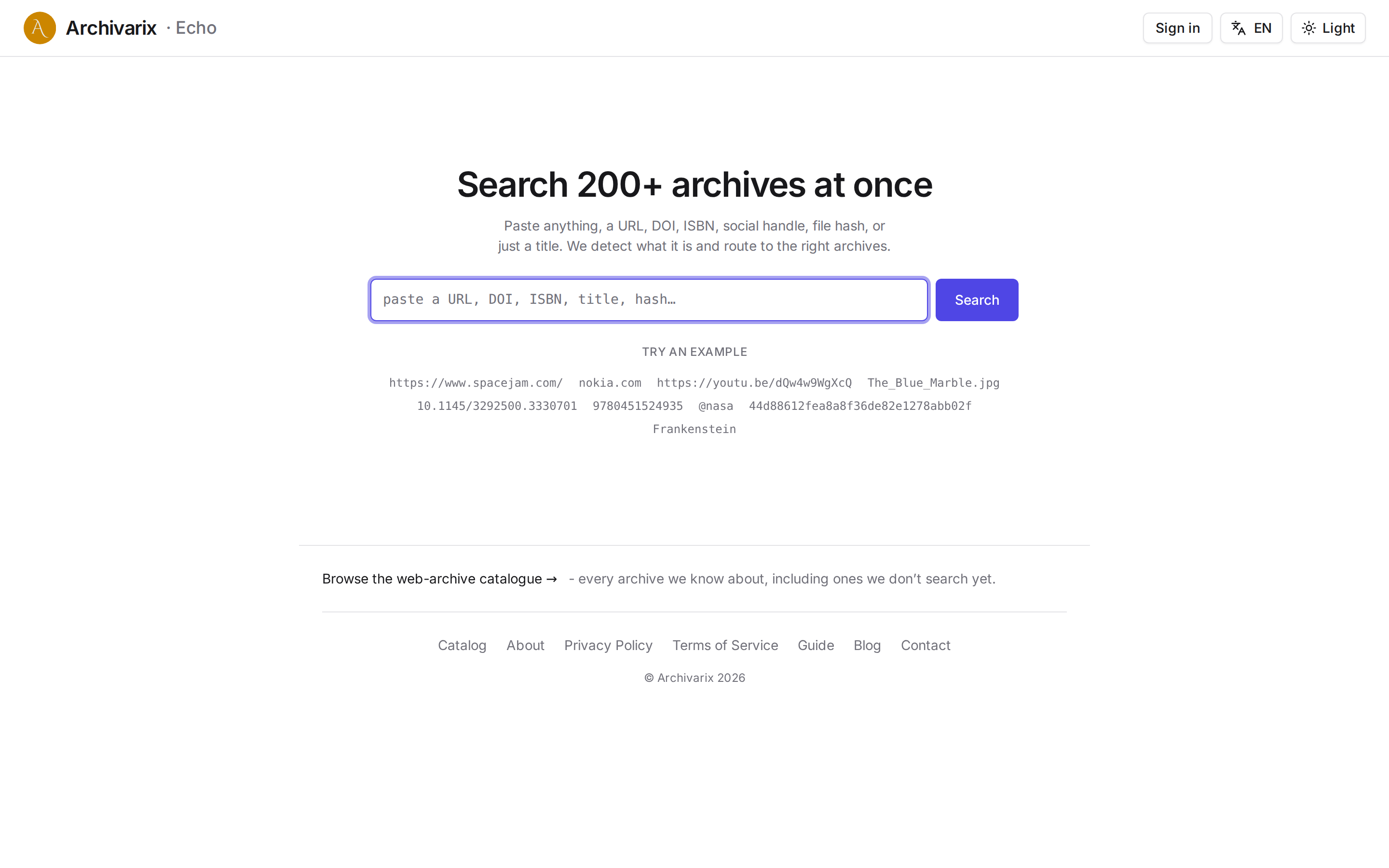
Archivarix Echo: проверьте 200+ веб-архивов одним запросом
Интернет постоянно осыпается. Страницы уходят в офлайн, аккаунты удаляют, статьи прячут за пейволл, проекты закрывают. Но копии чаще всего где-то остаются: Wayback Machine, archive.today, Common Crawl, научные индексы вроде Crossref, библиотеки вроде Open Library и ещё сотни узких, тематических архивов. Беда в том, что все они порознь. Чтобы понять, где что сохранилось, раньше приходилось открывать их по очереди: сначала Wayback, потом archive.today, потом десяток научных и книжных баз.
Echo убирает этот ручной обход. Вы вставляете в одну строку что угодно: ссылку, домен, DOI, ISBN, ник, хеш файла или просто название. Echo распознаёт, что это, и сразу даёт готовые ссылки в те архивы, которые умеют отвечать на такой запрос.
Важная деталь: Echo ничего не скачивает и не разбирает за вас. Он не открывает страницы и не проверяет, есть ли там копия. Его работа в другом: понять, что вы вставили, и показать, в какие именно архивы за этим идти. Дальше вы переходите по ссылкам сами.
Категорию выбирать не надо. Echo узнаёт тип ввода по виду и подбирает источники сам.
Ссылка на страницу ведёт к её снимкам в больших веб-архивах: Wayback Machine (больше триллиона страниц), archive.today, Common Crawl, Perma.cc, Ghostarchive, плюс национальные архивы. Голый домен открывает не одну страницу, а весь сохранённый сайт, и заодно даёт ссылку на crt.sh, где по истории SSL-сертификатов видно поддомены и прошлое сайта. DOI отправляет к научной статье в Crossref, OpenAlex, Semantic Scholar и к полному тексту в Anna's Archive. ISBN ведёт к книге в Open Library, HathiTrust и Google Books. Ник вида @nasa уводит в соцсети, хеш файла к Software Heritage и VirusTotal, ссылка на картинку в обратный поиск по изображению.
А если идентификатора нет, просто наберите название, имя или несколько слов. Тогда Echo разворачивает запрос по всем архивам, где есть полнотекстовый поиск, и раскладывает их по темам: книги, статьи, патенты, изображения, музеи, карты. «Frankenstein» уйдёт в Open Library, Gutenberg и Wikisource; «attention is all you need» в arXiv, PubMed и DBLP.
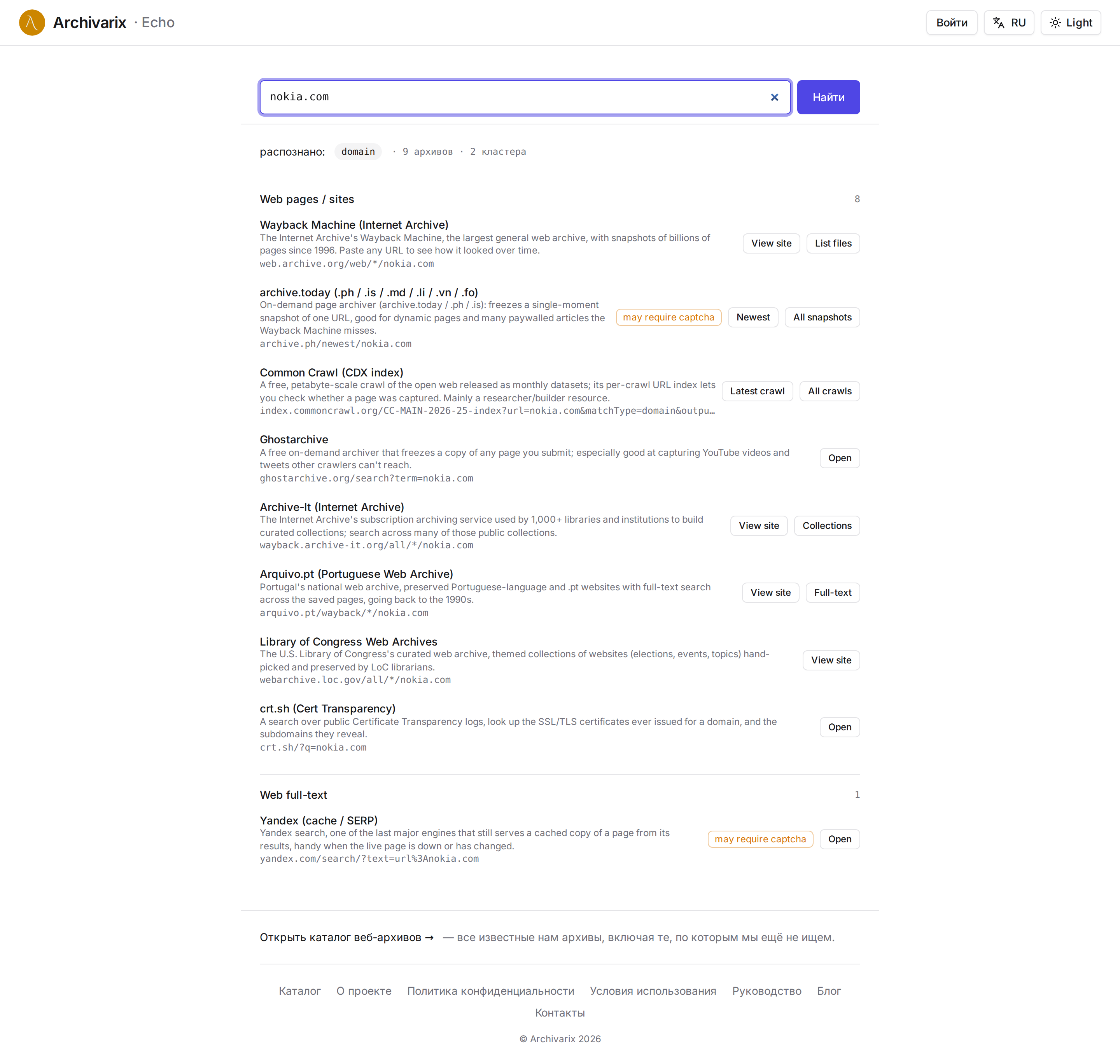
Как устроен поиск
Внутри ничего хитрого. Вставили запрос, нажали «Найти». Echo определяет, что это за тип, и собирает из своего каталога все архивы, которые с таким запросом работают. Дальше раскладывает их по группам и для каждого даёт прямую ссылку: в снимок страницы, в карточку статьи, в книгу, в профиль. Над выдачей видно, чем Echo счёл ваш ввод, так что промах заметен сразу.
То есть результат это не «вот ваша копия», а «вот где её искать». Echo доводит вас до нужной двери, а открываете её вы. Какие-то архивы открыты полностью, какие-то прячут поиск за капчей или закрыты для роботов; такие Echo всё равно показывает, с прямой ссылкой и пометкой, как искать вручную. Где довести прямо до результата не выходит, там так и говорим и показываем, куда идти.
Чего ждать не стоит
Своего контента у Echo нет, он его не хранит. Архивы держат только то, что успели сохранить до пропажи. Если страницу, статью или ролик ни один публичный архив так и не забрал, доставать нечего. Лучше всего находится то, что было публичным, популярным или на что ссылались в науке.
Каталог
Кроме самого поиска у Echo есть каталог всех известных нам архивов, включая те, что пока нельзя опросить программно. Его можно листать и фильтровать по категории, кластеру, наличию API и типу доступа, чтобы просто посмотреть, что вообще есть и что в каждом архиве лежит.
Бесплатно и на шести языках
Echo работает без JavaScript, так что любой поиск это обычная ссылка, её удобно сохранить или переслать. Интерфейс на шести языках: русский, английский, испанский, немецкий, португальский, французский. В базовом виде всё бесплатно; бесплатный аккаунт поднимает дневной лимит и хранит историю запросов.
Попробуйте: echo.archivarix.net
Использование материалов статьи разрешается только при условии размещения ссылки на источник: https://archivarix.com/ru/blog/archivarix-echo/

Интернет постоянно осыпается. Страницы уходят в офлайн, аккаунты удаляют, статьи прячут за пейволл, проекты закрывают. Но копии чаще всего где-то остаются: Wayback Machine, archive.today, Common Crawl…
Когда вы находите удалённое видео YouTube через Tube Search, вы обычно получаете метаданные: название, описание, дату загрузки и иногда субтитры. Это уже полезно. Но чтение необработанных субтитров, ч…
Tube Search - это поисковый движок по архивным данным YouTube. Сервис агрегирует информацию из нескольких публичных источников: Wayback Machine (Internet Archive), Common Crawl и различных собранных д…
Со временем внешние ссылки в записях Wordpress неизбежно ломаются, страницы удаляются, домены истекают, видео становятся недоступными. Проверять сотни или тысячи ссылок вручную непрактично. Archivarix…
Триллион сохранённых страниц. Более 99 петабайт данных. Сотни краулов, работающих каждый день одновременно. За этими цифрами стоит вопрос, который задаёт себе каждый, кто профессионально работает с ве…
Покупка истёкшего домена с историей это один из самых эффективных способов запустить новый проект с уже существующим ссылочным профилем, трастом и даже трафиком. Вместо того чтобы продвигать голый дом…
Когда речь заходит о восстановлении сайтов из архивов, почти все думают только о Wayback Machine. Это понятно: archive.org на слуху, у него удобный интерфейс, триллион сохранённых страниц. Но Wayback …
Мы выпустили браузерное расширение Archivarix Cache Viewer. Оно доступно сразу для трёх браузеров: Chrome, Edge и Firefox. Расширение бесплатное и без какой-либо рекламы.
Суть простая: быстрый доступ…
Когда вы восстанавливаете сайт из Web Archive, вы ожидаете получить оригинальный контент, который когда-то был написан живыми людьми. Но если архивы сайта были сделаны после 2023 года, есть реальный ш…
В октябре 2025 года Wayback Machine достиг отметки в один триллион сохранённых веб-страниц. Более 100 000 терабайт данных. Это огромное достижение для некоммерческой организации, которая работает с 19…