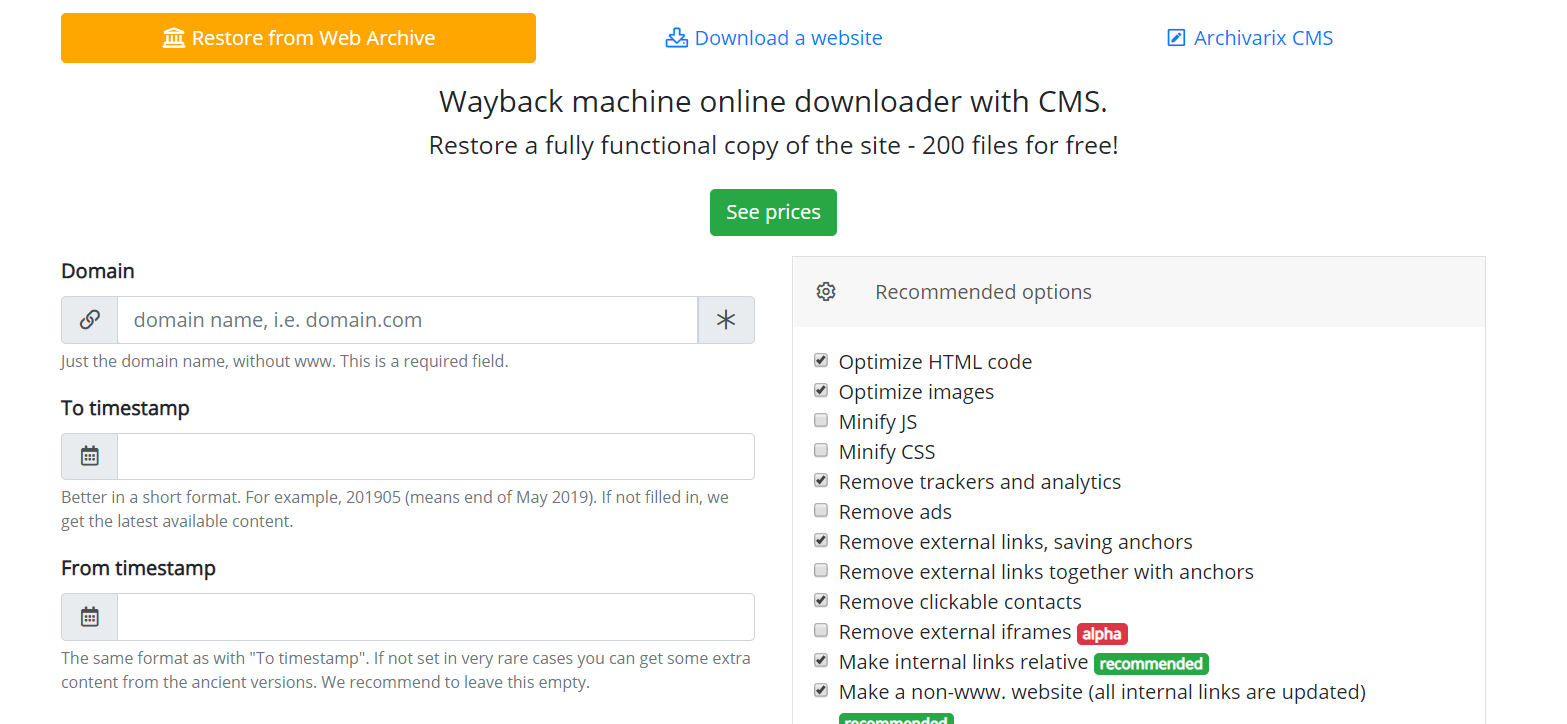
Comment Archivarix agit-il?
Le système Archivarix est conçu pour télécharger et restaurer les sites qui ne sont plus accessibles à partir de Web Archive et ceux qui sont actuellement en ligne. C'est la principale différence avec le reste des «téléchargeurs» et des «analyseurs de site». L'objectif d'Archivarix n'est pas seulement de télécharger, mais également de restaurer le site Web sous une forme qui le rendra accessible sur votre serveur.
Commençons par le module qui télécharge des sites Web à partir de Web Archive. Ce sont des serveurs virtuels situés en Californie. Leur emplacement a été choisi de manière à obtenir la vitesse de connexion maximale possible avec Web Archive elle-même, car ses serveurs sont situés à San Francisco. Une fois les données saisies dans le champ approprié de la page du module https://fr.archivarix.com/restore/, une capture d'écran du site Web archivé et l'adresse de l'API Web Archive pour demander une liste des fichiers contenus à la date de récupération spécifiée.
Ayant reçu une réponse à la demande, le système génère un message avec l'analyse des données reçues. L'utilisateur n'a qu'à appuyer sur le bouton de confirmation dans le message reçu pour commencer à télécharger le site Web.
L'utilisation de l'API Web Archive offre deux avantages par rapport au téléchargement direct lorsque le script suit simplement les liens du site Web. Premièrement, tous les fichiers de cette récupération sont immédiatement connus, vous pouvez estimer le volume du site Web et le temps nécessaire pour le télécharger. En raison de la nature du fonctionnement de l'archive Web, elle fonctionne parfois de manière très instable, de sorte que des interruptions de connexion ou des téléchargements de fichiers incomplets sont possibles. Par conséquent, l'algorithme du module vérifie constamment l'intégrité des fichiers reçus. Dans ce cas, il tente de télécharger le contenu en se reconnectant à le serveur d'archives Web. Deuxièmement, en raison des particularités de l'indexation de sites Web par Web Archive, tous les fichiers de sites Web ne peuvent pas comporter de liens directs. En d'autres termes, lorsque vous essayez de télécharger un site Web simplement en suivant ces liens, ils ne sont pas disponibles. Par conséquent, la restauration via l’API d’archive Web utilisée par Archivarix permet de restaurer le maximum de contenu de site Web archivé pour une date donnée.
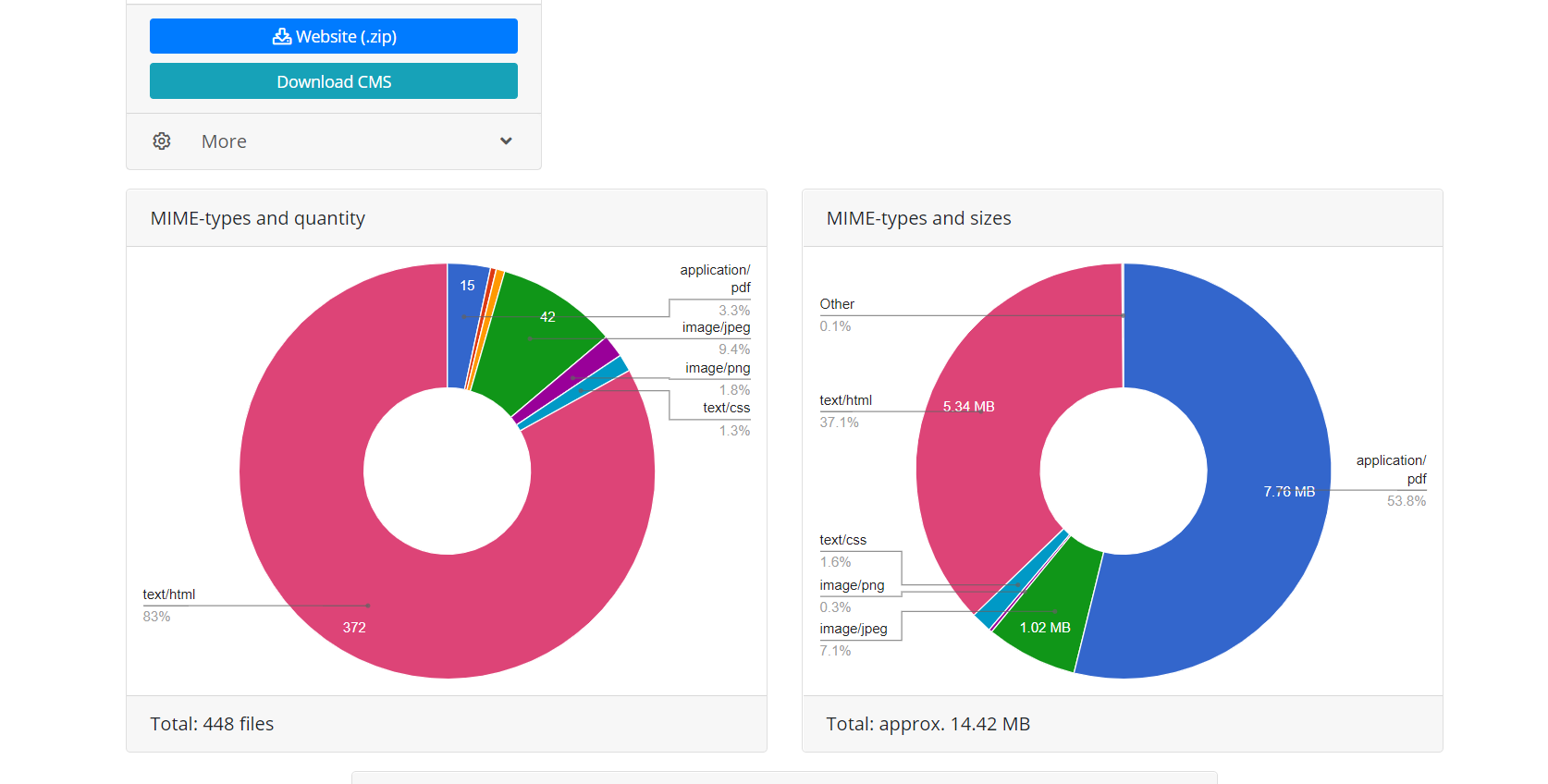
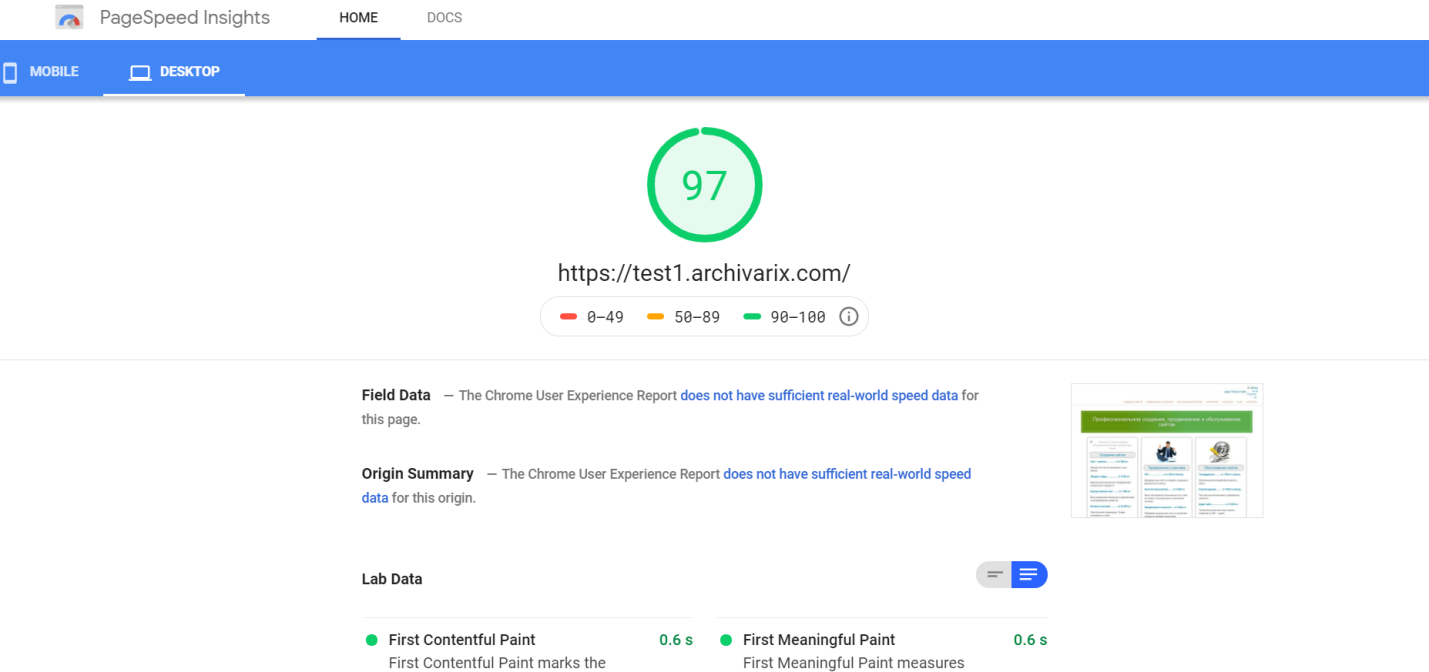
Une fois l'opération terminée, le module de téléchargement de Web Archive transfère les données au module de traitement. Il forme un site Web à partir des fichiers reçus, pouvant être installé sur un serveur Apache ou Nginx. Le fonctionnement du site Web est basé sur la base de données SQLite. Par conséquent, pour commencer, il vous suffit de le télécharger sur votre serveur. Aucune installation de modules supplémentaires, de bases de données MySQL et de création d'utilisateurs n'est requise. Le module de traitement optimise le site Web créé; il comprend l'optimisation de l'image, ainsi que la compression CSS et JS. Cela peut augmenter considérablement la vitesse de téléchargement du site Web restauré, par rapport au site Web d'origine. La vitesse de téléchargement de certains sites Wordpress non optimisés comportant de nombreux plug-ins et des fichiers multimédias non compressés peut être considérablement accrue après traitement par ce module. Il est évident que si le site Web avait été optimisé initialement, cela ne donnerait pas une augmentation importante de la vitesse de téléchargement.
Le module de traitement supprime les publicités, les compteurs et les analyses en comparant les fichiers reçus à une base de données étendue de fournisseurs de publicité et d’analyses. La suppression des liens externes et des contacts cliquables s'effectue simplement par code de contrôle. En général, cet algorithme effectue un nettoyage assez efficace du site Web des «traces du propriétaire précédent», bien que parfois cela n'exclue pas la nécessité de corriger manuellement quelque chose. Par exemple, un script Java auto-écrit redirigeant un utilisateur de site Web vers un certain site Web de monétisation ne sera pas supprimé par l'algorithme. Parfois, vous devez ajouter des images manquantes ou supprimer des résidus inutiles, en tant que livre d'or spammé. Par conséquent, il est nécessaire de recruter un éditeur du site Web résultant. Et ça existe déjà. Son nom est Archivarix CMS.
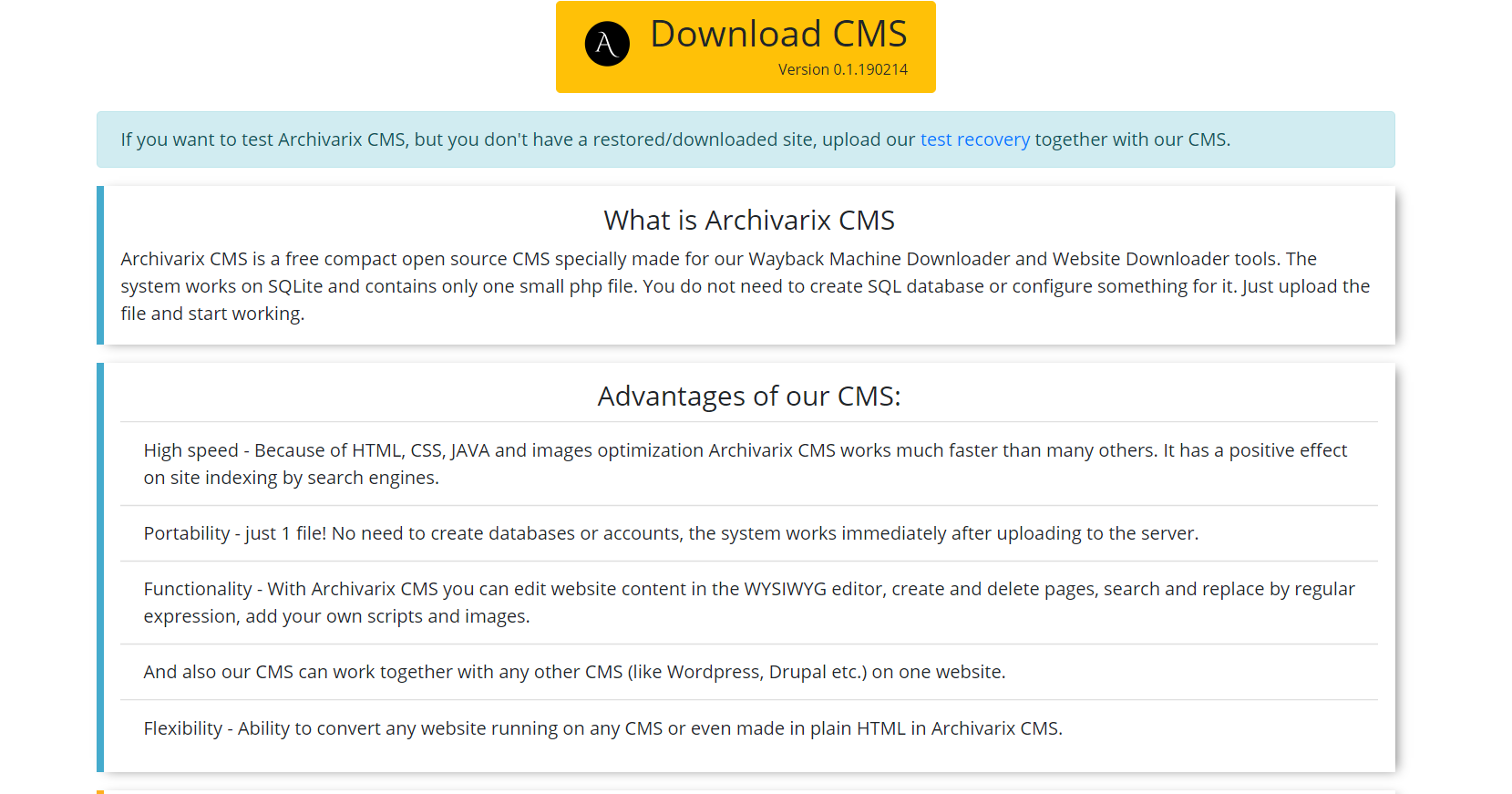
Il s'agit d'un système de gestion de contenu simple et compact conçu pour l'édition de sites Web créés par le système Archivarix. Il permet de rechercher et de remplacer du code sur l'ensemble du site à l'aide d'expressions régulières, d'éditer le contenu dans l'éditeur WYSIWYG, d'ajouter de nouvelles pages et de nouveaux fichiers. Archivarix CMS peut être utilisé avec n'importe quel autre CMS sur un site Web.
Parlons maintenant d’un autre module utilisé pour télécharger des sites Web existants. Contrairement au module de téléchargement de sites Web à partir de l’archive Web, il est impossible de prédire le nombre et le nombre de fichiers à télécharger. Les serveurs du module fonctionnent donc de manière complètement différente. Server Spider suit simplement tous les liens présents sur un site Web que vous allez télécharger. Pour que le script ne tombe pas dans le cycle de téléchargement sans fin d'une page générée automatiquement, la profondeur de lien maximale est limitée à dix clics. Et le nombre maximal de fichiers pouvant être téléchargés à partir du site Web doit être spécifié à l'avance.
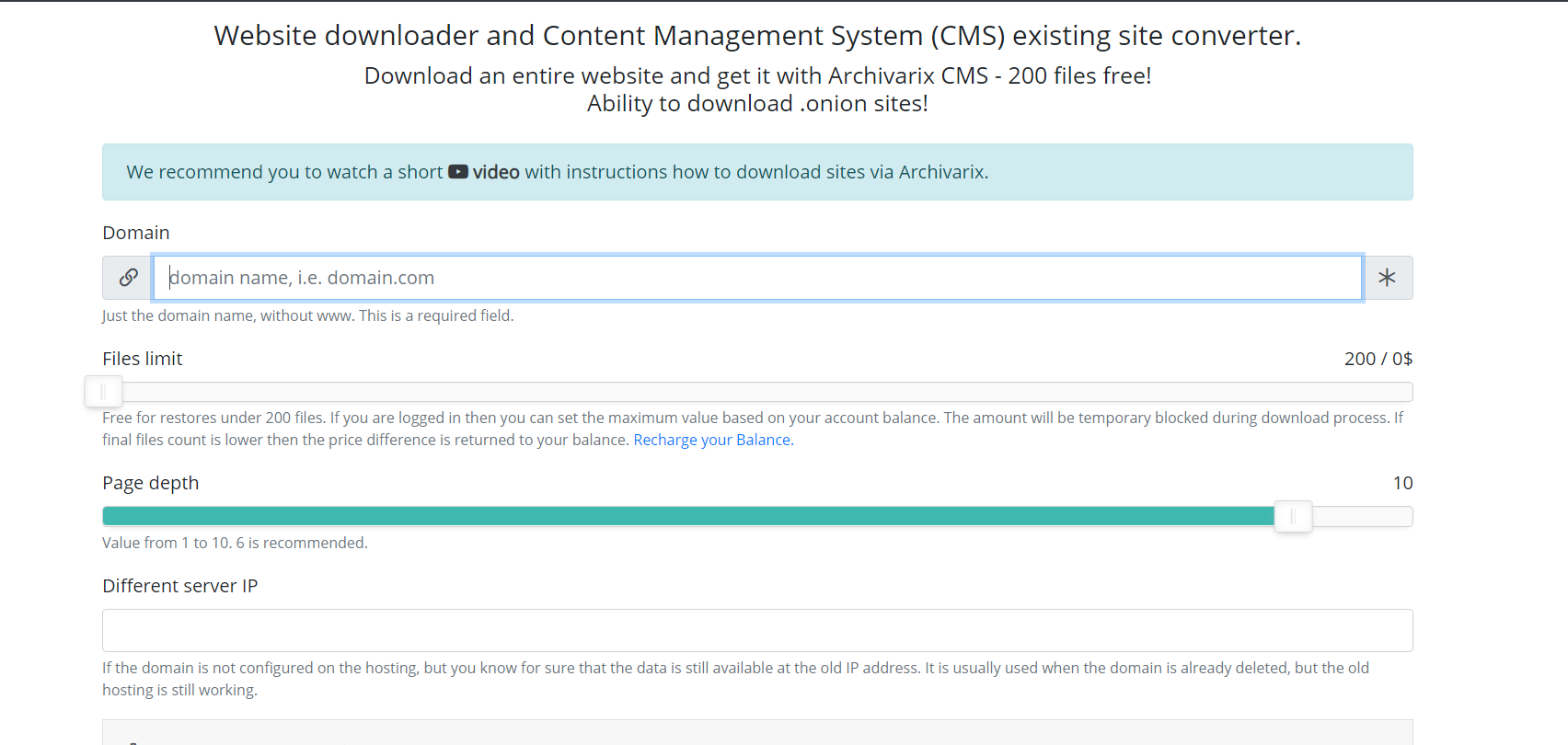
Pour le téléchargement le plus complet possible du contenu dont vous avez besoin, plusieurs fonctionnalités ont été inventées dans ce module. Vous pouvez sélectionner un autre spider de service User-Agent, par exemple, Chrome Desktop ou Googlebot. Referrer for cloaking bypass - si vous devez télécharger exactement ce que l'utilisateur voit lorsqu'il est connecté à partir de la recherche, vous pouvez installer un référent Google, Yandex ou un autre site Web. Pour vous protéger contre les interdictions par IP, vous pouvez choisir de télécharger le site Web à l'aide du réseau Tor, pendant que l'adresse IP de l'araignée de service change de manière aléatoire sur ce réseau. D'autres paramètres, tels que l'optimisation de l'image, la suppression des publicités et les analyses, sont similaires aux paramètres du module de téléchargement à partir de l'archive Web.
Une fois le téléchargement terminé, le contenu est transféré dans le module de traitement. Ses principes de fonctionnement sont complètement similaires à ceux du fonctionnement avec le site Web téléchargé à partir des archives Web décrites ci-dessus.
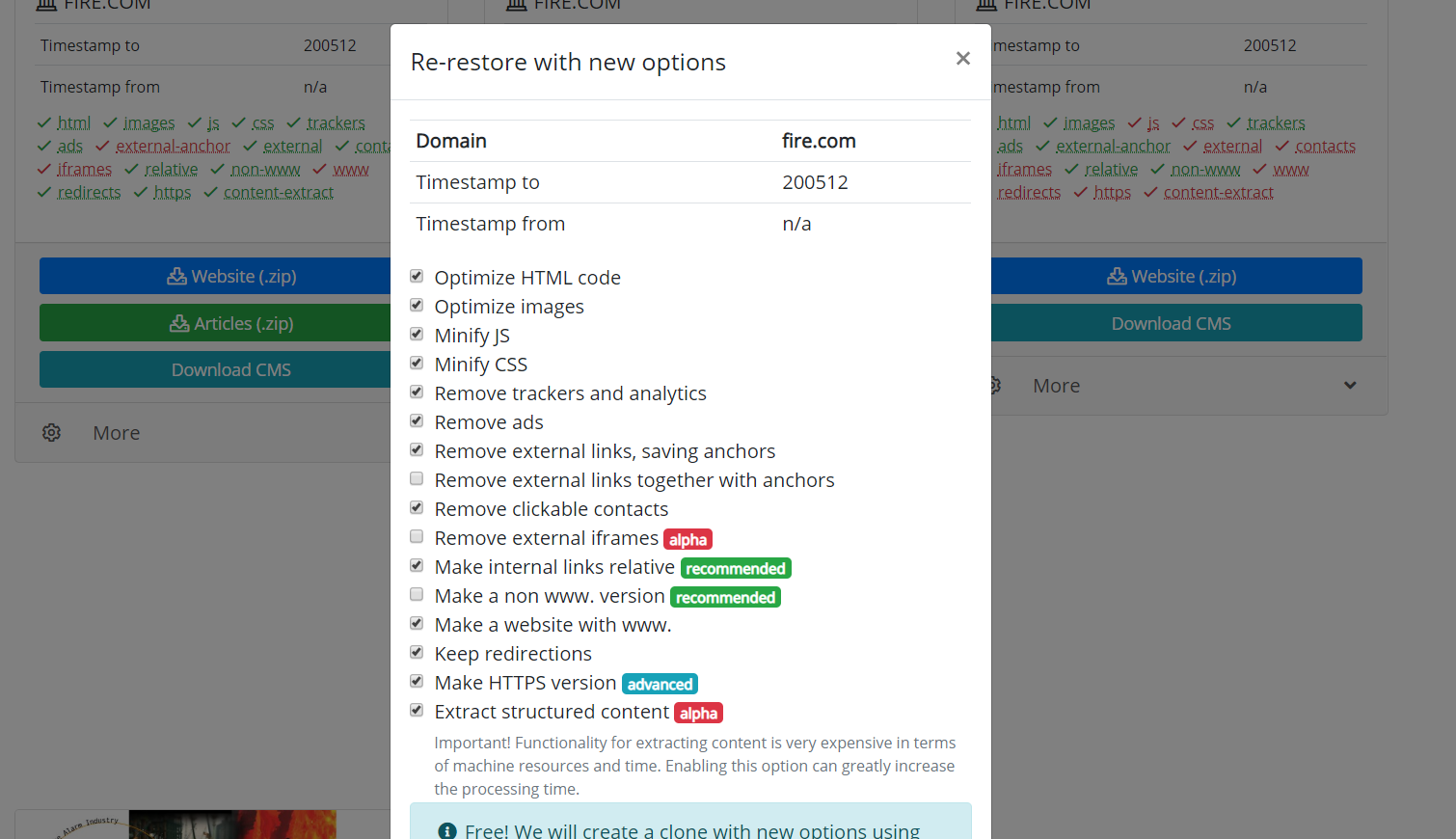
Il convient également de mentionner la possibilité de cloner des sites Web restaurés ou téléchargés. Il arrive parfois que lors de la récupération, on ait choisi d'autres paramètres que ceux qui se sont avérés nécessaires à la fin. Par exemple, il était inutile de supprimer les liens externes et si vous en aviez besoin, vous n'avez pas besoin de recommencer à télécharger. Vous devez simplement définir de nouveaux paramètres sur la page de récupération et commencer à recréer le site.
L'utilisation de matériel d'article n'est autorisée que si le lien vers la source est publié: https://archivarix.com/fr/blog/how-does-it-works/

Le système Archivarix est conçu pour télécharger et restaurer les sites qui ne sont plus accessibles à partir de Web Archive et ceux qui sont actuellement en ligne. C'est la principale différence avec…
En utilisant l'option «Extraire du contenu structuré», vous pouvez facilement créer un blog Wordpress à partir du site présent sur les archives Web et de tout autre site. Pour ce faire, commencez par …
Afin de vous permettre de modifier facilement les sites Web restaurés dans notre système, nous avons développé un CMS de fichier plat simple composé d'un seul petit fichier php. Malgré sa taille, ce C…
Cet article décrit les expressions régulières utilisées pour rechercher et remplacer du contenu dans des sites Web restaurés à l'aide du système Archivarix. Ils ne sont pas uniques à ce système. Si vo…