Jak działa Archivarix?
System Archivarix został zaprojektowany do pobierania i przywracania witryn, które nie są już dostępne z Archive.org oraz tych, które są obecnie online. Jest to główna różnica w stosunku do reszty „downloaderów” i „parserów witryn”. Celem Archivarix jest nie tylko pobranie, ale także przywrócenie strony internetowej w formie, która będzie dostępna na twoim serwerze.
Zacznijmy od modułu, który pobiera strony internetowe z archiwum internetowego. Są to serwery wirtualne zlokalizowane w Kalifornii. Ich lokalizację wybrano w taki sposób, aby uzyskać maksymalną możliwą prędkość połączenia z samym archiwum internetowym, ponieważ jego serwery znajdują się w San Francisco. Po wprowadzeniu danych w odpowiednim polu na stronie modułu https://pl.archivarix.com/restore/, wykonuje zrzut ekranu zarchiwizowanej witryny i zwraca się do interfejsu API Web Archive, aby poprosić o listę plików zawartych w określonym terminie odzyskiwania .
Po otrzymaniu odpowiedzi na żądanie system generuje komunikat z analizą odebranych danych. Użytkownik musi tylko nacisnąć przycisk potwierdzenia w otrzymanej wiadomości, aby rozpocząć pobieranie strony internetowej.
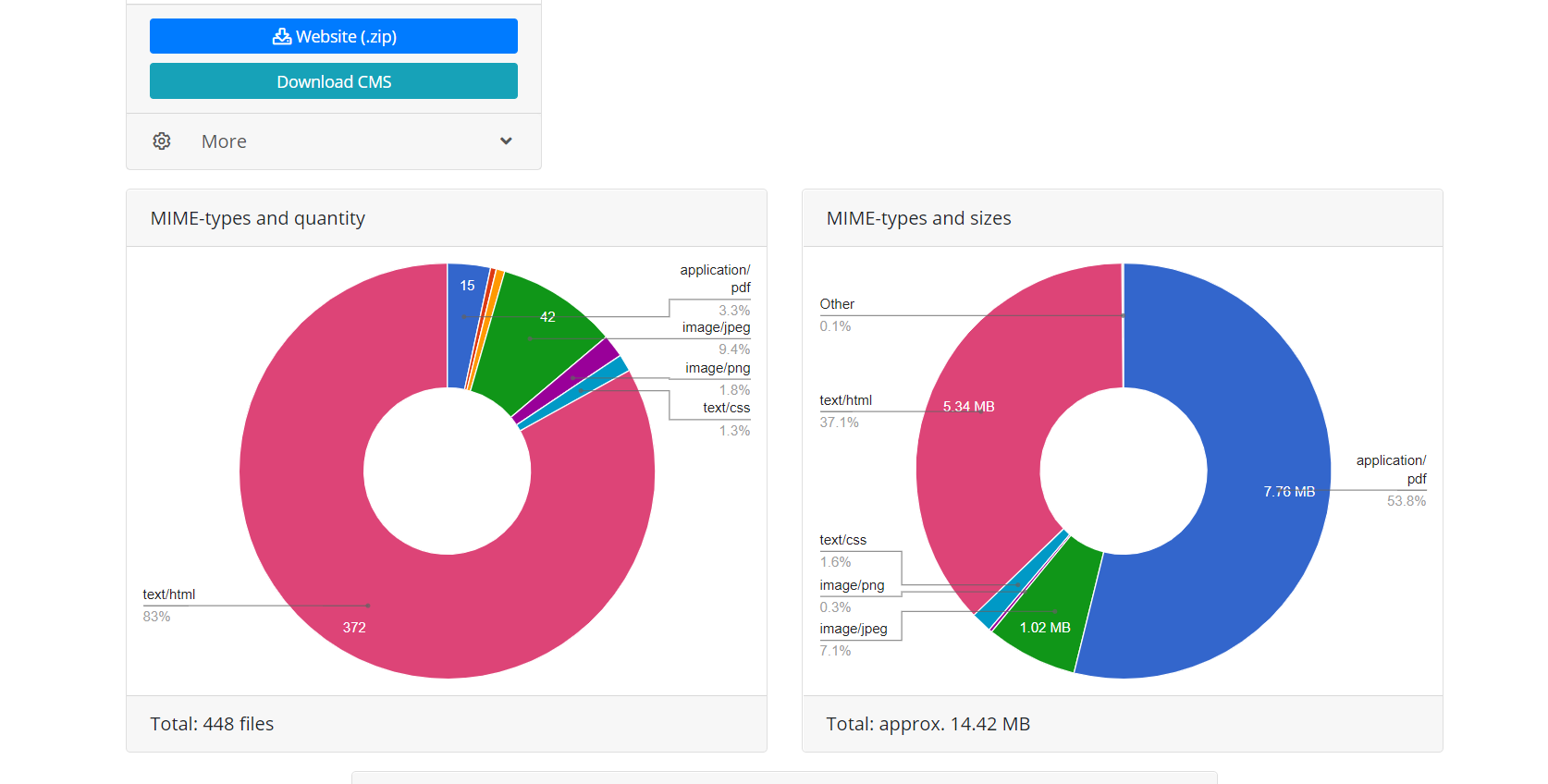
Korzystanie z interfejsu API Web Archive zapewnia dwie zalety w stosunku do bezpośredniego pobierania, gdy skrypt po prostu podąża za linkami witryny. Po pierwsze, wszystkie pliki tego odzyskiwania są natychmiast znane, możesz oszacować wielkość witryny i czas potrzebny do jej pobrania. Ze względu na charakter działania archiwum internetowego czasami działa on bardzo niestabilnie, dlatego możliwe jest zrywanie połączenia lub niekompletne pobieranie plików, dlatego algorytm modułu stale sprawdza integralność otrzymanych plików iw takich przypadkach próbuje pobrać zawartość, ponownie łącząc się z serwer archiwum internetowego. Po drugie, ze względu na specyfikę indeksowania stron internetowych przez Archiwum WWW, nie wszystkie pliki stron internetowych mogą mieć bezpośrednie linki, co oznacza, że gdy spróbujesz pobrać stronę internetową, po prostu podążając za linkami, będą one niedostępne. Dlatego przywracanie za pomocą interfejsu API archiwum internetowego używanego przez Archivarix umożliwia przywrócenie maksymalnej możliwej ilości zarchiwizowanej zawartości strony internetowej dla określonej daty.
Po zakończeniu operacji moduł pobierania z Archiwum internetowego przesyła dane do modułu przetwarzania. Z otrzymanych plików tworzy stronę internetową odpowiednią do instalacji na serwerze Apache lub Nginx. Witryna działa w oparciu o bazę danych SQLite, więc aby rozpocząć, wystarczy przesłać ją na serwer i nie jest wymagana instalacja dodatkowych modułów, baz danych MySQL i tworzenie użytkowników. Moduł przetwarzania optymalizuje utworzoną stronę internetową; obejmuje optymalizację obrazu, a także kompresję CSS i JS. Może to znacznie przyspieszyć pobieranie przywróconej witryny, w porównaniu do oryginalnej witryny. Szybkość pobierania niektórych niezoptymalizowanych stron Wordpress z wieloma wtyczkami i nieskompresowanymi plikami multimedialnymi może znacznie wzrosnąć po przetworzeniu przez ten moduł. Oczywiste jest, że jeśli strona została wstępnie zoptymalizowana, nie spowoduje to znacznego wzrostu prędkości pobierania.
Moduł przetwarzania usuwa reklamy, liczniki i analizy, sprawdzając otrzymane pliki w obszernej bazie danych dostawców reklam i analiz. Usuwanie zewnętrznych linków i klikalnych kontaktów odbywa się po prostu za pomocą kodu sumy kontrolnej. Ogólnie rzecz biorąc, ten algorytm wykonuje dość wydajne czyszczenie strony internetowej z „śladów poprzedniego właściciela”, chociaż czasami nie wyklucza to potrzeby ręcznej korekty. Na przykład samodzielnie napisany skrypt Java przekierowujący użytkownika witryny do określonej witryny generującej przychody nie zostanie usunięty przez algorytm. Czasami musisz dodać brakujące zdjęcia lub usunąć niepotrzebne pozostałości, jako spamowaną księgę gości. Dlatego konieczne jest zatrudnienie redaktora powstałej witryny. I już istnieje. Nazywa się Archivarix CMS.
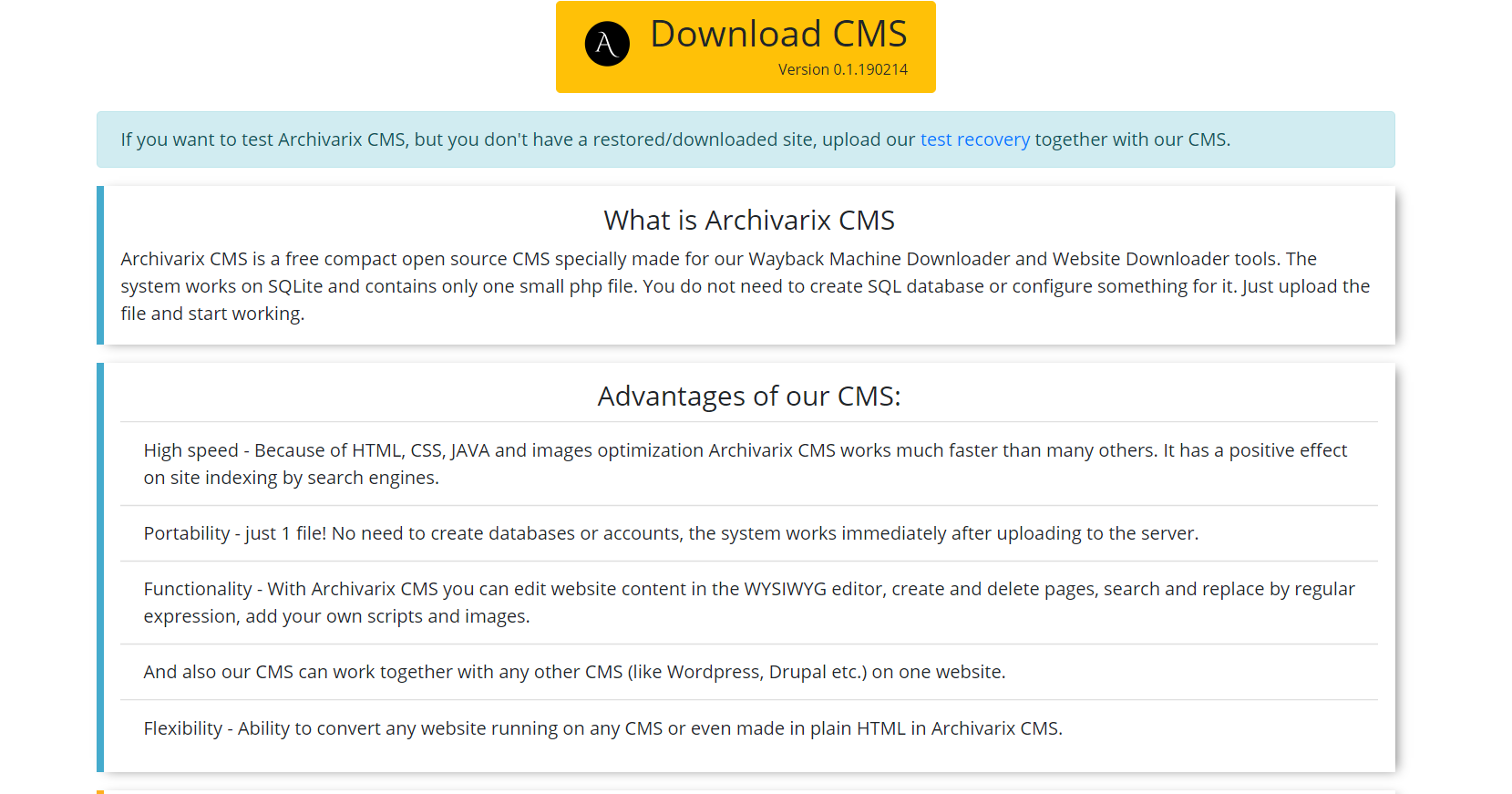
Jest to prosty i kompaktowy CMS przeznaczony do edycji stron internetowych stworzonych przez system Archivarix. Umożliwia wyszukiwanie i zamianę kodu w całej witrynie przy użyciu wyrażeń regularnych, edycję treści w edytorze WYSIWYG, dodawanie nowych stron i plików. Archivarix CMS może być używany razem z dowolnym innym CMS na jednej stronie internetowej.
Porozmawiajmy teraz o innym module używanym do pobierania istniejących witryn. W przeciwieństwie do modułu do pobierania stron internetowych z Archiwum internetowego, nie można przewidzieć, ile i które pliki należy pobrać, więc serwery modułu działają w zupełnie inny sposób. Pająk serwera podąża za wszystkimi linkami, które są obecne na stronie, którą zamierzasz pobrać. Aby skrypt nie wpadał w niekończący się cykl pobierania dowolnej automatycznie generowanej strony, maksymalna głębokość łącza jest ograniczona do dziesięciu kliknięć. A maksymalna liczba plików, które można pobrać ze strony internetowej, musi zostać wcześniej określona.
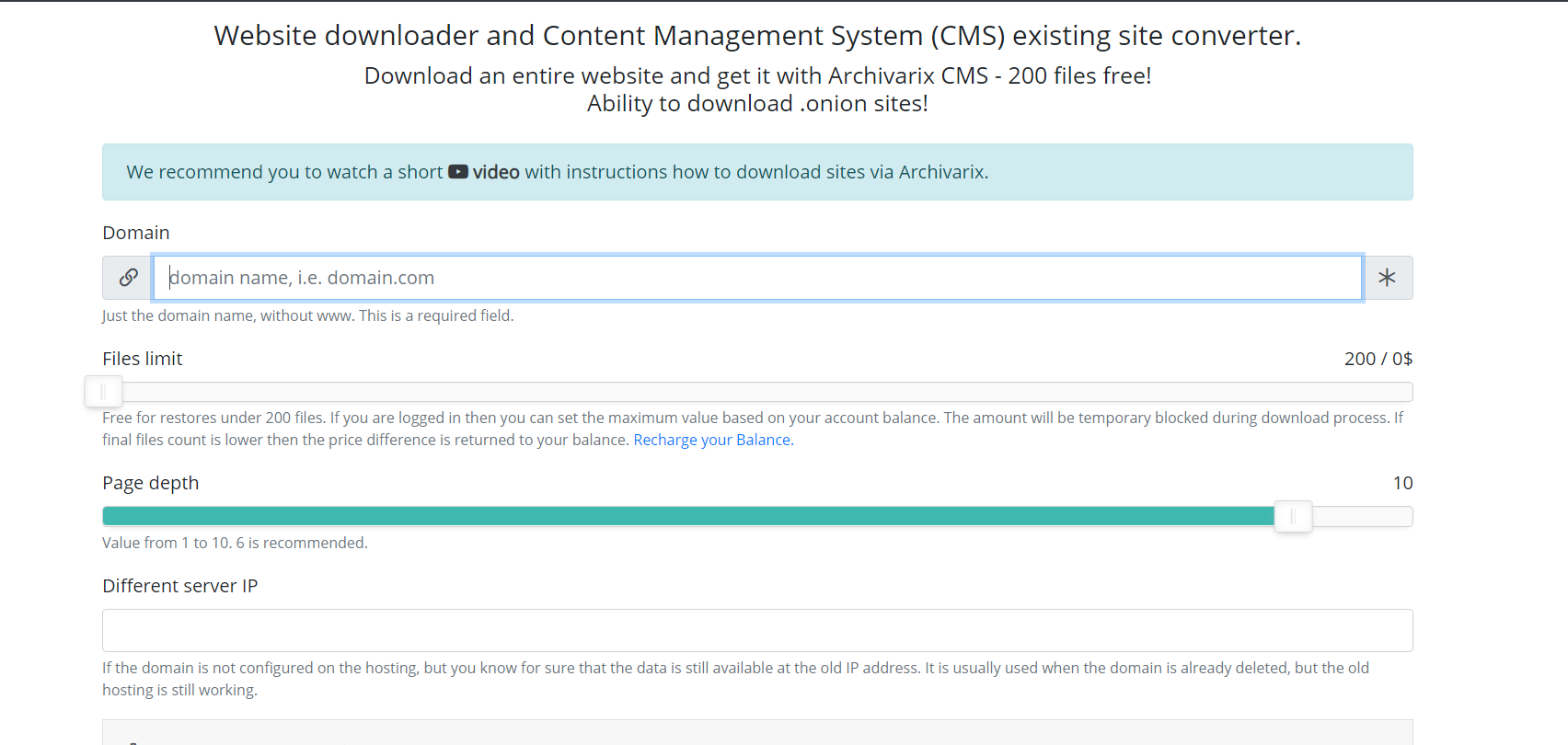
Aby uzyskać najbardziej kompletne pobieranie potrzebnej zawartości, w tym module wymyślono kilka funkcji. Możesz wybrać innego pająka usługi User-Agent, na przykład Chrome Desktop lub Googlebot. Polecający w celu obejścia maskowania - jeśli chcesz pobrać dokładnie to, co widzi użytkownik po zalogowaniu z wyszukiwania, możesz zainstalować Google, Yandex lub inną stronę polecającą. Aby zabezpieczyć się przed banowaniem przez IP, możesz pobrać stronę internetową za pomocą sieci Tor, podczas gdy IP pająka usługi zmienia się losowo w tej sieci. Inne parametry, takie jak optymalizacja obrazu, usuwanie reklam i analizy są podobne do parametrów modułu pobierania z Archiwum internetowego.
Po zakończeniu pobierania zawartość jest przenoszona do modułu przetwarzającego. Jego zasady działania są całkowicie podobne do działania ze stroną pobraną z wyżej opisanego archiwum internetowego.
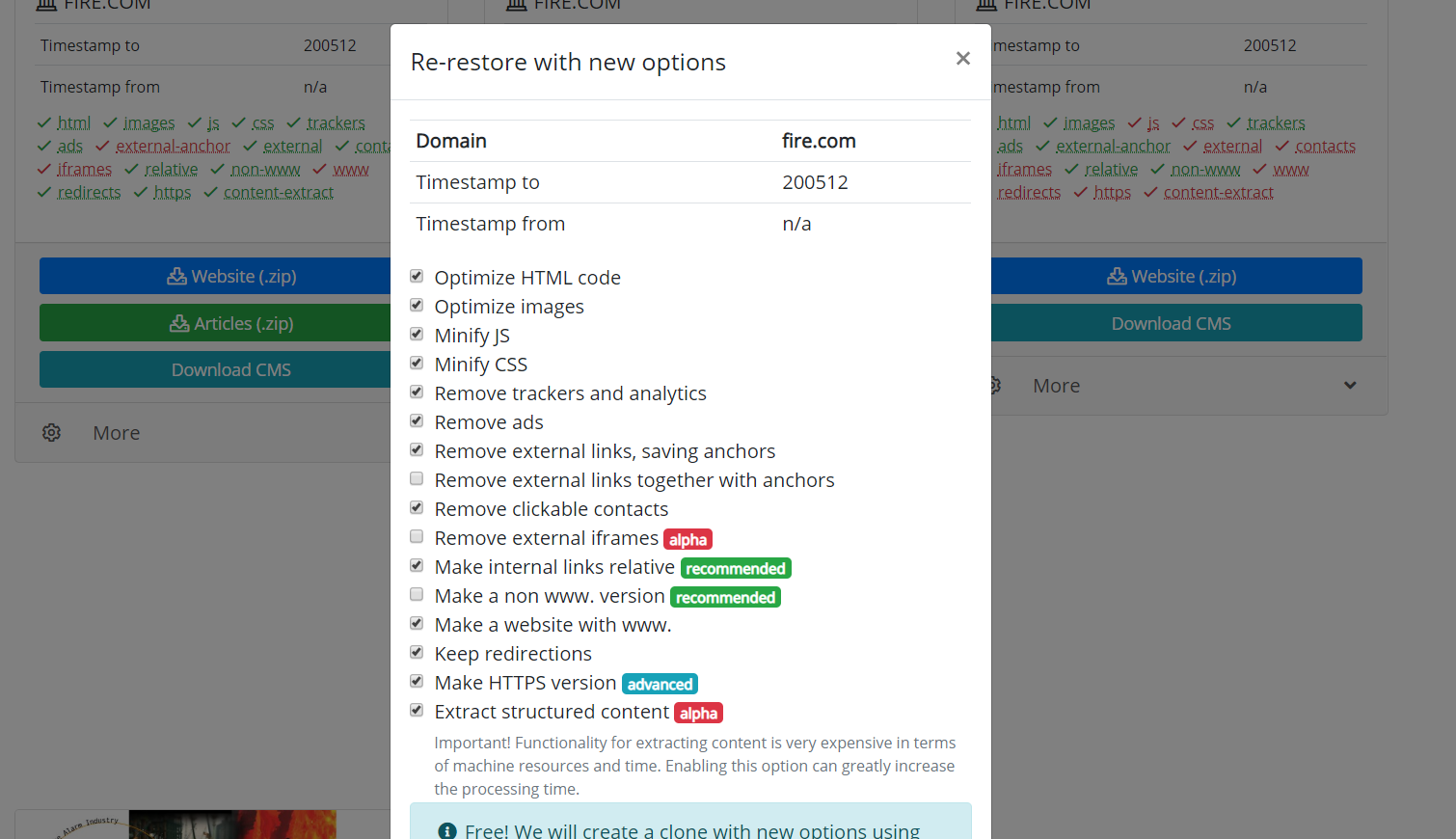
Warto również wspomnieć o możliwości klonowania przywróconych lub pobranych stron internetowych. Czasami zdarza się, że podczas odzyskiwania wybrano inne parametry, niż się okazało na końcu konieczne. Na przykład usunięcie linków zewnętrznych było niepotrzebne, a niektóre linki zewnętrzne były potrzebne, a następnie nie trzeba ponownie zaczynać pobierania. Musisz tylko ustawić nowe parametry na stronie odzyskiwania i rozpocząć ponowne tworzenie witryny.
Wykorzystanie materiałów artykułu jest dozwolone tylko wtedy, gdy opublikowany jest link do źródła: https://archivarix.com/pl/blog/how-does-it-works/

System Archivarix został zaprojektowany do pobierania i przywracania witryn, które nie są już dostępne z Archive.org oraz tych, które są obecnie online. Jest to główna różnica w stosunku do reszty „do…
Korzystając z opcji „Wyciąg z ustrukturyzowanej treści”, możesz łatwo utworzyć blog Wordpress zarówno ze strony znalezionej w archiwum internetowym, jak iz dowolnej innej witryny. Aby to zrobić, najpi…
Aby ułatwić edytowanie stron internetowych przywróconych w naszym systemie, opracowaliśmy prosty system plików Flat File CMS składający się tylko z jednego małego pliku php. Pomimo swoich rozmiarów, t…
W tym artykule opisano wyrażenia regularne używane do wyszukiwania i zastępowania treści na stronach internetowych przywróconych za pomocą systemu Archivarix. Nie są one unikalne dla tego systemu. Jeś…