Как работает Архиварикс?
Система Архиварикс предназначена для скачивания и восстановления сайтов - как уже не работающих из Веб Архива, так и живых, находящихся в данный момент онлайн. В этом заключается ее основное отличие от прочих «качалок» и «парсеров сайтов». Задача Архиварикса - не только скачать, но и восстановить сайт в таком виде, в котором его можно будет использовать в дальнейшем на своем сервере.
Начнем с модуля, ответственного за скачивание сайтов из Веб Архива. Это виртуальные серверы, находящиеся в Калифорнии. Место расположения их было выбрано таким образом, чтобы получить максимально возможную скорость соединения с самим Веб Архивом, сервера которого расположены в Сан-Франциско. После ввода данных в соответствующих полях на странице модуля https://ru.archivarix.com/restore/ он делает скриншот архивного сайта и обращается к API Веб Архива с запросом списка файлов, содержащихся на указанную дату восстановления.
Получив ответ на запрос, система формирует письмо с анализом полученных данных. Пользователю остается только нажать кнопку подтверждения в полученном письме и тогда процесс скачивания сайта начнется.
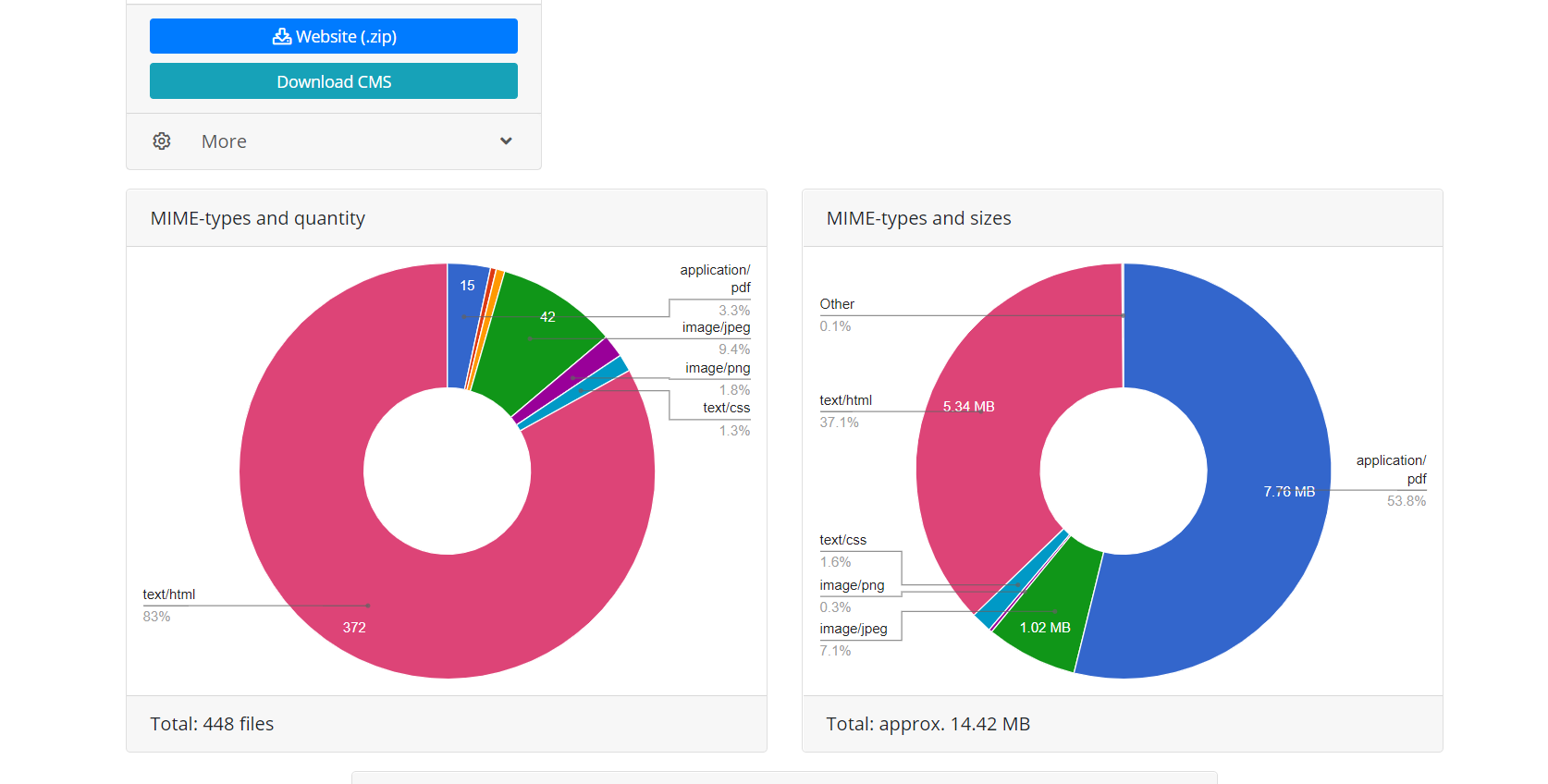
Работа через API Веб Архива дает два преимущества перед скачиванием «в лоб» когда скрипт просто переходит по ссылкам сайта. Во-первых, сразу известны все файлы этого восстановления, можно оценить объем сайта и время, необходимое для его загрузки. Из-за особенностей работы Веб Архива, а он порой работает очень нестабильно, возможны разрывы соединения или неполная загрузка файлов, поэтому алгоритм модуля постоянно проверяет целостность полученных файлов и в подобных случаях пытается докачать контент повторно соединяясь с сервером Веб Архива. Во-вторых, из-за особенностей индексации сайтов Веб Архивом, не на все файлы сайта могут существовать прямые ссылки, а значит при попытке скачать сайт просто следуя по ссылкам они будут недоступны. Поэтому восстановление через API Веб Архива, которое использует Архиварикс, дает возможность восстановить максимально возможное количество контента архивного сайта за указанную дату.
Завершив работу, модуль скачивания из Веб Архива передает данные модулю обработки. Он формирует из полученных файлов сайт, пригодный для установки на Apache или Nginx сервер. Работа сайта основана на использовании SQLite базы данных, так что для начала работы требуется просто загрузить его на ваш сервер, ни каких установок дополнительных модулей, MySQL баз данных и создания пользователей не требуется. Модуль обработки осуществляет оптимизацию собранного сайта, она включает в себя оптимизацию изображений, а так же сжатие CSS и JS. Это может дать существенное увеличение скорости загрузки восстановленного сайта, по сравнению с оригинальным. Скорость загрузки некоторых неоптимизированных Wordpress сайтов с кучей плагинов и с несжатыми медиафайлами, после обработки этим модулем может возрасти многократно. Но, конечно, если сайт был оптимизирован изначально, большого прироста скорости загрузки это не даст.
Удаление рекламы, счетчиков и аналитики модуль обработки осуществляет путем проверки полученных файлов по обширной базе рекламных провайдеров и сборщиков аналитики. Удаление внешних ссылок и кликабельных контактов происходит просто по сигнатуре этого кода. В целом, очистка сайта от «следов предыдущего владельца» алгоритм проводит довольно эффективно, хотя порой это не исключает необходимость чего-либо подправить вручную. К примеру, самописный Java скрипт перенаправляющий, при определенных условиях, пользователей сайта на некую площадку монетизации, алгоритмом обнаружен не будет. Также порой необходимо добавить отсутствующие картинки либо удалить ненужный мусор, на подобие заспамленной гостевой книги. Поэтому возникает необходимость в редакторе полученного сайта. И он есть – это Archivarix CMS.
Это простая и компактная CMS, предназначенная для редактирования сайтов, созданных системой Архиварикс. Она дает возможность осуществлять поиск и замену кода по всему сайту с использованием регулярных выражений, редактирование контента в WYSIWYG редакторе, добавление новых страниц и файлов. Archivarix CMS может работать совместно с любой другой CMS на одном сайте.
Теперь опишем другой модуль системы – скачивание существующих сайтов. В отличие от модуля скачивания сайтов из Веб Архива, тут предугадать сколько и каких файлов надо скачать не получится, поэтому сервера модуля работают совершенно иначе. Паук сервера просто переходит по всем ссылкам, которые находятся на скачиваемом сайте. Для того чтобы скрипт не попал в бесконечный цикл скачки какой-нибудь автогенерируемой страницы максимальная глубина ссылок ограничена десятью кликами. А максимальное количество файлов, которые могут быть скачены с сайта должно быть указано заранее.
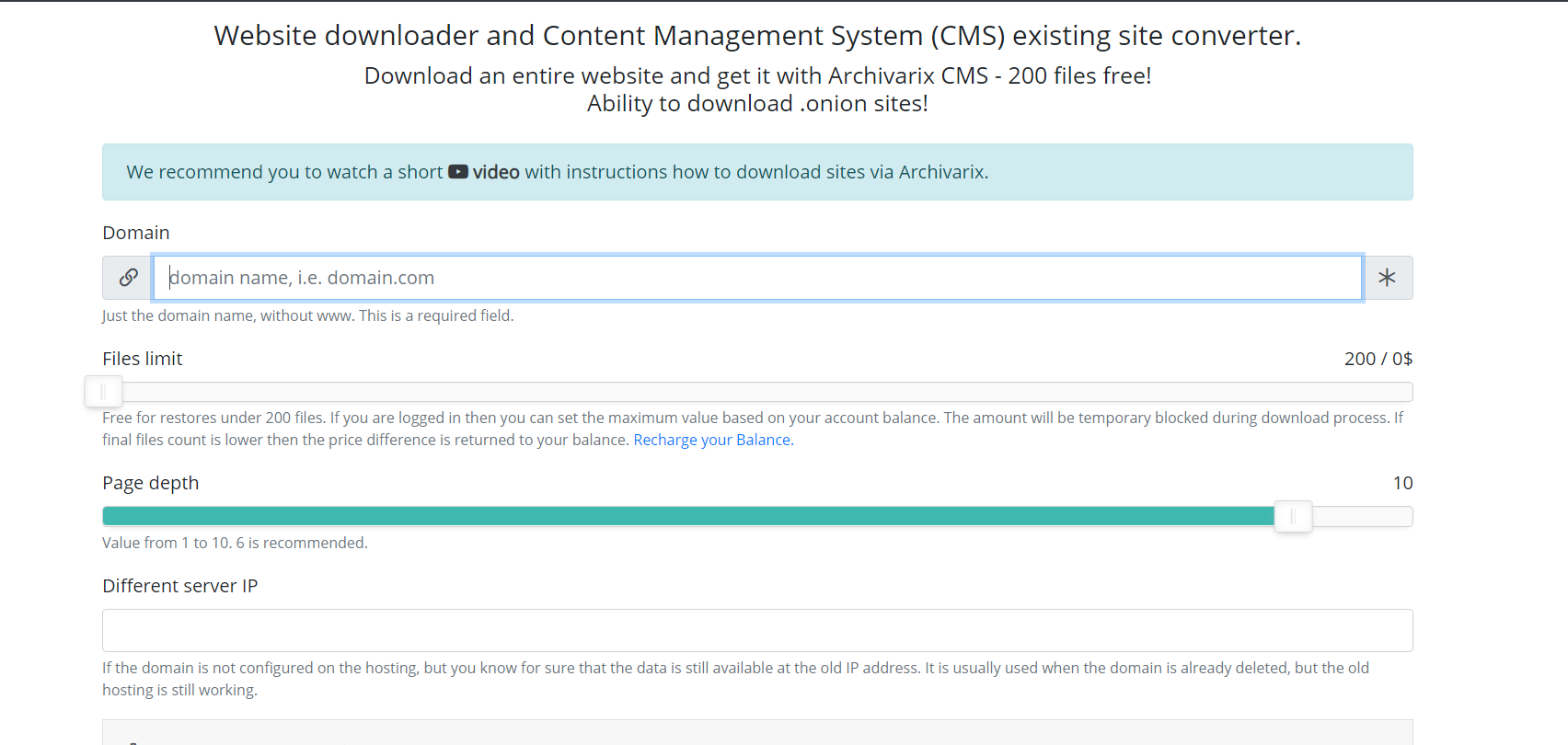
Для наиболее полного выкачивания именно того контента, который вам необходим придумано несколько фишек этого модуля. Можно выбрать различный User-Agent пауку сервиса – к примеру Chrome Desktop или Googlebot. Реферер для обхода клоакинга – если надо скачать именно то, что видит пользователь, зашедший из поиска, можно установить реферер Гугла, Яндекса или другого сайта. Для защиты от бана по IP можно выбрать скачивание сайта с использованием сети Tor, при этом IP паука сервиса меняется случайным образом в рамках этой сети. Остальные параметры, как, к примеру, оптимизация картинок, чистка рекламы и аналитики аналогичны параметрам модуля скачивания из Веб Архива.
После завершения скачивания сайта контент предается модулю обработки. Его работа в этом месте полностью аналогична работе со скаченным из Веб Архива сайтом, описанным выше.
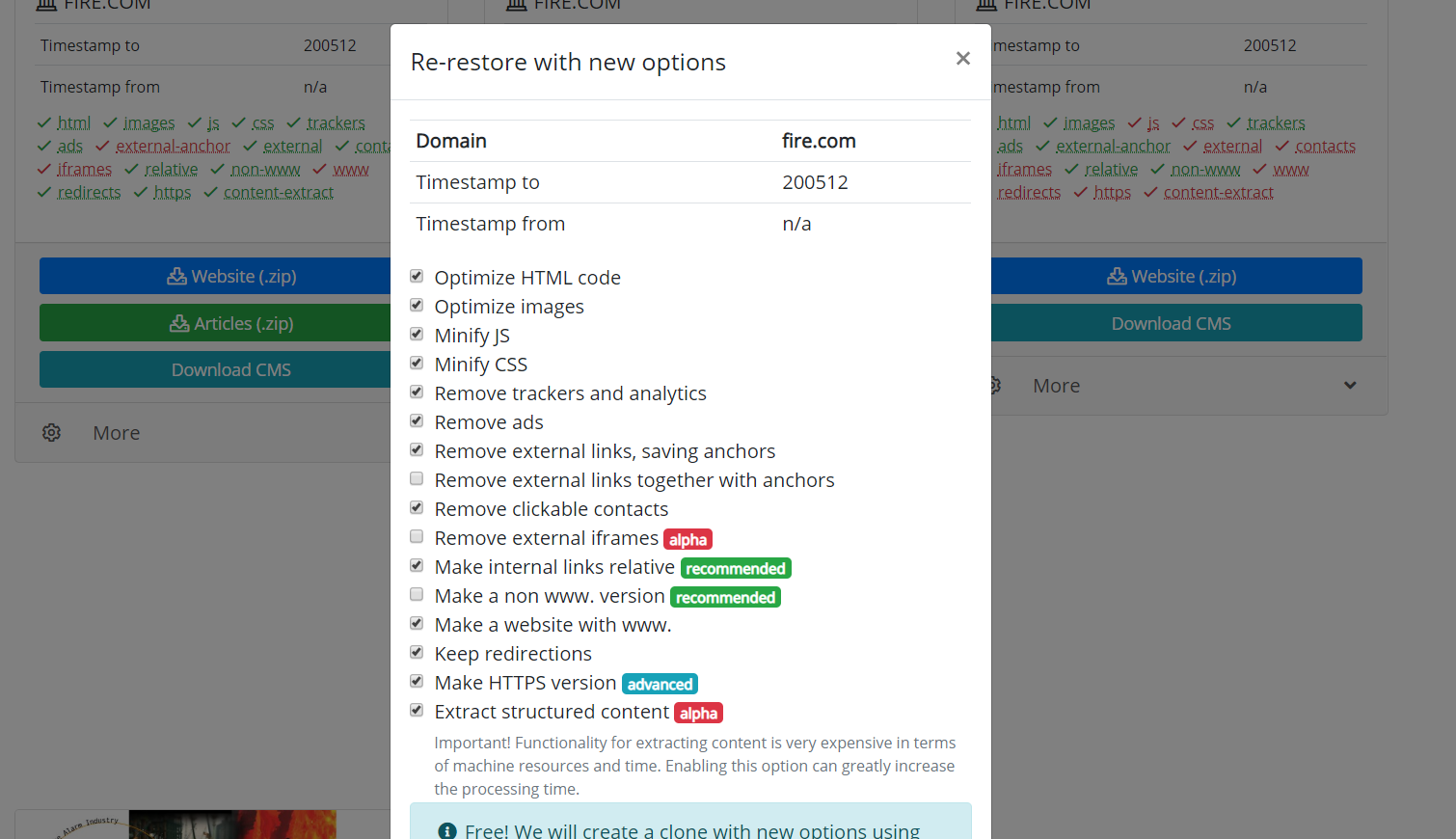
Еще стоит упомянуть возможность сознания клонов восстановленного либо скаченного сайта. Иногда случается, что при восстановлении были выбраны не те параметры, которые оказались в итоге полезны. Например удаление внешних ссылок было излишним, и некоторые внешние ссылки вам оказались нужны, то не надо запускать скачивание снова. Достаточно на странице вашего восстановления задать новые параметры и запустить пересоздание сайта.
Использование материалов статьи разрешается только при условии размещения ссылки на источник: https://archivarix.com/ru/blog/how-does-it-works/

Система Архиварикс предназначена для скачивания и восстановления сайтов - как уже не работающих из Веб Архива, так и живых, находящихся в данный момент онлайн. В этом заключается ее основное отличие о…
С помошью параметра "Извлечение структурированного контента" можно очень просто сделать Wordpress блог как из сайта, найденного в Веб Архиве, так и из любого другого сайта. Для этого находим сайт-исто…
Для того, чтобы вам было удобно редактировать восстановленные в нашей системе сайты, мы разработали простую Flat File CMS состоящую всего из одного небольшого файла. Не смотря на свой размер, эта CMS …
В данной статье содержаться регулярные выражения, применяемые для поиска и замены в контенте сайтов, восстановленных с помощью системы Archivarix. Они не являются чем-то свойственным только этой систе…
Наша система скачивания сайтов и конвертации их на нашу Archivarix CMS позволяет бесплатно скачивать до 200 файлов с сайта. Если на сайте файлов больше и все они нужны, то за эту услугу вы можете запл…