¿Cómo funciona Archivarix?
El sistema Archivarix está diseñado para descargar y restaurar sitios a los que ya no se puede acceder desde Web Archive y aquellos que están actualmente en línea. Esta es la principal diferencia del resto de "descargadores" y "analizadores de sitios". El objetivo de Archivarix no es solo descargar, sino también restaurar el sitio web de forma que esté accesible en su servidor.
Comencemos con el módulo que descarga sitios web de Web Archive. Estos son servidores virtuales ubicados en California. Su ubicación se eligió de tal manera que se obtuviera la máxima velocidad de conexión posible con el propio Archivo Web, porque sus servidores están ubicados en San Francisco. Después de ingresar datos en el campo apropiado en la página del módulo https://es.archivarix.com/restore/, toma una captura de pantalla del sitio web archivado y se dirige a la API de Web Archive para solicitar una lista de archivos contenidos en la fecha de recuperación especificada .
Después de recibir una respuesta a la solicitud, el sistema genera un mensaje con el análisis de los datos recibidos. El usuario solo necesita presionar el botón de confirmación en el mensaje recibido para comenzar a descargar el sitio web.
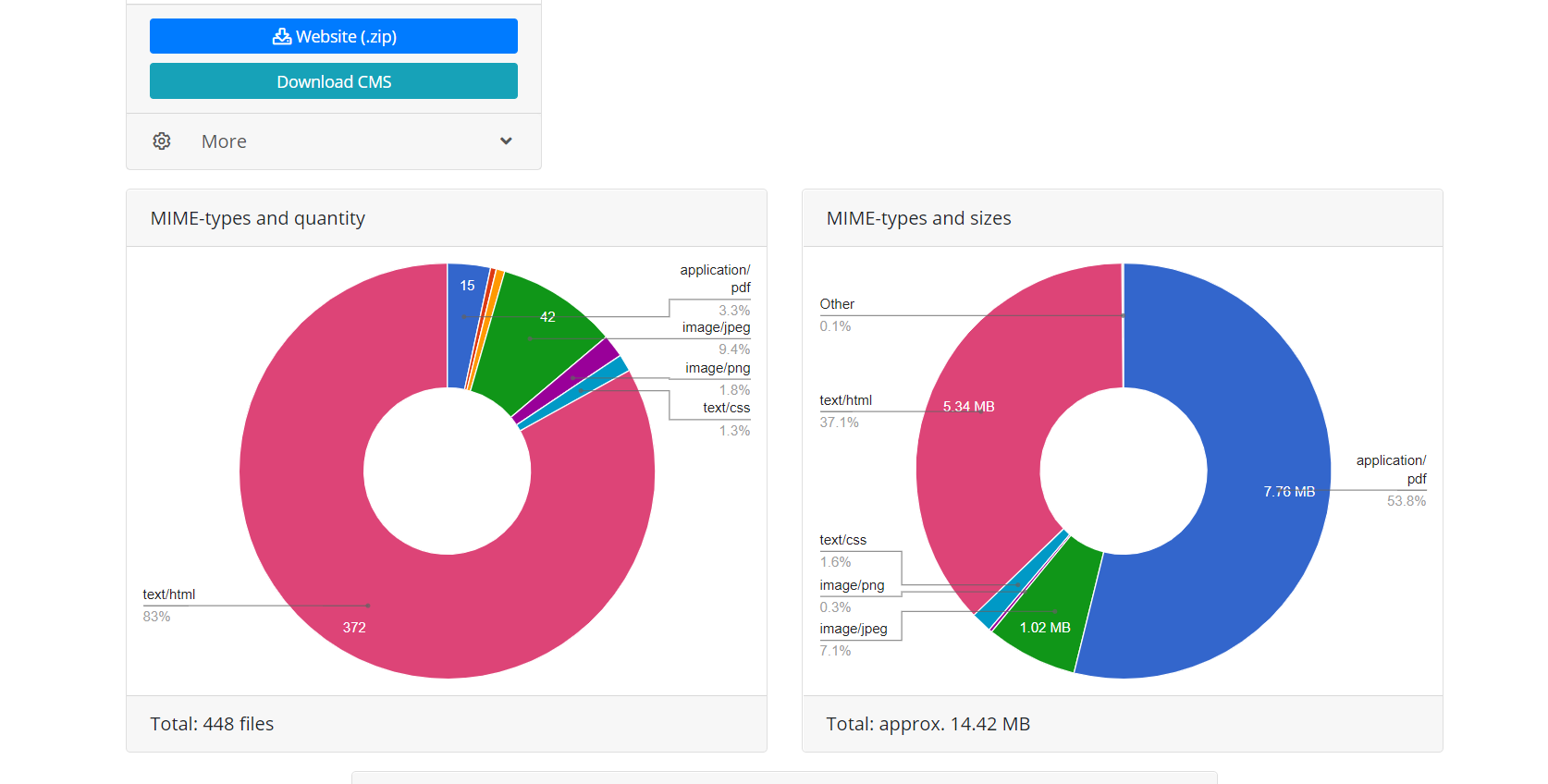
El uso de Web Archive API ofrece dos ventajas sobre la descarga directa cuando el script simplemente sigue los enlaces del sitio web. Primero, todos los archivos de esta recuperación se conocen de inmediato, puede estimar el volumen del sitio web y el tiempo requerido para descargarlo. Debido a la naturaleza de la operación de Web Archive, a veces funciona de manera muy inestable, por lo que es posible que se interrumpa la conexión o que se descarguen archivos de manera incompleta, por lo tanto, el algoritmo del módulo verifica constantemente la integridad de los archivos recibidos y, en tales casos, intenta descargar el contenido volviendo a conectarse a El servidor Web Archive. En segundo lugar, debido a las peculiaridades de la indexación de sitios web por Web Archive, no todos los archivos de sitios web pueden tener enlaces directos, lo que significa que cuando intente descargar un sitio web simplemente siguiendo los enlaces, no estarán disponibles. Por lo tanto, la restauración a través de la API de Archivo Web utilizada por Archivarix, permite restaurar la cantidad máxima posible de contenido archivado del sitio web para una fecha específica.
Después de completar la operación, el módulo de descarga del Archivo Web transfiere datos al módulo de procesamiento. Forma un sitio web a partir de los archivos recibidos adecuados para la instalación en el servidor Apache o Nginx. El funcionamiento del sitio web se basa en la base de datos SQLite, por lo que para comenzar solo necesita cargarlo en su servidor, y no se requiere la instalación de módulos adicionales, bases de datos MySQL y creación de usuarios. El módulo de procesamiento optimiza el sitio web creado; incluye optimización de imagen, así como compresión CSS y JS. Puede aumentar significativamente la velocidad de descarga del sitio web restaurado, si se compara con el sitio web original. La velocidad de descarga de algunos sitios de Wordpress no optimizados con un montón de complementos y archivos multimedia sin comprimir puede aumentar significativamente después del procesamiento por este módulo. Es obvio que si el sitio web se optimizó inicialmente, esto no dará un gran aumento en la velocidad de descarga.
El módulo de procesamiento elimina la publicidad, los contadores y los análisis al verificar los archivos recibidos en una amplia base de datos de proveedores de publicidad y análisis. La eliminación de enlaces externos y contactos en los que se puede hacer clic se realiza simplemente mediante un código de suma de verificación. En general, este algoritmo realiza una limpieza bastante eficiente del sitio web de "rastros del propietario anterior", aunque a veces esto no excluye la necesidad de corregir algo manualmente. Por ejemplo, el algoritmo no eliminará una secuencia de comandos Java autoescrita que redirija al usuario del sitio web a un determinado sitio web de monetización. A veces necesita agregar imágenes faltantes o eliminar residuos innecesarios, como un libro de visitas con correo no deseado. Por lo tanto, es necesario contratar a un editor del sitio web resultante. Y ya existe. Su nombre es Archivarix CMS.
Este es un CMS simple y compacto diseñado para editar sitios web creados por el sistema Archivarix. Permite buscar y reemplazar código en todo el sitio web utilizando expresiones regulares, editando el contenido en el editor WYSIWYG, agregando nuevas páginas y archivos. Archivarix CMS se puede usar junto con cualquier otro CMS en un sitio web.
Ahora hablemos sobre otro módulo utilizado para descargar sitios web existentes. A diferencia del módulo para descargar sitios web desde el Archivo Web, es imposible predecir cuántos y qué archivos necesita descargar, por lo que los servidores del módulo funcionan de una manera completamente diferente. La araña del servidor simplemente sigue todos los enlaces que están presentes en un sitio web que va a descargar. Para que el script no caiga en el ciclo de descarga sin fin de cualquier página generada automáticamente, la profundidad máxima del enlace se limita a diez clics. Y la cantidad máxima de archivos que se pueden descargar del sitio web debe especificarse con anticipación.
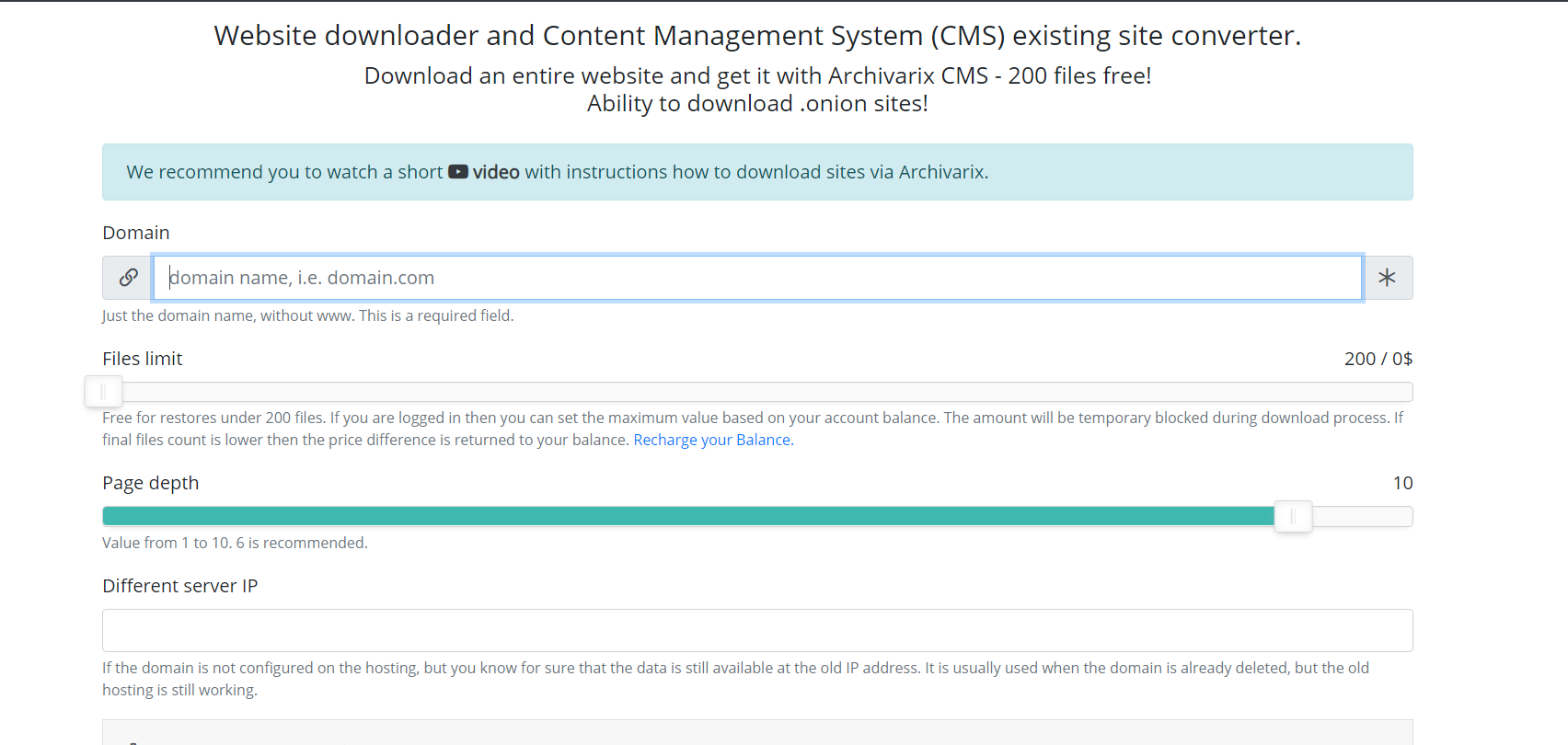
Para la descarga más completa del contenido que necesita, hay varias características que se han inventado en este módulo. Puede seleccionar una araña de servicio de User-Agent diferente, por ejemplo, Chrome Desktop o Googlebot. Referente para omisión de encubrimiento: si necesita descargar exactamente lo que ve el usuario cuando inicia sesión desde la búsqueda, puede instalar un Google, Yandex u otro sitio web de referencia. Para protegerse contra la prohibición por IP, puede optar por descargar el sitio web utilizando la red Tor, mientras que la IP de la araña de servicio cambia aleatoriamente dentro de esta red. Otros parámetros, como la optimización de imágenes, la eliminación de anuncios y el análisis, son similares a los parámetros del módulo de descarga del Archivo web.
Una vez completada la descarga, el contenido se transfiere al módulo de procesamiento. Sus principios de operación son completamente similares a la operación con el sitio web descargado del Archivo Web descrito anteriormente.
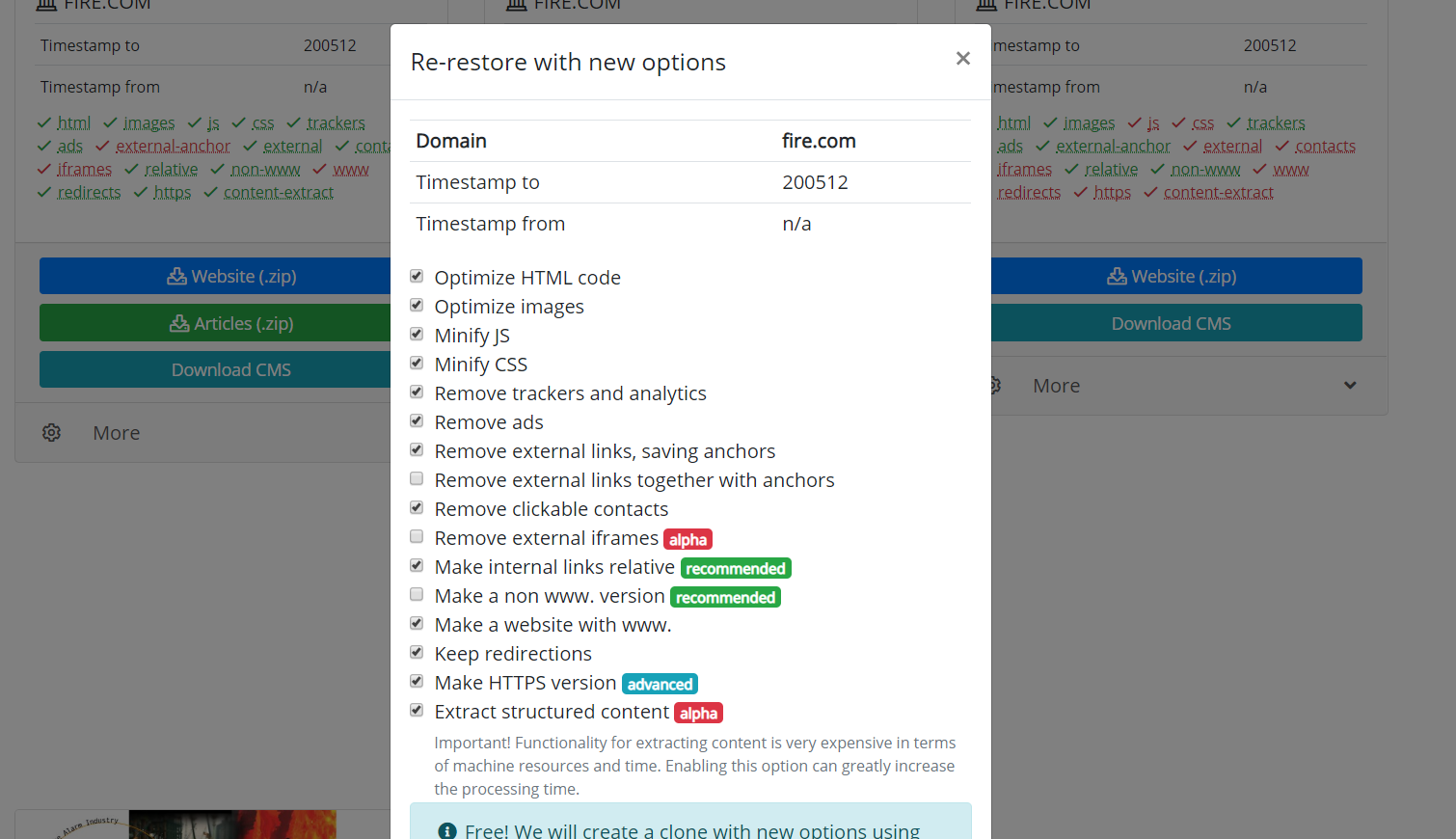
También vale la pena mencionar la posibilidad de clonar sitios web restaurados o descargados. A veces sucede que durante la recuperación, uno ha elegido otros parámetros que resultaron necesarios al final. Por ejemplo, eliminar enlaces externos era innecesario, y algunos enlaces externos que necesitabas, entonces no necesitas comenzar a descargar nuevamente. Solo necesita establecer nuevos parámetros en la página de recuperación y comenzar a recrear el sitio.
El uso de materiales de artículos está permitido solo si se publica el enlace a la fuente: https://archivarix.com/es/blog/how-does-it-works/

El sistema Archivarix está diseñado para descargar y restaurar sitios a los que ya no se puede acceder desde Web Archive y aquellos que están actualmente en línea. Esta es la principal diferencia del …
Al usar la opción "Extraer contenido estructurado", puede crear fácilmente un blog de Wordpress tanto desde el sitio que se encuentra en el Archivo Web como desde cualquier otro sitio. Para hacer esto…
Para que le resulte más cómodo editar los sitios web restaurados en nuestro sistema, hemos desarrollado un CMS de archivo plano simple que consta de un solo archivo php pequeño. A pesar de su tamaño, …
Este artículo describe expresiones regulares usadas para buscar y reemplazar contenido en sitios web restaurados usando el Sistema Archivarix. No son exclusivos de este sistema. Si conoce las expresio…