Archivarix如何工作?
Archivarix系统旨在下载和还原不再可从Web存档访问的站点以及当前在线的站点。这是与其余“下载器”和“站点解析器”的主要区别。 Archivarix的目标不仅是下载,而且还以一种可在您的服务器上访问的形式恢复网站。
让我们从从Web Archive下载网站的模块开始。这些是位于加利福尼亚的虚拟服务器。选择它们的位置是为了获得与Web存档本身最大的连接速度,因为它的服务器位于旧金山。在模块页面https://zh.archivarix.com/restore/上的相应字段中输入数据后,它将获取已存档网站的屏幕快照,并访问Web Archive API以请求指定恢复日期包含的文件列表。
收到对请求的响应后,系统会生成一条消息,其中包含对接收到的数据的分析。用户只需要按收到消息中的确认按钮即可开始下载网站。
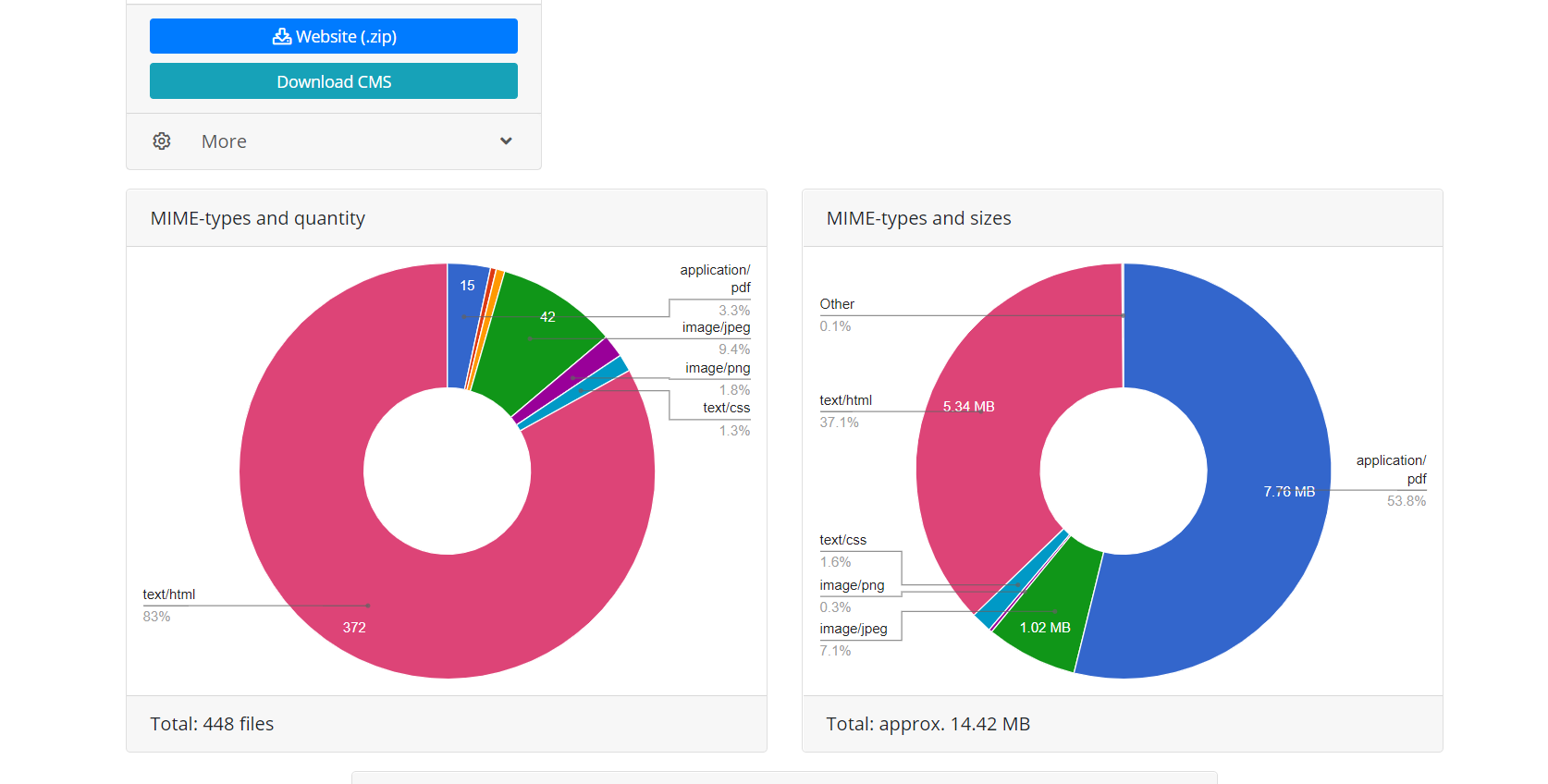
当脚本仅跟随网站的链接时,与直接下载相比,使用Web Archive API有两个优点。首先,此恢复的所有文件都是立即已知的,您可以估计网站的数量以及下载它所需的时间。由于Web存档操作的性质,有时它的工作非常不稳定,因此可能会导致连接中断或文件下载不完整,因此模块算法会不断检查接收到的文件的完整性,在这种情况下,尝试通过重新连接来下载内容Web存档服务器。其次,由于Web存档对网站建立索引的特殊性,并非所有网站文件都可能具有直接链接,这意味着当您仅通过单击链接尝试下载网站时,它们将不可用。因此,通过Archivarix使用的Web存档API进行还原,可以在指定日期还原最大数量的存档网站内容。
完成该操作后,Web存档的下载模块会将数据传输到处理模块。它由接收到的文件组成一个网站,适合在Apache或Nginx服务器上安装。网站的操作基于SQLite数据库,因此,只需将其上载到服务器即可上手,而无需安装其他模块,MySQL数据库和创建用户。处理模块优化创建的网站;它包括图像优化以及CSS和JS压缩。如果与原始网站相比,它可以显着提高已还原网站的下载速度。使用此模块处理后,一些带有插件和未压缩媒体文件的未优化Wordpress网站的下载速度可能会大大提高。显而易见的是,如果最初对网站进行了优化,则下载速度不会大大提高。
处理模块通过对照广泛的广告和分析提供商数据库检查接收到的文件来删除广告,计数器和分析。删除外部链接和可点击的联系人只需通过校验和代码即可。通常,此算法可以非常有效地清除网站上的“先前所有者的痕迹”,尽管有时这并不排除需要手动更正某些内容的麻烦。例如,该算法不会删除将网站用户重定向到某个获利网站的自写Java脚本。有时,您需要添加丢失的图片或删除不必要的残留物,作为垃圾邮件。因此,需要聘请最终网站的编辑。它已经存在。它的名字叫Archivarix CMS。
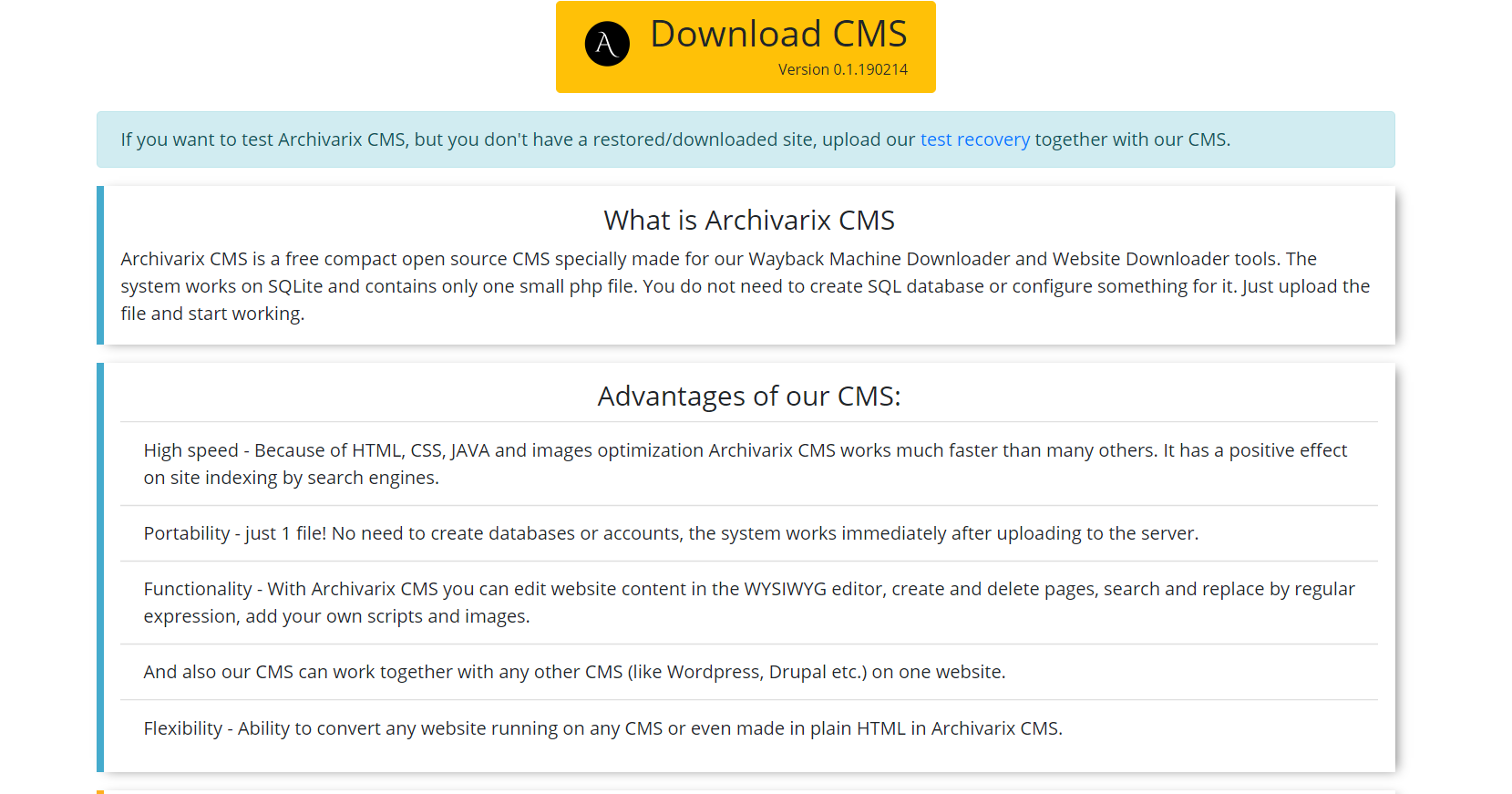
这是一个简单紧凑的CMS,旨在编辑由Archivarix系统创建的网站。它使您可以使用正则表达式在整个网站中搜索和替换代码,在“所见即所得”编辑器中编辑内容,添加新页面和文件。 Archivarix CMS可以与一个网站上的任何其他CMS一起使用。
现在,我们来谈谈用于下载现有网站的其他模块。与从Web存档下载网站的模块不同,无法预测需要下载多少文件以及哪些文件,因此该模块的服务器以完全不同的方式工作。 Server Spider只需遵循您将要下载的网站上存在的所有链接。为了使脚本不会陷入任何自动生成页面的无休止的下载周期,最大链接深度限制为十次单击。并且必须预先指定可从网站下载的最大文件数。
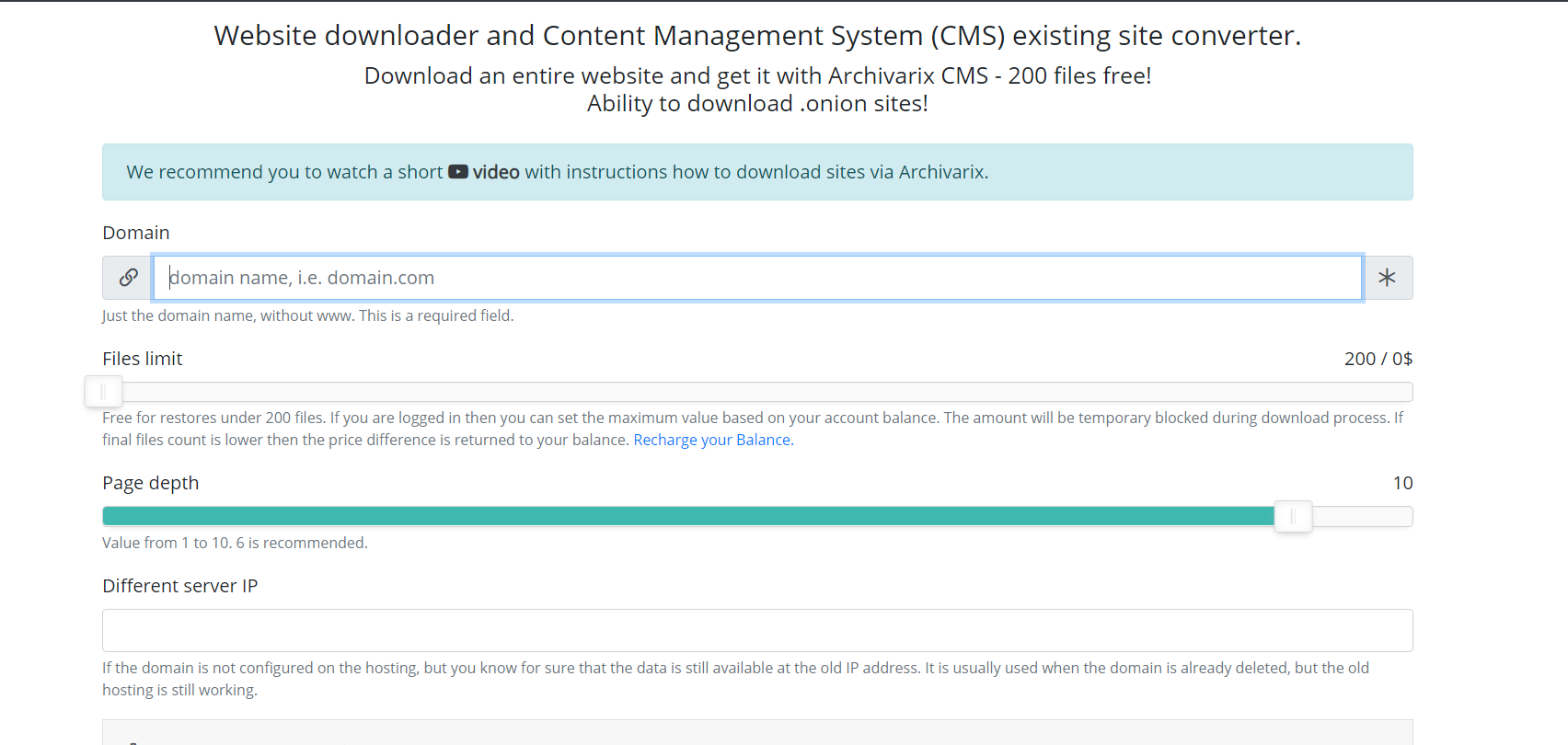
为了最完整地下载所需的内容,此模块中发明了几种功能。您可以选择其他User-Agent服务蜘蛛,例如Chrome桌面或Googlebot。隐藏引人注意的引荐来源网址–如果您需要完全下载用户从搜索登录时看到的内容,则可以安装Google,Yandex或其他网站引荐来源网址。为了防止被IP禁止,您可以选择使用Tor网络下载网站,而服务蜘蛛的IP在该网络中会随机变化。其他参数,例如图像优化,广告删除和分析,与从Web存档下载模块的参数相似。
下载完成后,内容将传输到处理模块。其操作原理与上述从Web存档下载网站的操作完全相似。
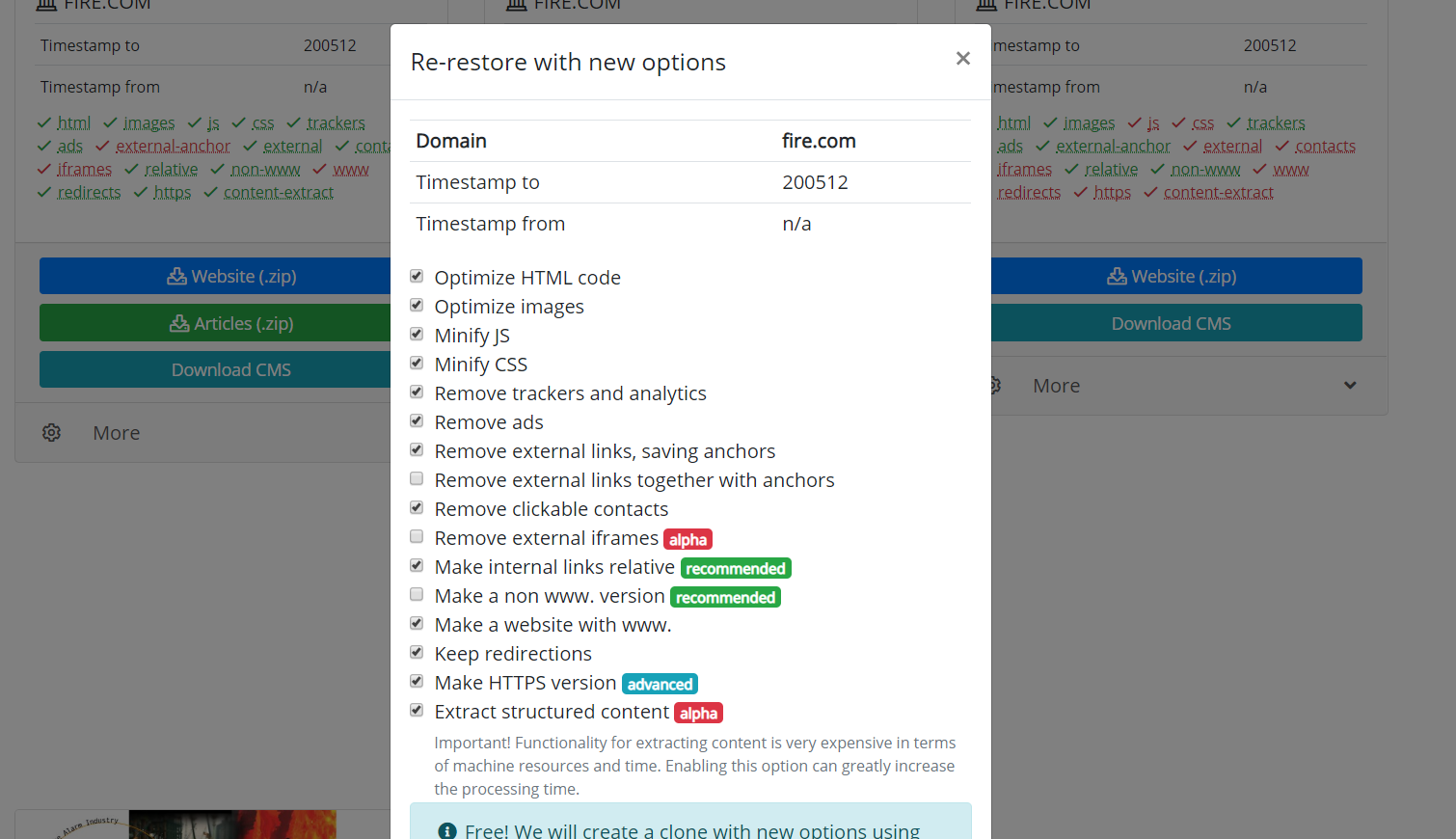
还值得一提的是,克隆恢复或下载的网站的可能性。有时,在恢复过程中可能会选择其他参数,但最终并没有必要。例如,不需要外部链接,而您需要一些外部链接,那么就无需再次开始下载。您只需要在恢复页面上设置新参数并开始重新创建站点。
仅在发布到来源的链接时,才允许使用文章材料: https://archivarix.com/zh/blog/how-does-it-works/

Archivarix系统旨在下载和还原不再可从Web存档访问的站点以及当前在线的站点。这是与其余“下载器”和“站点解析器”的主要区别。 Archivarix的目标不仅是下载,而且还以一种可在您的服务器上访问的形式恢复网站。
让我们从从Web Archive下载网站的模块开始。这些是位于加利福尼亚的虚拟服务器。选择它们的位置是为了获得与Web存档本身最大的连接速度,因为它的服务器位于旧金山。在…
通过使用“提取结构化内容”选项,您可以轻松地从Web存档上的站点和任何其他站点创建Wordpress博客。为此,首先找到源站点,然后在“还原网站”或“下载网站”工具中选中“提取结构化内容”选项。输入您的选项(电子邮件,时间戳等),然后开始下载。…
为了方便您编辑在我们系统中还原的网站,我们开发了一个仅包含一个小php文件的简单平面文件CMS。 尽管尺寸庞大,但此CMS是用于处理您的网站的功能强大且用途广泛的工具。 它提供了任何CMS的所有基本功能,以及网站管理员根据从Web存档还原的内容创建PBN的特殊功能。…
本文介绍了用于搜索和替换使用Archivarix System还原的网站中的内容的正则表达式。 它们不是该系统独有的。 如果您知道PHP,Perl,Java或其他编程语言的正则表达式,那么您已经知道如何使用我们的搜索和替换。 如果没有,我们希望本文对您有所帮助。…