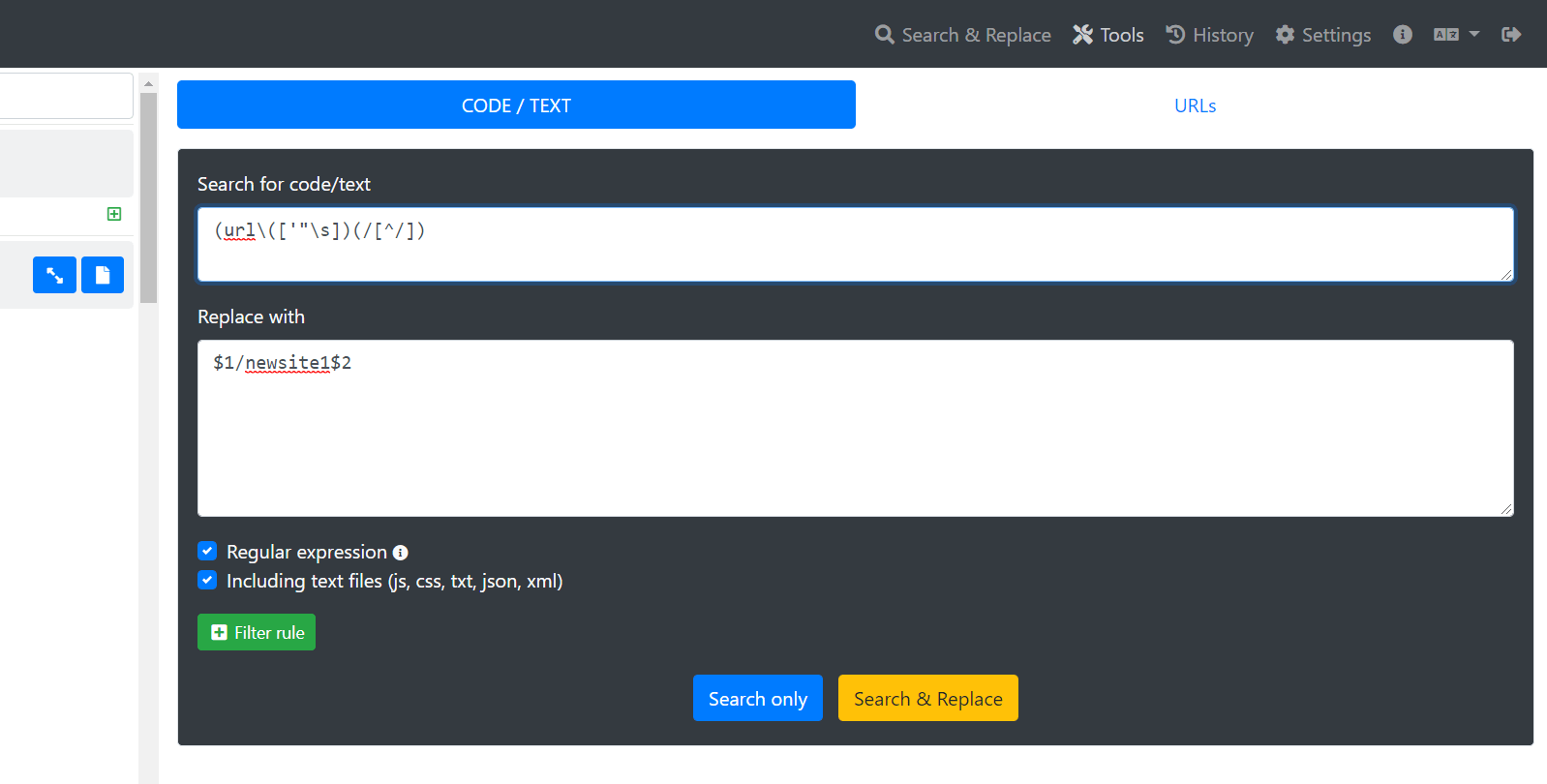
Для исправления ссылок на картинки в файлах CSS можно воспользоваться таким регулярным выражением:
(url\(['"\s])(/[^/])
Теперь в файле .htaccess надо заменить строку RewriteRule . /index.php [L] на такую строку - RewriteRule . /newsite1/index.php [L]
Теперь ваш сайт будет работат по адресу domain.com/newsite1
Использование материалов статьи разрешается только при условии размещения ссылки на источник: https://archivarix.com/ru/blog/regex-add-description-website-on-subfolder/

У Tube Search появился раздел бесплатных YouTube-инструментов. Это небольшие утилиты, которые решают конкретные повседневные задачи: рассмотреть видео покадрово, вытащить скрытые теги, проверить занят…
Вы нашли на YouTube нужное видео, но не хотите его смотреть целиком ради пары фраз. Или вам нужен текст лекции, чтобы перевести его, процитировать или просто прочитать по диагонали. Субтитры YouTube р…
Откройте любую статью десятилетней давности и пройдитесь по ссылкам в ней. С большой вероятностью часть из них уже никуда не ведёт. Вместо нужной страницы вас встретит ошибка 404, припаркованный домен…
Интернет постоянно осыпается. Страницы уходят в офлайн, аккаунты удаляют, статьи прячут за пейволл, проекты закрывают. Но копии чаще всего где-то остаются: Wayback Machine, archive.today, Common Crawl…
Когда вы находите удалённое видео YouTube через Tube Search, вы обычно получаете метаданные: название, описание, дату загрузки и иногда субтитры. Это уже полезно. Но чтение необработанных субтитров, ч…
Tube Search - это поисковый движок по архивным данным YouTube. Сервис агрегирует информацию из нескольких публичных источников: Wayback Machine (Internet Archive), Common Crawl и различных собранных д…
Со временем внешние ссылки в записях Wordpress неизбежно ломаются, страницы удаляются, домены истекают, видео становятся недоступными. Проверять сотни или тысячи ссылок вручную непрактично. Archivarix…
Триллион сохранённых страниц. Более 99 петабайт данных. Сотни краулов, работающих каждый день одновременно. За этими цифрами стоит вопрос, который задаёт себе каждый, кто профессионально работает с ве…
Покупка истёкшего домена с историей это один из самых эффективных способов запустить новый проект с уже существующим ссылочным профилем, трастом и даже трафиком. Вместо того чтобы продвигать голый дом…
Когда речь заходит о восстановлении сайтов из архивов, почти все думают только о Wayback Machine. Это понятно: archive.org на слуху, у него удобный интерфейс, триллион сохранённых страниц. Но Wayback …